📌 Spring Boot는 JPA 설정을 자동으로 구성해 주어 JPA를 쉽게 사용할 수 있도록 도와준다.기본적으로 필요한 EntityManagerFactory와 TransactionManager를 자동으로 설정하고 데이터베이스 관련 설정을 application.properties 파일에서 간단히 지정할 수 있게 해준다.
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// 비영속
Tutor tutor = new Tutor(1L, "wonuk", 100);
System.out.println("persist 전");
// 영속
em.persist(tutor);
System.out.println("persist 후");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
기존의 방식이다.
직접 트랜잭션을 사용한다.(JPA는 기본적으로 하나의 트랜잭션 안에서 기능을 수행한다)
직접 EntityManagerFactory 와 EntityManager 를 생성하여 사용한다.
직접 close() 하여 연결을 종료 해야한다.
Spring Boot와 JPA
JPA는 Spring에 종속적인 것이 아니다.
Spring Boot 에서 JPA를 사용하기 위해서는 build.gradle에 의존성 추가가 필요하다.
spring-boot-starter-data-jpa
필요한 JPA 설정과 Entity 관리를 자동으로 해준다.
자동으로 내부에서 EntityManagerFactory 를 하나만 생성해서 관리(싱글톤)한다.
자동으로 Bean으로 등록된다.
직접 만들지 않아도 된다.
직접 연결을 close() 하지 않아도 된다.
application.properties 에 설정된 DB 정보로 생성된다.
@PersistenceContext를 통해 자동으로 생성된 EntityManager를 주입받아 사용할 수 있다.
@Repository
public class TutorRepository {
@PersistenceContext
private EntityManager em;
public void save(Tutor tutor) {
em.persist(tutor);
}
public Tutor findById(Long id) {
return em.find(Tutor.class, id);
}
public List<Tutor> findAll() {
return em.createQuery("SELECT * FROM tutor", Tutor.class).getResultList();
}
public void delete(Tutor tutor) {
em.remove(tutor);
}
}
EntityManager 는 Spring Data JPA에서 관리하여 직접 관리하지 않아도된다.
Spring Data JPA
📌 Spring Data JPA는 Spring Framework에서 제공하는 모듈로 JPA를 쉽게 사용할 수 있도록 지원한다. 이를 통해 데이터베이스와 상호작용을 간편하게 구현할 수 있고 코드를 간소화할 수 있다.
Spring Data JPA 특징
JPA 추상화 Repository 제공
CrudRepository, JpaRepository 인터페이스를 제공한다.
SQL이나 EntityManager를 직접 호출하지 않아도 기본적인 CRUD 기능을 손쉽게 구현할 수 있다.
JPA 구현체와 통합
일반적으로 Hibernate를 통해 자동으로 SQL이 생성된다.
QueryMethods
Method 이름만으로 SQL을 자동으로 생성한다.
@Query 를 사용하여 JPQL 또는 Native Query를 정의할 수 있다.
복잡한 SQL을 직접 구현할 때 사용
트랜잭션 관리와 LazyLoading
트랜잭션 기능을 Spring과 통합하여 제공한다.
연관된 Entity를 필요할 때 로딩하는 지연로딩 기능을 지원한다.
SimpleJpaRepository
📌 Spring Data JPA의 기본 Repository 구현체로 JpaRepository 인터페이스의 기본 메서드들을 실제로 수행하는 클래스이다. 내부적으로 EntityManager를 사용하여 JPA Entity를 DB에 CRUD 방식으로 저장하고 관리하는 기능을 제공한다.
Spring Data JPA는 JpaRepository 인터페이스를 구현한 클래스를 자동으로 생성한다.
기본적으로 SimpleJpaRepository를 구현체로 사용한다.
public interface MemberRepository extends JpaRepository<Member, Long> {
}
Repository를 interface로 선언한다.
JpaRepository<"@Entity 클래스", "@Id 데이터 타입"> 상속
내부동작
Spring이 실행되면서 JpaRepository 인터페이스를 상속받은 인터페이스가 있다면, 해당 인터페이스의 정보를 토대로 SimpleJpaRepository 를 생성하고 Bean으로 등록한다.
인터페이스의 구현 클래스를 직접 만들지 않아도 JpaRepository 의 기능을 사용할 수 있다.
개발자가 직접 SimpleJpaRepository를 사용하거나 참조할 필요는 없다.
save() : 대상 Entity를 DB 테이블에 저장한다.
findAll() : Entity에 해당하는 테이블의 모든 데이터를 조회한다.
delete() : 대상 Entity를 데이터베이스에서 삭제한다.
이외에도 수많은 기능(Paging, Sorting 등)이 있다.
Query Methods
📌 Spring Data JPA에서 메서드 이름을 기반으로 데이터베이스 쿼리를 자동 생성하는 기능이다. 직접 SQL을 작성하지 않고도 복잡한 쿼리를 쉽게 수행할 수 있게된다.
Spring Data JPA에서 메서드 이름을 기반으로 SQL을 자동으로 생성하는 기능
JpaRepository는 findAll(), save()와 같은 기본적인 기능만 제공한다.
실제 Application 개발에는 상황에 따라 조건에 맞는 메서드가 필요하다.
public interface MemberRepository extends JpaRepository<Member, Long> {
// Query Methods
Member findByNameAndAddress(String name, String address);
}
// 자동으로 생성되어 실제로 실행되는 SQL
SELECT * FROM member WHERE name = ? AND address = ?;
📌 엔티티의 생성 및 수정 시간을 자동으로 관리해주는 기능입니다. 이를 통해 개발자는 엔티티가 언제 생성되고 수정되었는지를 자동으로 추적할 수 있다.
모든 클래스에 생성 시간, 수정 시간 추가
@Entity
public class User {
@Id
private Long id;
private String name;
private String address;
// 생성 시간
private LocalDateTime createdAt;
// 수정 시간
private LocalDateTime updatedAt;
}
@Entity
public class Item {
@Id
private Long id;
private String name;
private String description;
// 생성 시간
private LocalDateTime createdAt;
// 수정 시간
private LocalDateTime updatedAt;
}
모든 Entity가 생성 시간, 수정 시간에 대한 연산을 수행해야 한다.
JPA Auditing은 이러한 불편함을 해결해준다.
개발자는 반복되는 불편함을 참지 않는다.
JPA Auditing 적용예시
@MappedSuperclass
public class BaseEntity{
@Column(updatable = false)
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
@PrePersist
public void prePersist(){
LocalDateTime now = LocalDateTime.now();
created_at = now;
updated_at = now;
}
@PreUpdate
public void preUpdate() {
updated_at = LocalDateTime.now();
}
}
순수 JPA도 Auditing을 사용할 수 있지만 Spring Data JPA에서는 더 쉽게 사용할 수 있다.
Spring Data JPA Auditing Annotation
적용하기
@EnableJpaAuditing
@EnableJpaAuditing
@SpringBootApplication
public class SpringDataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataJpaApplication.class, args);
}
}
Spring Data JPA에서 Auditing을 적용할 때 사용하는 어노테이션
일반적으로 Spring Boot를 실행하는 Application 클래스 상단에 선언한다.
Spring Boot로 만들어진 프로젝트에 기본적으로 생성되는 Application 클래스
IoC (Inversion of Control)와 DI (Dependency Injection)의 개념과 비유
1. IoC (Inversion of Control, 제어의 역전)
개념
IoC는 객체의 생성과 관리를 개발자가 아닌 Spring 컨테이너가 담당하는 설계 원칙입니다.
애플리케이션의 흐름 제어를 개발자가 아닌 **프레임워크(Spring)**가 제어하게 합니다.
비유
비유: 요리사가 아닌 **주방장(매니저)**가 모든 요리사를 관리하는 상황.
기존 방식: 요리사가 직접 재료를 구입하고 요리를 만들며 모든 과정을 제어.
IoC 방식: 주방장이 재료를 준비해주고 요리사에게 요리를 맡기는 방식. 요리사는 재료 준비에 신경 쓸 필요 없이 요리에만 집중.
2. DI (Dependency Injection, 의존성 주입)
개념
DI는 객체가 필요로 하는 의존성을 객체 내부에서 직접 생성하지 않고, 외부에서 주입해주는 방식입니다.
IoC의 구현 방법 중 하나로, 객체 간의 결합도를 낮추고 유연성을 높입니다.
비유
비유: 요리사가 재료를 직접 준비하지 않고 **매니저(주방장)**가 필요한 재료를 가져다 주는 상황.
기존 방식: 요리사가 요리마다 필요한 재료를 직접 슈퍼마켓에서 사와야 함.
DI 방식: 매니저가 요리사가 요청한 재료를 준비해 전달. 요리사는 요리(비즈니스 로직)에만 집중.
3. IoC와 DI를 연결하는 비유
비유 상황
레스토랑 시스템:
IoC:
주방장이 전체 흐름을 제어(객체 생성, 관리).
요리사(객체)는 주방장(Spring 컨테이너)에 의해 관리됨.
DI:
주방장이 요리사가 필요한 재료(의존성)를 제공(주입).
4. 예제 코드
IoC와 DI 적용 전 (전통적인 방식)
public class Chef {
private Ingredient ingredient;
public Chef() {
this.ingredient = new Ingredient(); // 요리사가 직접 재료를 생성
}
public void cook() {
System.out.println("Cooking with " + ingredient.getName());
}
}
public class Ingredient {
public String getName() {
return "Tomatoes";
}
}
문제점:
Chef 클래스가 Ingredient 클래스를 직접 생성(강한 결합).
Ingredient를 변경하려면 Chef도 수정해야 함.
IoC와 DI 적용 후
public class Chef {
private Ingredient ingredient;
// 의존성 주입 (DI)
public Chef(Ingredient ingredient) {
this.ingredient = ingredient;
}
public void cook() {
System.out.println("Cooking with " + ingredient.getName());
}
}
public class Ingredient {
public String getName() {
return "Tomatoes";
}
}
// Spring Configuration
@Configuration
public class AppConfig {
@Bean
public Ingredient ingredient() {
return new Ingredient(); // 의존성 생성
}
@Bean
public Chef chef(Ingredient ingredient) {
return new Chef(ingredient); // 의존성 주입
}
}
장점:
Chef 클래스는 Ingredient에 대해 아무것도 몰라도 됨.
Ingredient를 변경해도 Chef 클래스는 수정할 필요가 없음(유연성 증가).
5. IoC와 DI 요약
개념
설명
비유
IoC
객체의 생성 및 생명주기 관리를 개발자가 아닌 Spring 컨테이너가 담당.
주방장이 전체 요리 과정을 관리하고 제어.
DI
객체가 필요한 의존성을 외부에서 주입받아 사용.
주방장이 요리사가 필요한 재료를 전달. 요리사는 요리에만 집중.
IoC + DI 결합
IoC로 객체를 관리하고, DI로 객체 간 의존성을 주입하여 객체 간 결합도를 낮춤.
주방장이 요리사(객체)를 관리하고, 필요한 재료(의존성)를 전달하여 효율적으로 관리.
6. 결론
IoC는 **"객체의 제어권을 개발자가 아닌 Spring 컨테이너에 위임"**하는 철학.
DI는 **"객체 간의 의존성을 외부에서 주입"**하여 유연성과 테스트 용이성을 높이는 구현 방식.
Spring은 IoC 컨테이너와 DI를 사용해 객체 생성을 관리하고, 의존성을 주입하여 효율적이고 유연한 애플리케이션 설계를 가능하게 합니다! 😊
Spring AOP는 **Aspect-Oriented Programming(AOP)**의 개념을 Spring Framework에 적용한 구현체로, **횡단 관심사(Cross-Cutting Concerns)**[ 여러 곳에서 공통적으로 필요한 기능 ]를 깔끔하게 관리하고, 핵심 비즈니스 로직과 보조 로직을 분리할 수 있게 도와줍니다.
= AOP란 공통 기능을 한 곳에 정의하고 필요한 코드에 자동으로 적용하는 방법
Spring AOP는 프록시(Proxy) 기반으로 동작하며, 주로 메서드 실행에 Advice를 적용합니다.
스프링 컨테이너가 **스프링 빈(Spring Bean)**을 관리한다는 것은 빈의 생성, 초기화, 의존성 주입, 스코프 관리, 그리고 소멸까지의 전체 생명 주기를 관리한다는 것을 의미합니다. 관리 과정은 다음과 같은 방식으로 이루어집니다.
1. 스프링 빈의 관리 과정 (생명 주기)
스프링 컨테이너가 스프링 빈을 관리하는 과정은 다음 단계를 따릅니다:
1) 빈 정의 (Bean Definition):
개발자는 어노테이션(@Component, @Service, @Controller 등)이나 XML/Java 설정 파일을 통해 빈을 정의합니다.
스프링 컨테이너는 애플리케이션 시작 시 이 정의를 읽어들여 빈 생성 규칙을 설정합니다.
2) 빈 생성 (Bean Creation):
스프링 컨테이너는 빈 정의에 따라 빈 객체를 생성합니다.
기본적으로 **싱글톤(Singleton)**으로 관리되며, 애플리케이션 컨텍스트 초기화 시 생성됩니다.
3) 의존성 주입 (Dependency Injection):
빈이 생성된 후, 스프링 컨테이너는 해당 빈이 필요로 하는 의존성을 주입합니다.
생성자 주입, 세터 주입, 필드 주입 중 하나의 방식으로 주입됩니다.
예: @Autowired, @Value, @Qualifier 등을 사용.
4) 초기화 (Initialization):
빈 생성 후 초기화 메서드(예: @PostConstruct 또는 init-method)를 호출하여 필요한 설정을 수행합니다.
개발자가 정의한 초기화 로직이 실행됩니다.
5) 사용 (Usage):
빈은 애플리케이션 내에서 사용되며, 컨테이너가 이를 제공하고 호출하는 역할을 합니다.
6) 소멸 (Destruction):
애플리케이션 종료 시, 컨테이너는 빈을 제거하기 전에 소멸 메서드(예: @PreDestroy 또는 destroy-method)를 호출합니다.
2. 스프링 빈의 관리 요소
1) 빈 스코프 관리
스프링 빈은 **스코프(Scope)**를 통해 객체의 생명 주기를 정의합니다. 빈의 스코프는 객체가 생성되고 유지되는 범위를 의미합니다.
싱글톤(Singleton):
컨테이너 당 하나의 인스턴스만 생성 (기본값).
모든 요청에서 같은 객체를 공유합니다.
프로토타입(Prototype):
요청할 때마다 새로운 객체 생성.
요청(Request):
웹 애플리케이션에서 HTTP 요청마다 새로운 빈 생성.
세션(Session):
웹 애플리케이션에서 HTTP 세션마다 새로운 빈 생성.
2) 의존성 관리
스프링 컨테이너는 빈이 필요로 하는 의존성을 자동으로 관리하고 주입합니다.
예제: 생성자 주입
@Component
class NotificationService {
private final MessageService messageService;
@Autowired
public NotificationService(MessageService messageService) {
this.messageService = messageService; // 의존성 주입
}
public void notify(String message) {
messageService.sendMessage(message);
}
}
예제: 세터 주입
@Component
class NotificationService {
private MessageService messageService;
@Autowired
public void setMessageService(MessageService messageService) {
this.messageService = messageService; // 의존성 주입
}
public void notify(String message) {
messageService.sendMessage(message);
}
}
3. 코드 예제로 이해
스프링 빈의 생명 주기
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
@Component
class ExampleBean implements InitializingBean, DisposableBean {
// 빈 생성자
public ExampleBean() {
System.out.println("1. 빈 생성");
}
// 의존성 주입 후 호출
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("2. 빈 초기화");
}
// 빈 소멸 전 호출
@Override
public void destroy() throws Exception {
System.out.println("3. 빈 소멸");
}
}
// 메인 클래스
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Main {
public static void main(String[] args) {
// 컨테이너 생성 및 빈 관리 시작
var context = new AnnotationConfigApplicationContext(AppConfig.class);
// ExampleBean 사용
ExampleBean exampleBean = context.getBean(ExampleBean.class);
// 컨테이너 종료 및 빈 소멸
context.close();
}
}
실행 결과:
1. 빈 생성
2. 빈 초기화
3. 빈 소멸
4. 일상적인 비유
스프링 컨테이너와 빈 관리의 비유
스프링 컨테이너: 레스토랑의 매니저
메뉴와 재료를 정의하고, 주방에서 요리가 준비되도록 관리.
각 요리(빈)를 주문받아 제공.
스프링 빈: 레스토랑의 요리
매니저가 주방에서 요리를 준비하고, 고객이 주문하면 제공합니다.
요청마다 같은 요리를 재사용할 수도 있고(싱글톤), 매번 새롭게 준비할 수도 있습니다(프로토타입).
5. 정리 표
스프링 컨테이너
스프링 빈
정의
객체(스프링 빈)의 생성, 초기화, 의존성 주입, 생명 주기를 관리하는 도구.
스프링 컨테이너에 의해 관리되는 객체.
역할
빈 생성, 의존성 주입, 스코프 관리, 생명 주기 관리.
실제 애플리케이션에서 사용되는 객체.
생성 시점
애플리케이션 시작 시 초기화 (스프링 컨테이너 초기화).
스프링 컨테이너에 의해 정의된 설정에 따라 생성.
소멸 시점
애플리케이션 종료 시 빈 소멸.
빈의 소멸 메서드 호출 후 컨테이너에서 제거.
관리 범위
애플리케이션 전체의 객체 관리.
개별 빈 단위 관리.
스코프
싱글톤, 프로토타입, 요청, 세션 등 관리.
컨테이너의 설정에 따라 하나의 객체 또는 여러 객체로 생성.
6. 결론
스프링 컨테이너는 빈의 생성부터 소멸까지 전체 생명 주기를 관리하며, 개발자는 객체 생성과 의존성 설정에 대한 걱정을 줄이고 비즈니스 로직에 집중할 수 있습니다.
스프링 빈은 컨테이너에서 관리되는 객체로, 요청에 따라 필요한 의존성을 주입받고, 컨테이너의 설정에 따라 재사용되거나 새로 생성됩니다.
스프링의 이러한 관리 방식은 객체 간 결합도를 줄이고, 코드의 유연성과 유지보수성을 높이는 데 큰 역할을 합니다.
3. 스프링 컨테이너와 스프링 빈의 관계
스프링 컨테이너는 스프링 빈을 관리하는 도구입니다.
개발자는 스프링 컨테이너에 객체(빈)를 등록하고, 컨테이너는 이 빈을 생성하고 관리합니다.
스프링 컨테이너는 애플리케이션 실행 시 빈을 생성하고, 의존성을 주입하며, 생명 주기를 관리합니다.
4. 일상적인 예시
1) 스프링 컨테이너와 스프링 빈
스프링 컨테이너: **관리인(컨테이너)**이 빵집의 모든 직원과 재료를 관리.
스프링 빈: 관리인이 관리하는 **직원(객체)**과 재료(의존성).
비유
빵집의 모든 직원은 관리인의 관리하에 빵을 만듭니다.
직원들 간의 의존성(예: 반죽 -> 오븐 -> 포장)은 관리인이 연결해줍니다.
관리인이 직원의 고용, 교체, 해고(생명 주기)를 관리합니다.
5. 코드 예제
1) 스프링 컨테이너와 빈 등록
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.stereotype.Component;
// 메시지 서비스 인터페이스
interface MessageService {
void sendMessage(String message);
}
// EmailService 구현체
@Component
class EmailService implements MessageService {
public void sendMessage(String message) {
System.out.println("Sending Email: " + message);
}
}
// NotificationService 클래스
@Component
class NotificationService {
private final MessageService messageService;
// 생성자를 통한 의존성 주입
public NotificationService(MessageService messageService) {
this.messageService = messageService;
}
public void notify(String message) {
messageService.sendMessage(message);
}
}
// 스프링 설정 클래스
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan(basePackages = "com.example")
class AppConfig {
}
// Main 클래스
public class Main {
public static void main(String[] args) {
// 스프링 컨테이너 생성
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
// 스프링 컨테이너에서 NotificationService 빈 가져오기
NotificationService notificationService = context.getBean(NotificationService.class);
notificationService.notify("Hello, Spring!");
}
}
Spring Boot는 application.properties 또는 application.yml 파일을 사용해 간단하게 애플리케이션의 설정을 관리할 수 있습니다.
서버의 자동 실행
내장 웹 서버를 통해 별도의 설정 없이, 애플리케이션을 java -jar 명령어로 실행할 수 있습니다.
개발자 친화적인 환경
Spring Boot는 애플리케이션의 개발과 디버깅을 빠르게 할 수 있도록DevTools라는 기능을 제공하며, 코드 변경 시 자동으로 애플리케이션을 재시작하여 개발 편의성을 제공합니다.
[2] Spring Boot의 장점
빠른 시작:
Spring Boot는 자동 설정 및 기본적인 템플릿을 제공하여, 애플리케이션을 몇 가지 설정만으로 빠르게 시작할 수 있습니다. @SpringBootApplication 어노테이션을 추가하면, 기본적인 설정이 자동으로 이루어지고, 애플리케이션을 실행할 수 있는 상태가 됩니다.
설정 최소화:
Spring Boot는 많은 설정을 자동으로 처리하므로 개발자는 비즈니스 로직에만 집중할 수 있습니다. 예를 들어, 데이터베이스 설정, 서버 설정등 대부분의 설정을 자동으로 처리하여 개발자가 별도로 신경 쓸 필요가 없습니다.
내장 서버:
내장 서버를 제공하여 별도의 외부 웹 서버(Tomcat, Jetty 등이 내장되어 있다.)를 설치할 필요 없이 바로 실행할 수 있습니다. 이는 애플리케이션의 배포를 간소화하고, 실행 파일 하나로 애플리케이션을 배포할 수 있게 만듭니다.
생산성 향상:
Spring Boot는 개발자가 빠르게 단독으로 실행할 수 있는 애플리케이션을 작성하고 실행할 수 있도록 돕기 위해 많은스타터 의존성을 제공합니다. 예를 들어, 웹 애플리케이션을 만들기 위한 spring-boot-starter-web, 데이터베이스 연동을 위한 spring-boot-starter-data-jpa 등이 있습니다.
DevTools:
Spring Boot는 개발 중에자동 재시작및Hot swapping을 지원하여, 개발자가 코드 수정 후 애플리케이션을 다시 시작하지 않고도 변경 사항을 바로 반영할 수 있도록 돕습니다.
[?] 특징, 장점은 여러개가 있지만 결국 왜 스프링을 사용할까?
= 자바의 가장 큰 특징은 객체 지향이다.스프링은 좋은 객체 지향 애플리케이션 개발을 도와주는 프레임워크다.
[3] Spring Boot 애플리케이션 구조
애플리케이션 클래스
@SpringBootApplication 어노테이션이 붙은 클래스는 Spring Boot 애플리케이션의 진입점입니다. 이 클래스는 자동으로 필요한 설정을 수행하고 애플리케이션을 실행합니다.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
자동 설정:
Spring Boot는 애플리케이션을 실행할 때, 주어진 환경에 맞춰 자동으로 설정을 적용합니다. 예를 들어, 데이터베이스가 설정되면 자동으로 DataSource와 관련된 설정이 적용됩니다.
프로퍼티 파일:
Spring Boot는 application.properties 또는 application.yml 파일을 통해 애플리케이션의 설정을 관리할 수 있습니다. 데이터베이스 연결 정보, 서버 포트, 로깅 수준 등 다양한 설정을 이 파일에서 처리합니다.
내장 서버:
Spring Boot는 기본적으로 내장된 Tomcat 서버를 포함하고 있으며, 설정에 따라 다른 내장 서버(Undertow, Jetty 등)를 사용할 수 있습니다.
[4] Spring Boot 애플리케이션 실행
Maven 또는 Gradle을 사용한 빌드 후 실행:
애플리케이션을 빌드하고 실행하려면, mvn spring-boot:run 또는 gradle bootRun 명령을 사용할 수 있습니다.
JAR 파일로 실행:
Spring Boot 애플리케이션을 JAR 파일로 빌드한 후, java -jar 명령어로 실행할 수 있습니다.
java -jar myapp.jar
[5] Spring Boot 사용 예시
간단한 RESTful 웹 서비스:
@RestController
@RequestMapping("/api")
public class HelloController {
@GetMapping("/hello")
public String hello() {
return "Hello, World!";
}
}
자동 설정 예시: Spring Boot는 데이터베이스 연결을 자동으로 처리할 수 있습니다. 예를 들어, 데이터베이스 설정을 application.properties에서 지정하면, Spring Boot는 이를 자동으로 인식하고 설정을 완료합니다.
스프링은 DefaultConversionService를 통해 다양한 타입 변환을 기본 제공하며, 이를 직접 사용할 수 있습니다.
import org.springframework.core.convert.support.DefaultConversionService;
import org.springframework.core.convert.ConversionService;
public class Main {
public static void main(String[] args) {
// DefaultConversionService 생성
ConversionService conversionService = new DefaultConversionService();
// 기본 변환 사용
int convertedInt = conversionService.convert("123", Integer.class);
boolean convertedBool = conversionService.convert("true", Boolean.class);
// 결과 출력
System.out.println("Converted Integer: " + convertedInt); // 123
System.out.println("Converted Boolean: " + convertedBool); // true
}
}
2) 커스텀 변환기 등록
1. 커스텀 변환기 작성
import org.springframework.core.convert.converter.Converter;
// String -> CustomType 변환기
public class StringToCustomTypeConverter implements Converter<String, CustomType> {
@Override
public CustomType convert(String source) {
return new CustomType(source);
}
}
// CustomType 클래스
public class CustomType {
private final String value;
public CustomType(String value) {
this.value = value;
}
public String getValue() {
return value;
}
}
2. Custom ConversionService 설정
import org.springframework.core.convert.support.GenericConversionService;
public class Main {
public static void main(String[] args) {
// ConversionService 생성
GenericConversionService conversionService = new GenericConversionService();
// 커스텀 변환기 등록
conversionService.addConverter(new StringToCustomTypeConverter());
// 변환 수행
CustomType customType = conversionService.convert("test-value", CustomType.class);
// 결과 출력
System.out.println("Converted CustomType Value: " + customType.getValue());
}
}
4. ConversionService와 FormatterRegistry
**ConversionService**는 변환기(Converter)를 관리하며, 타입 변환을 처리합니다.
**FormatterRegistry**는 포맷터(Formatter)를 지원하며, ConversionService의 확장된 형태로 볼 수 있습니다.
WebMvcConfigurer에서 FormatterRegistry를 사용하여 변환기나 포맷터를 등록할 수 있습니다.
변환기 등록
import org.springframework.context.annotation.Configuration;
import org.springframework.format.FormatterRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addFormatters(FormatterRegistry registry) {
registry.addConverter(new StringToCustomTypeConverter());
}
}
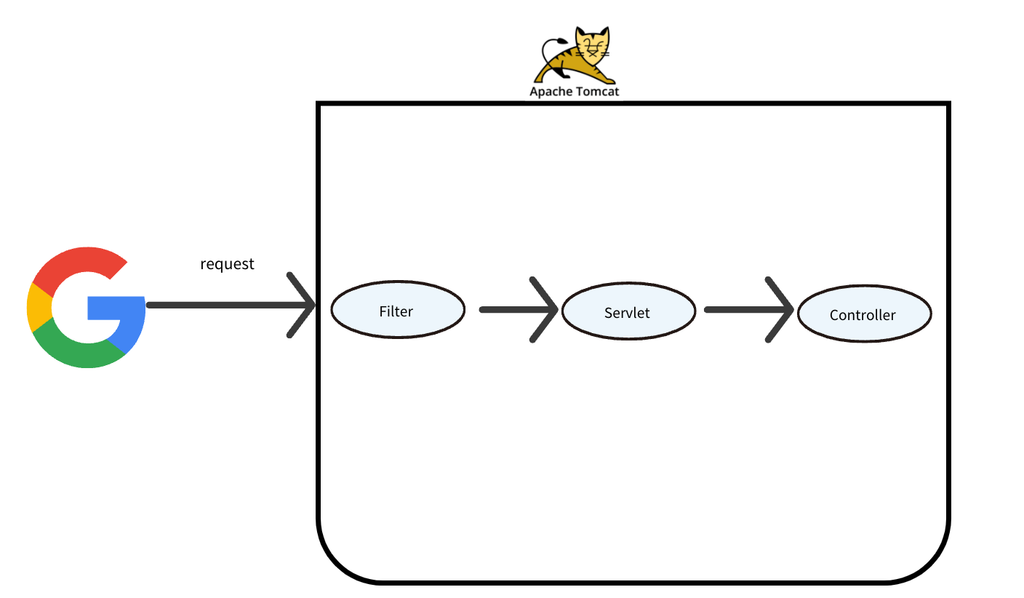
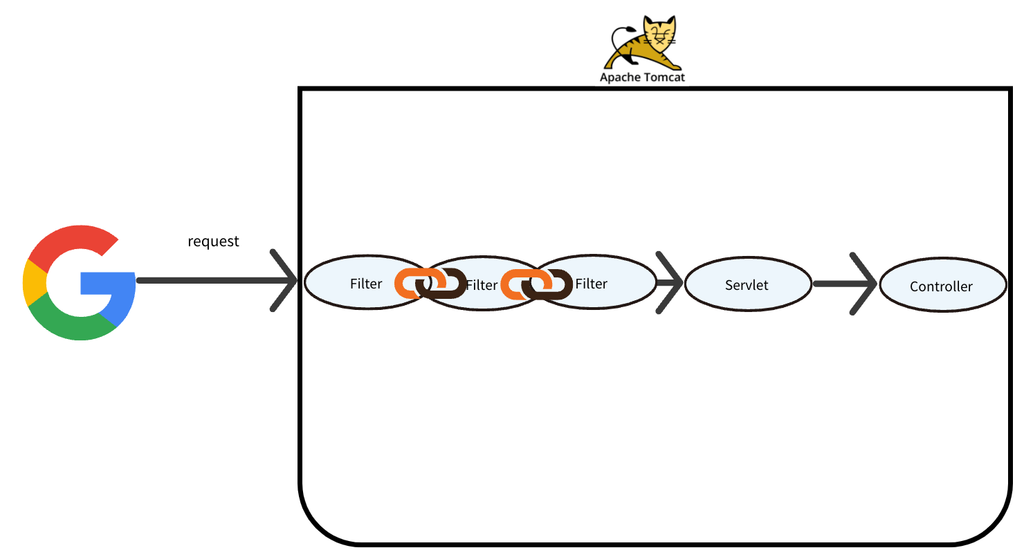
**필터(Filter)**는 클라이언트의 요청(request)와 서버의 응답(response) 사이에서 요청 처리 전/후에 특정 작업을 수행할 수 있는 기능을 제공합니다. 필터는 주로 HTTP 요청과 응답을 가로채어 조작하거나, 요청이 컨트롤러에 도달하기 전에 사전 작업을 수행하는 데 사용됩니다.
2. 필터의 주요 사용 사례
인증 및 권한 검사:
요청이 적합한 사용자로부터 왔는지 확인하거나, 요청의 권한을 검증.
로깅 및 모니터링:
요청 및 응답 데이터를 기록하여 애플리케이션의 동작을 추적.
데이터 변환/압축:
요청 데이터 변환 또는 응답 데이터 압축.
CORS 처리:
Cross-Origin Resource Sharing(CORS) 요청 처리.
보안 작업:
CSRF(Cross-Site Request Forgery) 방지 토큰 검증, 헤더 조작 방지 등.
스프링이 제공하는 Filter 인터페이스는 서블릿 표준(javax.servlet.Filter)을 확장한 것입니다.
전역적으로 동작:
컨트롤러에 도달하기 전에 모든 요청/응답에 대해 동작합니다.
체인 방식:
여러 필터가 등록되어 있는 경우, 필터 체인(Filter Chain)을 통해 순서대로 실행됩니다.
4. 필터 구현 방법
1) 기본 필터 구현
javax.servlet.Filter 인터페이스를 구현하여 필터를 작성합니다.
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
// 모든 요청에 대해 필터 적용
@WebFilter("/*")
public class LoggingFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 초기화 작업 (필요 시 구현)
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
// 요청 처리 전
System.out.println("Request received at: " + request.getRemoteAddr());
// 다음 필터 또는 서블릿 호출
chain.doFilter(request, response);
// 응답 처리 후
System.out.println("Response processed");
}
@Override
public void destroy() {
// 리소스 해제 작업 (필요 시 구현)
}
}
doFilter 메서드:
요청이 컨트롤러로 전달되기 전, 특정 작업을 수행합니다.
chain.doFilter(request, response)를 호출하여 다음 필터 또는 서블릿으로 요청을 전달합니다.
chain.doFilter 이후 코드는 응답이 생성된 후 실행됩니다.
2) 스프링 부트에서 필터 등록
스프링 부트에서는 @Bean을 사용해 필터를 등록할 수 있습니다.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Filter;
@Configuration
public class FilterConfig {
@Bean
public Filter loggingFilter() {
return new LoggingFilter();
}
}
5. 필터 체인(Filter Chain)
필터는 여러 개 등록될 수 있으며, 등록 순서에 따라 체인 방식으로 동작합니다.
필터가 호출될 때, FilterChain을 통해 다음 필터로 요청을 전달합니다.
최종적으로 컨트롤러나 서블릿에 도달하며, 응답은 필터 체인을 역순으로 통과합니다.
6. 필터의 실행 순서 지정
스프링 부트에서는 @Order 또는 FilterRegistrationBean을 사용해 필터의 실행 순서를 지정할 수 있습니다.
1) @Order로 순서 지정
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
@Component
@Order(1) // 낮은 숫자가 먼저 실행됨
public class FirstFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("First Filter - Before");
chain.doFilter(request, response);
System.out.println("First Filter - After");
}
}
2) FilterRegistrationBean으로 순서 지정
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FilterConfig {
@Bean
public FilterRegistrationBean<LoggingFilter> loggingFilter() {
FilterRegistrationBean<LoggingFilter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new LoggingFilter());
registrationBean.setOrder(2); // 순서 지정 (낮은 숫자가 먼저 실행)
registrationBean.addUrlPatterns("/*"); // 필터를 적용할 URL 패턴
return registrationBean;
}
}
@Bean
public FilterRegistrationBean<JwtAuthFilter> jwtAuthFilter() {
FilterRegistrationBean<JwtAuthFilter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new JwtAuthFilter());
registrationBean.addUrlPatterns("/secure/*"); // 특정 URL 패턴에만 적용
registrationBean.setOrder(1);
return registrationBean;
}
8. 정리
항목
설명
정의
클라이언트 요청과 서버 응답 사이에서 특정 작업을 수행하는 기능.
주요 사용 사례
인증/권한, 로깅, 요청/응답 데이터 변환, CORS 처리, 보안 검사.
동작 방식
요청 → 필터 체인 → 컨트롤러 → 응답 (필터 체인 역순으로 실행).
등록 방법
1. @WebFilter2. FilterRegistrationBean3. @Bean.
순서 지정 방법
@Order 또는 FilterRegistrationBean의 setOrder 메서드.
장점
전역적으로 요청/응답 처리 가능, 공통 로직 분리, 강력한 조작 기능 제공.
단점
컨트롤러 단위로 작동하지 않으므로 세부 로직 구현 시 코드가 복잡해질 수 있음.
9. 결론
필터는 HTTP 요청과 응답을 처리하는 강력한 전처리/후처리 메커니즘으로, 인증, 로깅, 데이터 조작 등 다양한 작업을 수행할 수 있습니다. 스프링 부트에서는 간단한 설정으로 필터를 등록하고, 순서를 지정하여 유연하게 요청/응답 처리를 관리할 수 있습니다. 필터는 전역적으로 동작하기 때문에, 컨트롤러 단위보다 요청 흐름의 초기 단계에서 작업을 수행할 때 적합합니다.
API 예외처리
API 예외처리는 클라이언트와 서버 간의 상호작용 중 발생할 수 있는 오류를 처리하고, 클라이언트에 일관된 오류 응답을 제공하기 위한 방법입니다.
1. API 예외처리의 목표
일관성:
클라이언트가 API의 오류를 쉽게 이해하고 처리할 수 있도록, 표준화된 형식의 오류 응답 제공.
가독성:
명확한 오류 메시지와 상태 코드 전달로 디버깅과 문제 해결을 간소화.
보안:
민감한 서버 내부 정보를 클라이언트에 노출하지 않음.
2. 기본적인 예외 처리 방식
1) @ExceptionHandler 사용
특정 컨트롤러에서 발생한 예외를 처리하기 위한 메서드를 지정합니다.
단일 컨트롤러 내에서 예외를 처리한 후
계층별로 알맞은 예외를 발생(throw new)시키기만 하면됩니다.
스프링 MVC에서 컨트롤러 단위로 예외를 처리할 수 있습니다.
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.http.ResponseEntity;
@RestController
public class MyController {
@GetMapping("/example")
public String example() {
if (true) {
throw new IllegalArgumentException("Invalid input!");
}
return "Success";
}
// 특정 예외 처리
@ExceptionHandler(IllegalArgumentException.class)
public ResponseEntity<String> handleIllegalArgumentException(IllegalArgumentException e) {
return ResponseEntity.badRequest().body("Error: " + e.getMessage());
}
}
결과:
요청: GET /example
응답:
{
"error": "Error: Invalid input!"
}
문제점
Controller 코드에 Exception 처리를 위한 책임이 추가된다.(단일 책임 원칙 위반)
단일 컨트롤러 내의 예외만 처리가 가능하다.(컨트롤러 예외처리 중복코드)
코드 재사용, 유지보수성 부족
CustomException사용자 정의Exception을 만들어서 처리할 수 있다.
2) @ControllerAdvice 사용
@ControllerAdvice는 애플리케이션 전역에서 예외를 처리할 수 있도록 해줍니다. 컨트롤러마다 예외 처리 로직을 반복하지 않아도 됩니다.
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(IllegalArgumentException.class)
public ResponseEntity<String> handleIllegalArgumentException(IllegalArgumentException e) {
return ResponseEntity.status(HttpStatus.BAD_REQUEST).body("Error: " + e.getMessage());
}
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleGeneralException(Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Unexpected error occurred!");
}
}
결과:
모든 컨트롤러에서 발생하는 예외를 처리할 수 있습니다.
예외마다 별도의 처리 로직을 정의할 수 있습니다.
3) ResponseEntityExceptionHandler 상속
스프링의 기본 예외 처리 기능을 확장하여 API 예외 처리를 커스터마이징할 수 있습니다.
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.context.request.WebRequest;
import org.springframework.web.servlet.mvc.method.annotation.ResponseEntityExceptionHandler;
@ControllerAdvice
public class CustomResponseEntityExceptionHandler extends ResponseEntityExceptionHandler {
@Override
protected ResponseEntity<Object> handleExceptionInternal(Exception ex, Object body,
HttpHeaders headers, HttpStatus status, WebRequest request) {
return new ResponseEntity<>(new ErrorResponse("INTERNAL_ERROR", ex.getMessage()), status);
}
// 사용자 정의 예외 처리
@ExceptionHandler(CustomException.class)
public ResponseEntity<Object> handleCustomException(CustomException ex) {
return new ResponseEntity<>(new ErrorResponse("CUSTOM_ERROR", ex.getMessage()), HttpStatus.BAD_REQUEST);
}
}
class ErrorResponse {
private String code;
private String message;
public ErrorResponse(String code, String message) {
this.code = code;
this.message = message;
}
// Getters and setters
}
3. 응답 형식 표준화
JSON 형식의 응답을 사용하여 클라이언트가 오류를 쉽게 이해하도록 일관된 구조를 제공합니다.
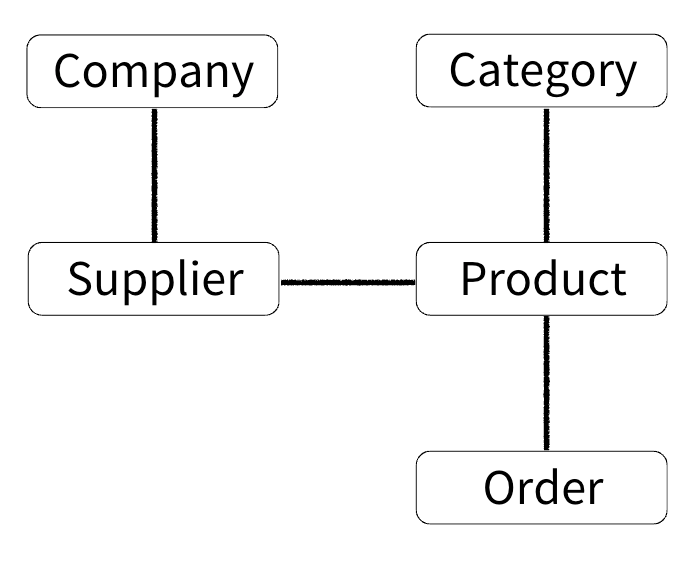
📌 단방향 연관관계는 객체 간의 관계가 한쪽에서만 참조 = 일방통행될 수 있는 관계를 말한다. 설정이 단순하고 유지 관리가 쉬우며 불필요한 데이터 접근을 방지할 수 있다.
데이터베이스 중심 객체 설계
FK 값은 Tutor가 가지고 있다.
Tutor만 참조할 수 있다.
N:1, 다대일 연관관계, 가장 많이 사용된다.
여러명(N)의 Tutor가 어떤 Company(1)에 소속 되어있는지 설정할 수 있다.
@Entity
@Table(name = "tutor")
public class Tutor {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Column(name = company_id)
private Long companyId;
// 기본 생성자, getter/setter
}
@Entity
@Table(name = "company")
public class Company {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 기본 생성자, getter/setter
}
// Company 생성 및 persist
Company company = new Company("sparta");
em.persist(company);
// Tutor 생성, setCompanyId, persist
Tutor tutor = new Tutor("wonuk");
tutor.setCompanyId(company.getId());
em.persist(tutor);
// IDENTITY 전략을 사용하면 persist()이후 PK를 바로 조회할 수 있다.
Tutor findTutor = em.find(Tutor.class, tutor.getId());
// 조회한 Tutor의 CompanyId로 Company 조회
Long companyId = findTutor.getCompanyId();
Company findCompany = em.find(Company.class, companyId);
객체 지향적인 코드를 작성할 수 없다.
Java Collection을 사용하는 것처럼 tutor.getCompany() 를 사용하지 못한다.
객체 지향 객체 설계
객체는 다른 객체를 참조한다.
N:1 관계는 @ManyToOne, @JoinColumn을 사용한다.
코드예시
@Entity
@Table(name = "tutor")
public class Tutor {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// N:1 단방향 연관관계 설정
@ManyToOne
@JoinColumn(name = "company_id")
private Company company;
// 기본 생성자, getter/setter
}
// Company 생성 및 persist
Company company = new Company("sparta");
em.persist(company);
// Tutor 생성, setCompany, persist
Tutor tutor = new Tutor("wonuk");
tutor.setCompany(company);
em.persist(tutor);
// IDENTITY 전략을 사용하면 persist()이후 PK를 바로 조회할 수 있다.
Tutor findTutor = em.find(Tutor.class, tutor.getId());
// 조회한 Tutor의 Company 조회
Company findCompany = findTutor.getCompany();
Tutor의 FK와 Company의 PK를 @JoinColumn으로 매핑한다.
Java Collection을 사용하는 것처럼 tutor.getCompany() 를 사용할 수 있다.
양방향
📌 양방향 연관관계는 객체 간의 관계가 양쪽에서 서로를 참조할 수 있는 관계를 의미한다. 이를 통해 양쪽에서 데이터를 쉽게 접근할 수 있지만 관계를 관리할 때 한쪽에서만 연관관계를 설정하거나 삭제하지 않도록 주의가 필요하다.
테이
테이블에 변화는 없다.
Tutor 테이블의 FK로 Company 테이블에 JOIN
Company 테이블의 PK로 Tutor 테이블에 JOIN
사실상 테이블의 연관관계에는 방향의 개념이 없다.
객체
@Entity
@Table(name = "tutor")
public class Tutor {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// N:1 단방향 연관관계 설정
@ManyToOne
@JoinColumn(name = "company_id")
private Company company;
// 기본 생성자, getter/setter
}
@Entity
@Table(name = "company")
public class Company {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// null을 방지하기 위해 ArrayList로 초기화 한다.(관례)
@OneToMany(mappedBy = "company")
private List<Tutor> tutors = new ArrayList<>();
// 기본 생성자, getter/setter
}
양방향 연관관계 설정을 위해 mappedBy 속성을 설정한다.
Tutor의 company 필드와 매핑된다.
// Company 생성 및 persist
Company company = new Company("sparta");
em.persist(company);
// Tutor 생성, setCompany, persist
Tutor tutor = new Tutor("wonuk");
tutor.setCompany(company);
em.persist(tutor);
// IDENTITY 전략을 사용하면 persist()이후 PK를 바로 조회할 수 있다.
Tutor findTutor = em.find(Tutor.class, tutor.getId());
// 조회한 Tutor의 Company 조회
Company findCompany = findTutor.getCompany();
// Company에 속한 Tutor List 조회
List<Tutor> tutors = findCompany.getTutors();
반대 방향으로 객체 그래프를 탐색할 수 있다.
양방향 연관관계의 주인
📌 mappedBy는 JPA 양방향 연관관계 설정 시 사용되는 속성으로 두 엔티티 간의 관계에서 연관관계의 주인이 아닌 쪽에 선언한다. 이를 통해 외래 키 관리 책임을 주인 엔티티에 두고 매핑이 중복되지 않도록 한다.
@Entity(name = "Tutor") // 기본 값, name 속성은 생략하면 된다.
@Table(name = "tutor")
public class Tutor {
// PK
@Id
private Long id;
// 필드
private String name;
// 기본 생성자
public Tutor() {
}
// 쉽게 사용하기 위해 생성자 추가
public Tutor(Long id, String name) {
this.id = id;
this.name = name;
}
}
JPA를 사용하여 객체를 테이블과 매핑할 때 사용한다.(필수)
PK 값이 필수이다.(@Id 사용)
기본 생성자가 필수이다.
final, enum, interface, inner 클래스에는 사용할 수 없다.
필드에 final 키워드를 사용할 수 없다.
속성
name
Entity 이름 지정
기본 값은 클래스 이름과 같다.
혼동을 방지하기 위해 기본 값을 사용(생략)하면 된다.
@Table
@Entity
@Table(name = "tutor")
public class Tutor {
}
@Table(uniqueConstraints = {@UniqueConstraints
(
name = "name_unique",
columnNames= {"name"}
)
}
)
// 클래스
필드 매핑
📌 JPA로 관리되는 클래스인 Entity의 필드는 테이블의 컬럼과 매핑된다.
@Entity
@Table(name = "board")
public class Board {
@Id
private Long id;
// @Column을 사용하지 않아도 자동으로 매핑된다.
private Integer view;
// 객체 필드 이름과 DB 이름을 다르게 설정할 수 있다.
@Column(name = "title")
private String bigTitle;
// DB에는 기본적으로 enum이 없다.
@Enumerated(EnumType.STRING)
private BoardType boardType;
// VARCHAR()를 넘어서는 큰 용량의 문자열을 저장할 수 있다.
@Column(columnDefinition = "longtext")
private String contents;
// 날짜 타입 DATE, TIME, TIMESTAMP를 사용할 수 있다.
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Transient
private int count;
public Board() {
}
}
사용되는 Annotation
@Column 속성
속성
설명
Default
name
객체 필드와 매핑할 테이블의 컬럼 이름
객체 필드 이름
nullable
DDL 생성 시 null 값의 허용 여부 설정
true(허용)
unique
DDL 생성 시 하나의 컬럼에 유니크 제약조건을 설정
columnDefinition
DDL 생성 시 데이터베이스 컬럼 정보를 직접 설정할 수 있다.
length
DDL 생성 시 문자 길이 제약조건 설정 단, String만 사용 가능
255
insertable
설정된 컬럼의 INSERT 가능 여부
true
updatable
설정된 컬럼의 UPDATE 가능 여부
true
@Enumerated
기본 설정인 ORDINAL을 사용하면 0, 1 과 같은 순서가 저장된다.
EnumType.ORDINAL을 사용하면 Enum 값이 추가될 때 마다 순서가 바뀌기 때문에 실제로 사용하지 않는다.
@Temporal
기본 키
📌 JPA Entity를 생성할 때 기본키는 필수로 생성해야 한다.
사용되는 Annotation
@Id
수동 생성
Tutor tutor = new Tutor(1L, "wonuk");
@GeneratedValue
자동 생성
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
PK 생성 전략
영속성 컨텍스트는 PK가 필수이다.
가장 권장되는 방식은 Long Type의 기본 키를 사용하는 것
strategy 속성
GenerationType
IDENTITY : MySQL, PostgreSQL에서 사용, 데이터베이스가 PK 자동 생성
SEQUENCE : Oracle에서 사용, @SequenceGenerator 와 함께 사용
📌 Entity 객체를 영속성 상태로 관리하는 일종의 캐시 역할을 하는 공간으로 여기에 저장된 Entity는 데이터베이스와 자동으로 동기화되며 같은 트랜잭션 내에서는 동일한 객체가 유지된다.
영속성 상태 = JPA(Java Persistence API)에서 **엔티티(Entity)**가 EntityManager에 의해 관리되는 상태
논리적인 개념
눈에 보이지 않는 공간이 생긴다.
Entity Manager 를 통해서 영속성 컨텍스트에 접근한다.
EntityManager.persist(entity);
Entity(객체)를 영속성 컨텍스트에 영속(저장)한다.
Entity
📌 데이터베이스의 테이블과 매핑되는 Java 클래스를 의미합니다.
데이터베이스에서 Entity 저장할 수 있는 데이터의 집합을 의미한다.
JPA에서 Entity란 데이터베이스의 테이블을 나타내는 클래스를 의미한다.
1. Entity의 특징
데이터베이스 테이블과 매핑:
Entity는 데이터베이스 테이블과 1:1로 매핑됩니다.
Java 객체의 필드는 데이터베이스 테이블의 컬럼에 매핑됩니다.
필수 어노테이션:
@Entity: 클래스를 Entity로 지정.
@Id: 기본 키(Primary Key)로 사용할 필드 지정.
영속성 관리:
Entity는 EntityManager에 의해 영속성 상태가 관리됩니다.
POJO(Plain Old Java Object):
Entity는 일반 Java 클래스처럼 동작하며, 특별한 상속이나 인터페이스 구현 없이 단순히 JPA의 규약을 따릅니다.
2. Entity 클래스 생성 예제
1) 기본 구조
import jakarta.persistence.*;
@Entity // 이 클래스를 Entity로 지정
@Table(name = "users") // 데이터베이스 테이블 이름 지정
public class User {
@Id // 기본 키 지정
@GeneratedValue(strategy = GenerationType.IDENTITY) // 자동 증가 값
private Long id;
@Column(nullable = false) // 필수 컬럼 지정
private String name;
@Column(unique = true) // 유니크 제약 조건
private String email;
// 기본 생성자
public User() {}
// Getters and Setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
User user = new User();
user.setName("John");
user.setEmail("john@example.com");
EntityManager em = entityManagerFactory.createEntityManager();
em.getTransaction().begin();
em.persist(user); // INSERT 쿼리 실행
em.getTransaction().commit();
2) 데이터 조회
find() 메서드를 사용하여 기본 키를 기준으로 데이터를 조회.
User user = em.find(User.class, 1L); // SELECT 쿼리 실행
System.out.println(user.getName());
3) 데이터 수정
영속 상태의 엔티티를 변경하면 변경 사항이 자동으로 데이터베이스에 반영(Dirty Checking).
em.getTransaction().begin();
user.setName("Updated Name"); // Dirty Checking으로 UPDATE 실행
em.getTransaction().commit();
4) 데이터 삭제
remove() 메서드를 사용하여 엔티티를 삭제.
em.getTransaction().begin();
em.remove(user); // DELETE 쿼리 실행
em.getTransaction().commit();
@Table(name = "users")
@Entity
public class User {
@Id
private Long id;
@Column(nullable = false)
private String name;
}
3) 관계 매핑
JPA는 엔티티 간의 관계를 지원하며, 주요 관계 매핑 어노테이션:
@OneToOne
@OneToMany
@ManyToOne
@ManyToMany
예: @OneToMany 관계 매핑
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "user")
private List<Order> orders;
}
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}
6. Entity의 장점
객체 지향 데이터 모델링:
데이터베이스 테이블을 Java 객체로 매핑하여 객체 중심으로 설계 가능.
SQL 자동 생성:
Hibernate나 JPA가 적절한 SQL을 자동으로 생성.
데이터베이스 독립성:
엔티티를 작성할 때 데이터베이스에 의존하지 않음.
생산성 향상:
데이터 접근 코드 작성이 단순화되고 유지보수가 쉬움.
7. 주의사항
기본 생성자 필수:
JPA는 리플렉션을 사용하므로 기본 생성자가 반드시 필요.
Serializable 구현 권장:
엔티티는 종종 네트워크나 파일로 전달되므로 Serializable을 구현하는 것이 좋음.
Equals와 HashCode 재정의:
엔티티를 컬렉션에서 사용할 경우, @Id 기반으로 equals()와 hashCode()를 재정의.
결론
Entity는 JPA의 핵심 요소로, 데이터베이스와의 상호작용을 객체 중심으로 단순화하고 효율적으로 설계할 수 있게 합니다. 올바른 매핑과 상태 관리를 통해 데이터베이스와 객체 간의 매끄러운 통신이 가능합니다. 추가적으로 관계 매핑이나 성능 최적화 방법에 대해 더 알고 싶다면 말씀해주세요!
Entity 생명주기
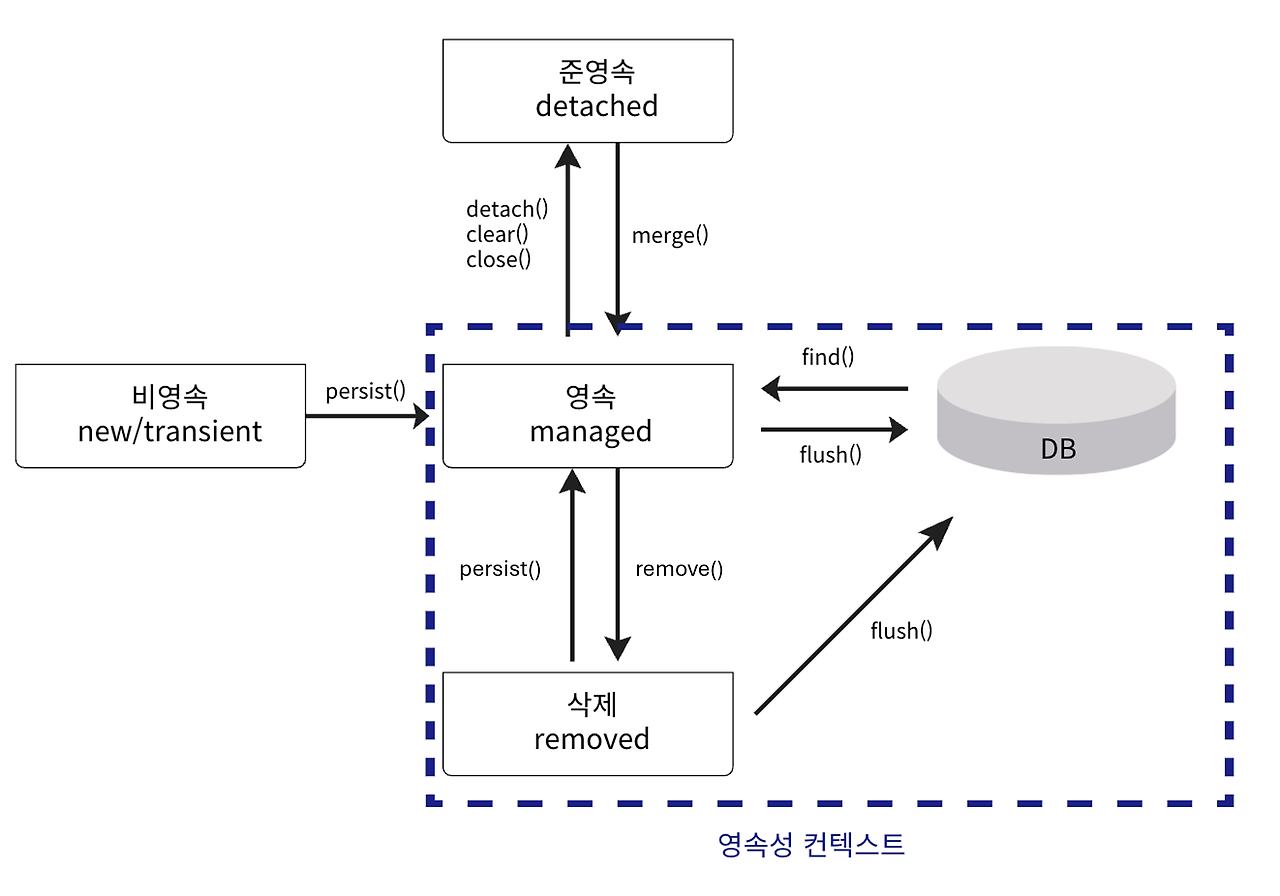
비영속(new/transient)
영속성 컨텍스트가 모르는 새로운 상태
데이터베이스와 전혀 연관이 없는 객체
영속(managed)
영속성 컨텍스트에 저장되고 관리되고 있는 상태
데이터베이스와 동기화되는 상태
준영속(detached)
영속성 컨텍스트에 저장되었다가 분리되어 더 이상 기억하지 않는 상태
삭제(removed)
영속성 컨텍스트에 의해 삭제로 표시된 상태
트랜잭션이 끝나면 데이터베이스에서 제거
엔티티의 생명주기를현실 세계의 사람과 행정 시스템에 비유해서 설명해 보겠습니다.
1. 비영속 상태 (New/Transient)
비유:
새로 태어난 아기 같은 상태입니다.
아직 주민등록도 되어 있지 않고, 정부 시스템(행정 시스템)과 아무 연관이 없습니다.
단순히메모리에만 존재하는 객체이며, 데이터베이스에 저장되지 않은 상태입니다.
예:
User user = new User(); // 비영속 상태
user.setName("John");
user.setEmail("john@example.com");
이후 user.setName("Updated John")처럼 객체가 변경되면, 데이터베이스에도 자동으로 반영됩니다.
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// 비영속
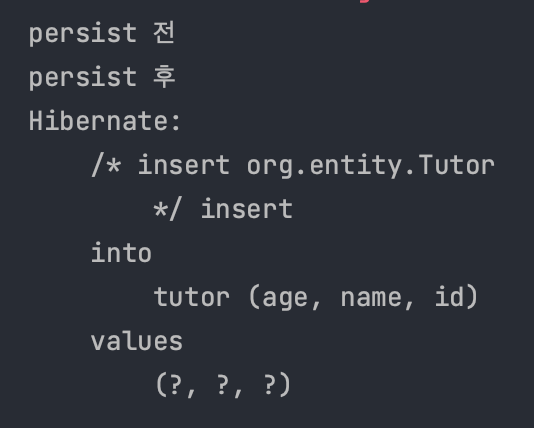
Tutor tutor = new Tutor(1L, "wonuk", 100);
System.out.println("persist 전");
// 영속
em.persist(tutor);
System.out.println("persist 후");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
em.persist()가 호출되며 영속 상태가 된다.
persist 후 출력 이후에 SQL이 실행된다.
트랜잭션 Commit 시점에 SQL이 실행된다.
3. 준영속 상태 (Detached)
비유:
주민등록이 말소된 상태입니다.
한때 행정 시스템(영속성 컨텍스트)에 등록되었지만, 더 이상 관리되지 않습니다.
이 사람의 정보가 행정 시스템과는 연관이 없으므로, 정보를 업데이트해도 정부 시스템에는 반영되지 않습니다.
특징:
객체는 메모리에 있지만, 영속성 컨텍스트와의 연결이 끊어져 데이터베이스와 동기화되지 않습니다.
예:
detach() 메서드는 객체를 영속성 컨텍스트에서 분리하여 준영속 상태로 만듭니다.
객체를 변경해도 데이터베이스에 영향을 주지 않습니다.
영속성 컨텍스트가 제공하는 기능을 사용하지 못한다.
em.detach()
특정 Entity만 준영속 상태로 변경한다.
em.clear()
영속성 컨텍스트를 초기화 한다.
em.close()
영속성 컨텍스트를 종료한다.
4. 삭제 상태 (Removed)
비유:
사망신고를 한 상태입니다.
행정 시스템(영속성 컨텍스트)에 의해 삭제로 표시되었으며, 트랜잭션이 완료되면 데이터베이스(정부 기록)에서도 완전히 삭제됩니다.
특징:
삭제 상태로 표시되면, 트랜잭션이 완료되는 시점에 데이터베이스에서 삭제됩니다.
예:
remove() 메서드를 호출하면, 해당 객체는 삭제 상태로 표시되고, 트랜잭션이 끝나면 데이터베이스에서 제거됩니다.
em.remove(user); // 삭제 상태로 전환
5. 전체 흐름을 비유로 설명
비영속 상태: "아직 주민등록이 안 된 상태의 아기"
시스템(영속성 컨텍스트)과 전혀 연관이 없음.
영속 상태: "주민등록이 완료된 상태"
정부가 해당 사람을 등록하고 관리.
변경 사항(주소, 이름 등)이 자동으로 기록됨.
준영속 상태: "주민등록 말소 상태"
과거에 등록되었지만 더 이상 정부 시스템에서 관리하지 않음.
개인이 어디에 이사 가든 정부는 알 수 없음.
삭제 상태: "사망신고 상태"
정부 시스템에 더 이상 존재하지 않으며, 기록에서 삭제될 예정.
6. 실제 코드 흐름 예제
// 비영속 상태
User user = new User();
user.setName("John");
// 영속 상태로 전환
EntityManager em = entityManagerFactory.createEntityManager();
em.getTransaction().begin();
em.persist(user); // 영속 상태
user.setName("Updated John"); // 변경 감지(Dirty Checking)
// 준영속 상태로 전환
em.detach(user);
user.setName("Detached John"); // 데이터베이스에 반영되지 않음
// 삭제 상태로 전환
em.getTransaction().begin();
em.remove(user); // 삭제 상태
em.getTransaction().commit(); // 데이터베이스에서 제거
7. 요약
상태
비유
특징
비영속
주민등록이 안 된 상태
단순 객체 생성, 데이터베이스와 연관 없음.
영속
주민등록 완료된 상태
영속성 컨텍스트가 관리하며 데이터베이스와 동기화됨.
준영속
주민등록 말소된 상태
더 이상 영속성 컨텍스트가 관리하지 않으며 데이터베이스와 동기화되지 않음.
삭제
사망신고된 상태
데이터베이스에서 삭제로 표시되며, 트랜잭션 완료 시 실제로 제거됨.
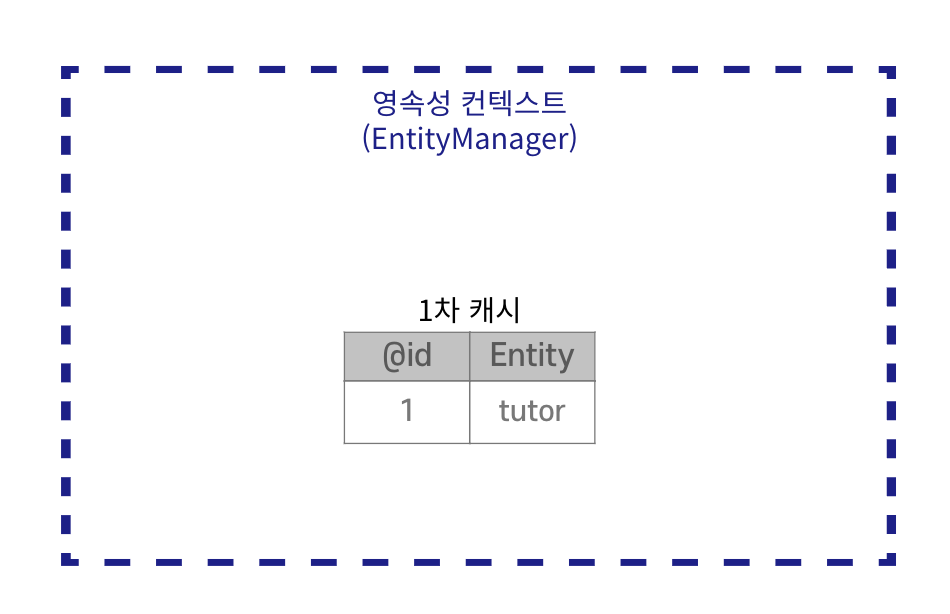
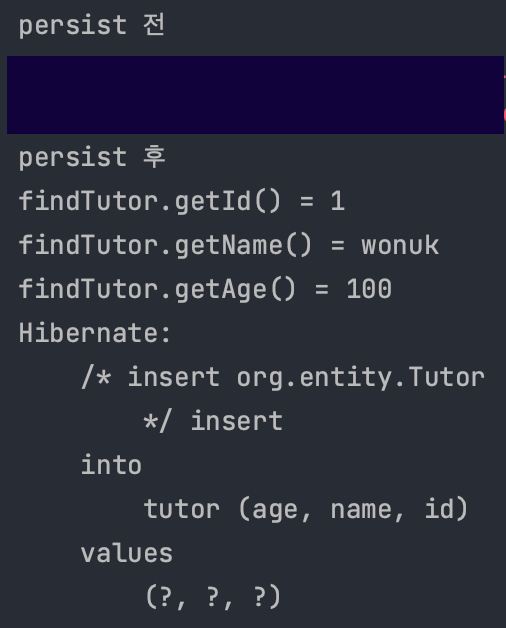
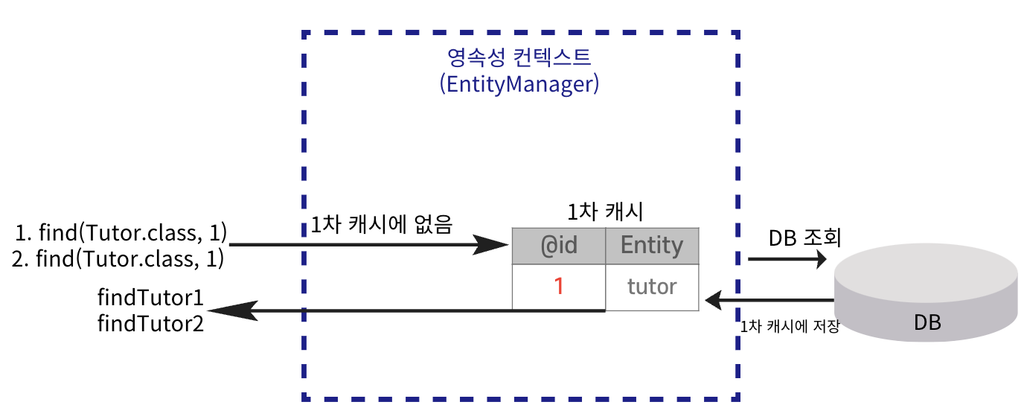
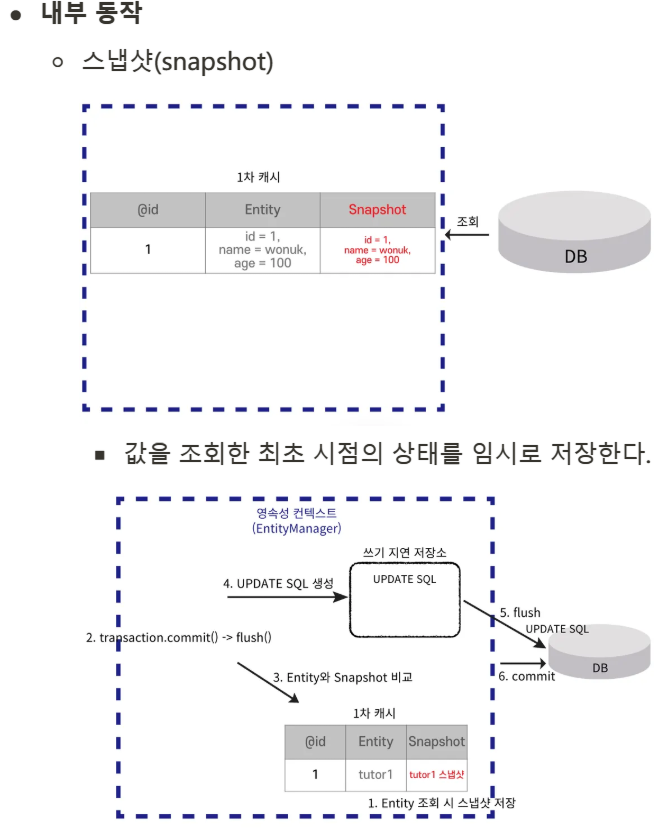
1차 캐시
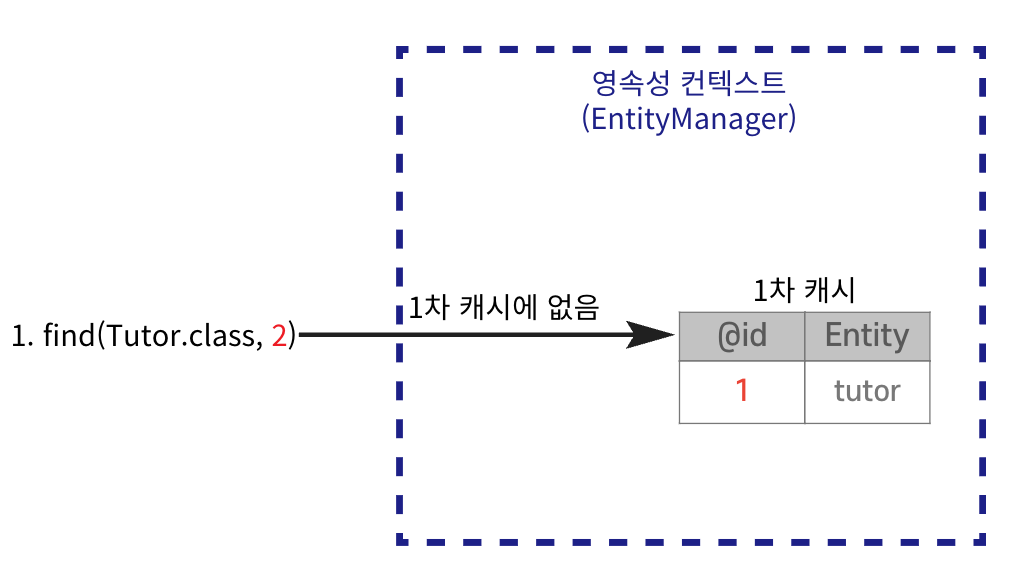
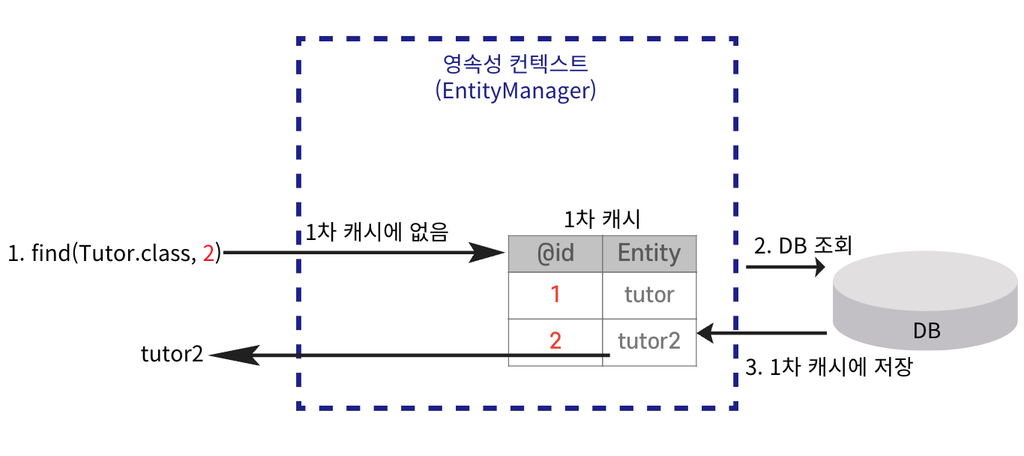
📌 엔티티를 영속성 컨텍스트에 저장할 때 생성되는 메모리 내 캐시이다. 엔티티는 먼저 1차 캐시에 저장되고 이후 같은 엔티티를 요청하면 DB를 조회하지 않고 1차 캐시에서 데이터를 반환하여 성능을 높일 수 있다.
영속성 컨텍스트의 1차 캐시에 저장된다.
// 비영속
Tutor tutor = new Tutor(1L, "wonuk", 100);
// 영속, 1차 캐시에 저장
em.persist(tutor);
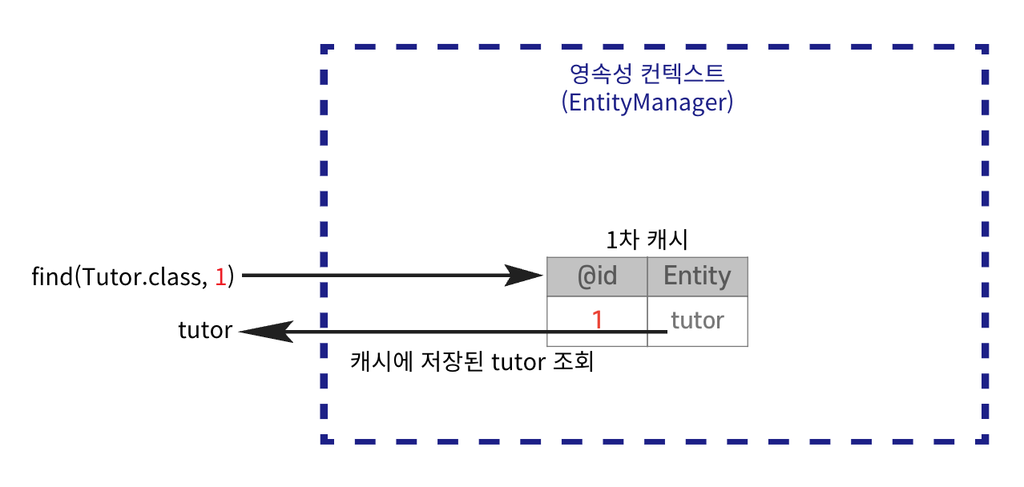
영속된 Entity 조회
Database가 아닌 1차 캐시에 저장된 Entity를 먼저 조회한다.
// 1차 캐시에서 조회
Tutor findTutor = em.find(Tutor.class, 1L);
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// 비영속
Tutor tutor = new Tutor(1L, "wonuk", 100);
// 영속
System.out.println("persist 전");
em.persist(tutor);
System.out.println("persist 후");
Tutor findTutor = em.find(Tutor.class, 1L);
System.out.println("findTutor.getId() = " + findTutor.getId());
System.out.println("findTutor.getName() = " + findTutor.getName());
System.out.println("findTutor.getAge() = " + findTutor.getAge());
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
실행결과
1차 캐시의 Entity를 조회한다.
조회 SQL이 실행되지 않는다.
트랜잭션 Commit 시점에 INSERT SQL이 실행된다.
**트랜잭션(Transaction)**은 데이터베이스 작업에서 데이터의 일관성, 무결성을 보장하기 위해 논리적으로 묶여있는 작업 단위를 의미합니다.
데이터베이스에 저장된 데이터 조회
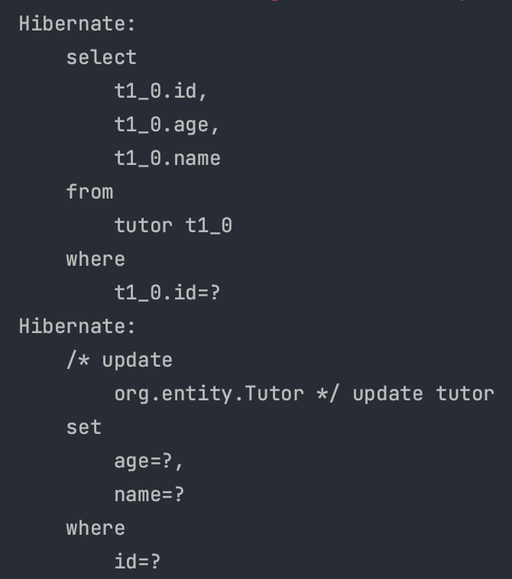
1차 캐시는 동일한 트랜잭션 안에서만 사용이 가능하다.
요청이 들어오고 트랜잭션이 종료되면 영속성 컨텍스트는 삭제된다.
코드예시
xml <property name="hibernate.hbm2ddl.auto" value="none" /> 설정
DDL을 자동으로 생성하지 않는다.
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// 데이터베이스에서 조회 후 1차 캐시에 저장
Tutor findTutor = em.find(Tutor.class, 1L);
// 1차 캐시에서 조회
Tutor findCacheTutor = em.find(Tutor.class, 1L);
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
}
실행결과 : 조회 SQL이 한번만 실행된다.
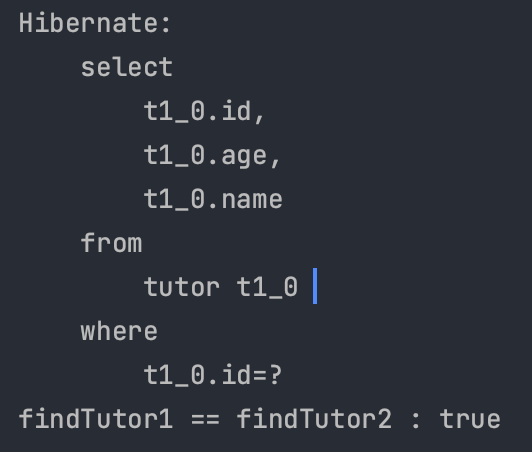
동일성 보장
📌 동일한 트랜잭션 안에서 특정 엔티티를 여러 번 조회해도 항상 같은 객체 인스턴스를 반환한다. 영속성 컨텍스트는 1차 캐시를 사용하여 같은 엔티티를 중복 조회해도 동일한 객체를 참조하게 하여 일관성을 유지한다.
동일한 트랜잭션 내에서 조회된 Entity는 같은 인스턴스를 반환한다.
DB에 저장된 데이터를 조회하여 1차 캐시에 저장한다.
1차 캐시에 저장된 데이터를 조회한다.
코드예시
Database에 저장된 데이터가 있는 상태
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// DB 조회, 1차 캐시에 저장
Tutor findTutor1 = em.find(Tutor.class, 1L);
// 1차 캐시 조회
Tutor findTutor2 = em.find(Tutor.class, 1L);
System.out.println("findTutor1 == findTutor2 : " + findTutor1.equals(findTutor2));
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
조회 SQL이 한번만 실행된다.
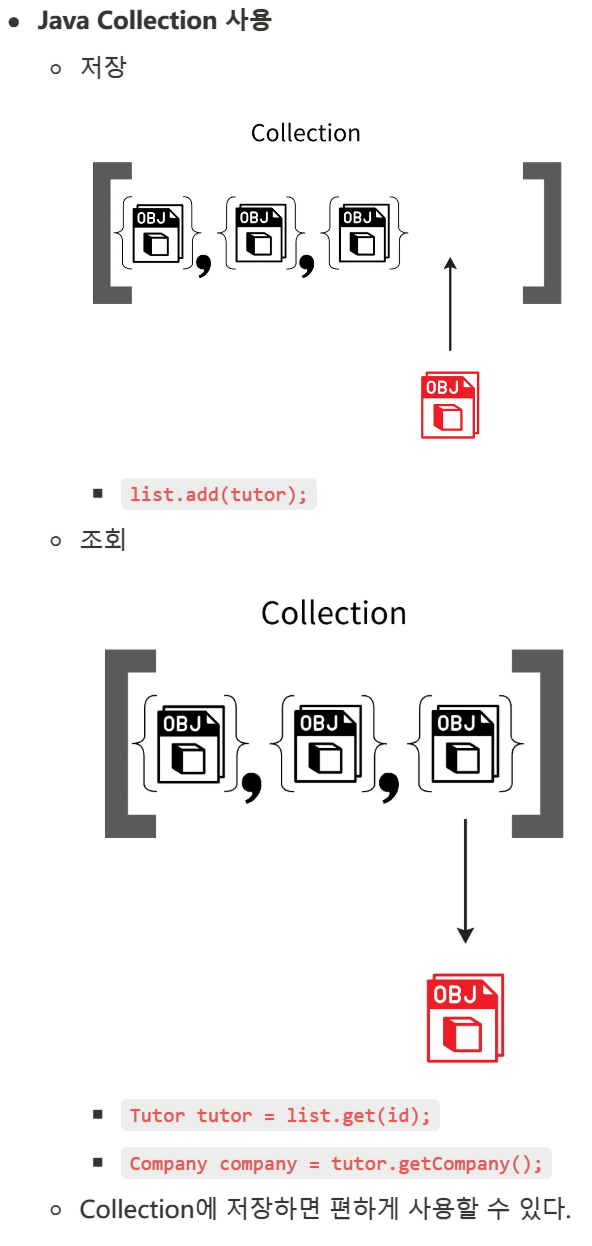
마치 Java Collection에서 객체를 조회하듯이 사용할 수 있다.
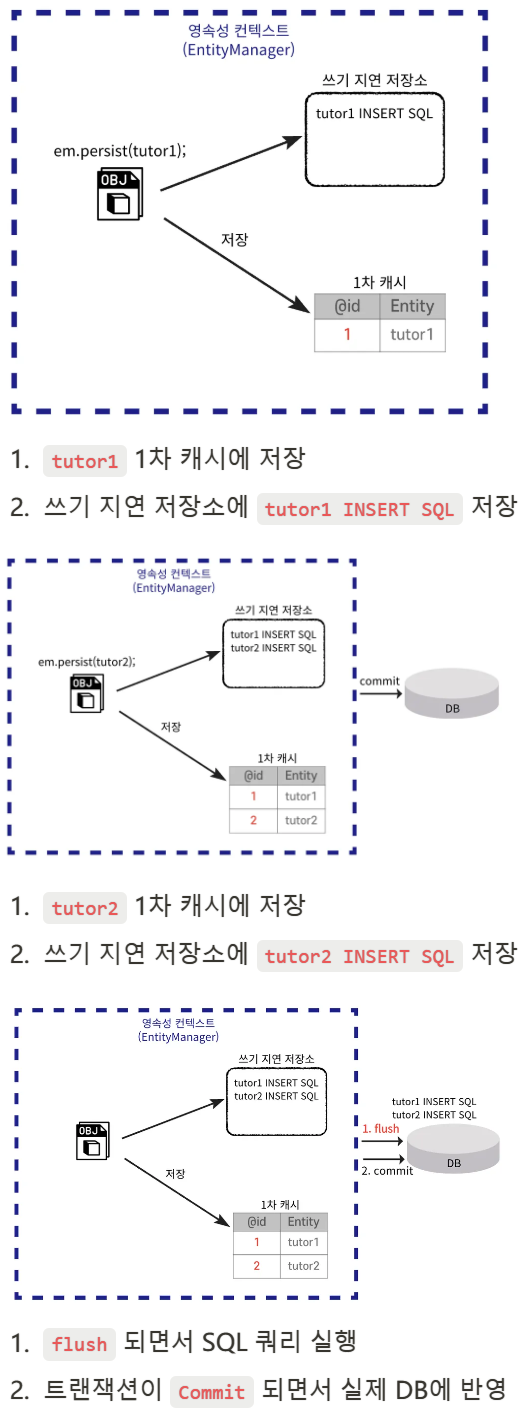
쓰기 지연
📌 엔티티 객체의 변경 사항을 DB에 바로 반영하지 않고 트랜잭션이 커밋될 때 한 번에 반영하는 방식으로 이를 통해 성능을 최적화하고 트랜잭션 내에서의 불필요한 DB 쓰기 작업을 최소화한다.
예시 코드
xml <property name="hibernate.hbm2ddl.auto" value="create" /> 설정
Entity와 매핑된 테이블을 삭제 후 새로 생성한다.
코드예시
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
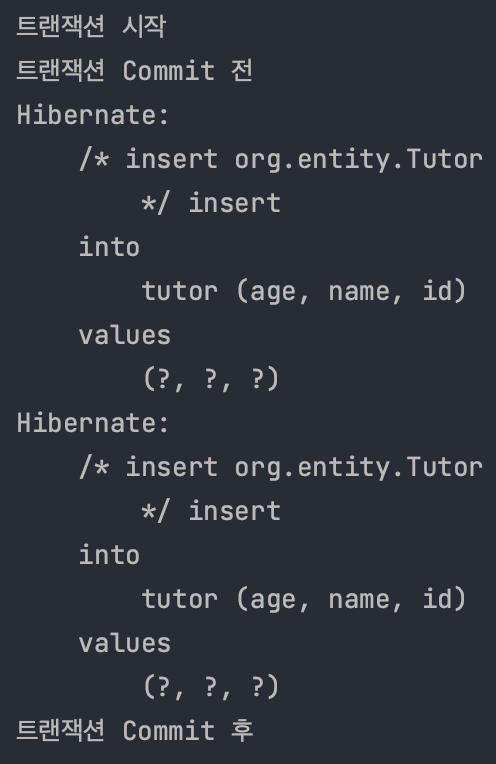
System.out.println("트랜잭션 시작");
Tutor tutor1 = new Tutor(1L, "wonuk1", 100);
Tutor tutor2 = new Tutor(2L, "wonuk2", 200);
em.persist(tutor1);
em.persist(tutor2);
System.out.println("트랜잭션 Commit 전");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
System.out.println("트랜잭션 Commit 후");
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
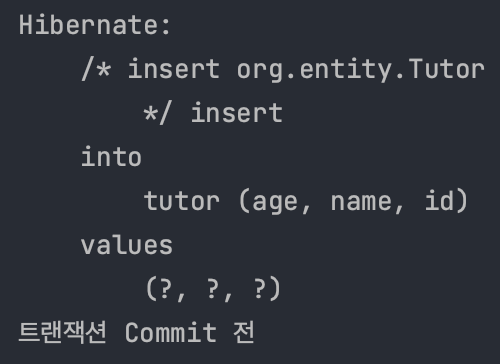
트랜잭션이 Commit된 이후에 SQL이 실행된다.
실행결과
여러개의 SQL을 하나씩 나누어 보낸다.
hibernate.jdbc.batch_size
여러개의 SQL을 여러번 보내는 것이 아니라 합쳐서 하나로 보낸다.
통신 비용을 줄여서 성능을 개선할 수 있다.
변경 감지(Dirty Checking)
📌 영속성 컨텍스트가 엔티티의 초기 상태를 저장하고 트랜잭션 커밋 시점에 현재 상태와 비교해 변경 사항이 있는지 확인하는 기능이다.
Database에 저장된 데이터가 있는 상태
xml <property name="hibernate.hbm2ddl.auto" value="none" /> 설정
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
Tutor tutor = em.find(Tutor.class, 1L);
tutor.setName("수정된 이름");
// Java Collection을 사용하면 값을 수정하고 다시 저장하지 않는다.
// em.persist(tutor);
System.out.println("트랜잭션 Commit 전");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
System.out.println("트랜잭션 Commit 후");
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
em.persist(tutor); 로 저장하지 않아도 update SQL이 실행된다.
Entity를 변경하고자 할 때 em.persist() 를 사용하지 않아야 실수를 방지한다.
em.remove() 를 통해 Entity를 삭제할 때도 위와 같은 방식으로 동작한다. DELETE SQL이 트랜잭션 Commit 시점에 실행된다.
flush
📌 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하는 기능으로, 변경된 엔티티 정보를 SQL로 변환해 데이터베이스에 동기화한다. 트랜잭션 커밋 시 자동으로 실행되지만 특정 시점에 데이터베이스 반영이 필요할 때 수동으로 호출할 수도 있다.
flush 사용 방법
자동 호출
트랜잭션이 Commit 되는 시점에 자동으로 호출된다.
수동 호출
em.flush() 를 통해 수동으로 호출할 수 있다.
코드예시
xml <property name="hibernate.hbm2ddl.auto" value="create" /> 설정
기존 테이블을 삭제(DROP) 후 다시 생성(CREATE)한다.
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
Tutor tutor = new Tutor(1L, "wonuk", 100);
em.persist(tutor);
// flush 수동 호출
em.flush();
System.out.println("트랜잭션 Commit 전");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
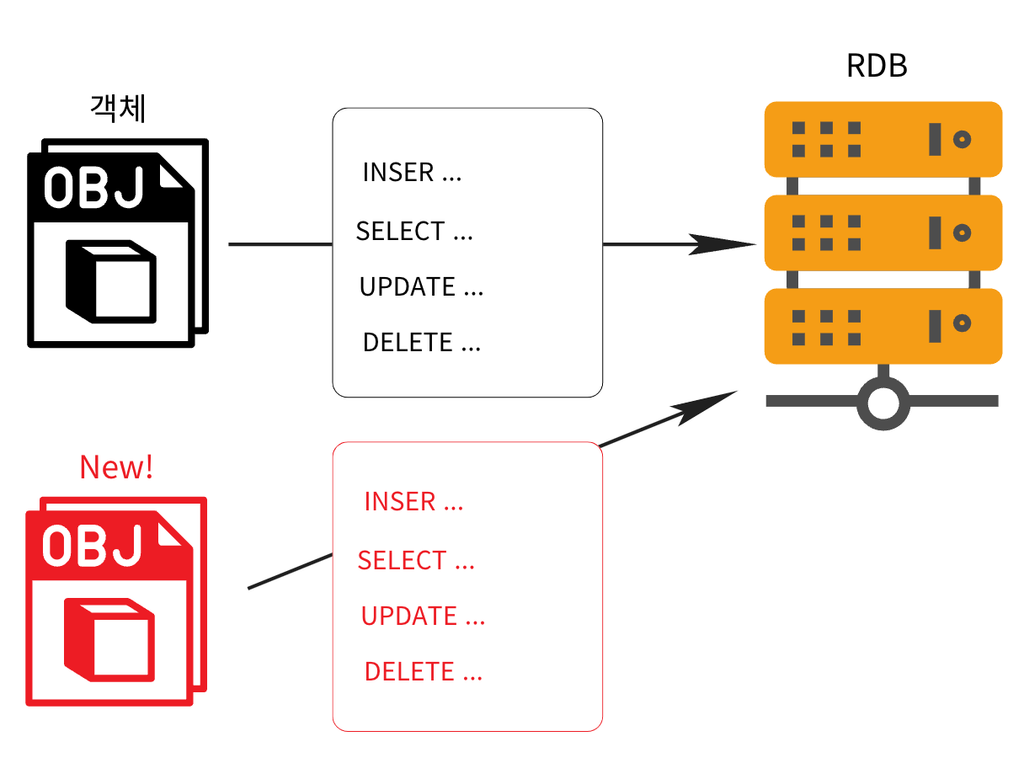
📌 객체 지향 프로그래밍 언어인 Java와 관계형 데이터베이스 간의 패러다임 불일치 문제를 해결하여 데이터베이스 작업을 객체 지향적으로 수행할 수 있도록 지원한다.
객체 지향적으로 설계하면 SQL코드가 점점 복잡해진다. JDBC로 외래키로 참조를 구현해본 경험이 있으니 뭔 말인지 잘 알것이다. 이러한 문제를 해결하기 위해 JPA가 등장했다.
Java 애플리케이션에서 객체를 관계형 데이터베이스와 매핑하여 데이터를 처리할 수 있도록 지원하는 ORM(Object-Relational Mapping) 표준이다.
Java의 ORM 기술 표준(인터페이스)
대표적인 구현체로 Hibernate를 주로 사용한다.
표준으로 만들어지면 더욱 명확하게 정의하고 사용할 수 있는 장점이 생긴다.
1. JPA의 주요 개념
ORM(Object-Relational Mapping):
객체지향 프로그래밍의 객체와 관계형 데이터베이스의 테이블 간 매핑을 제공.
예: Java 클래스의 필드 ↔ 데이터베이스 테이블의 컬럼.
Java EE 표준:
JPA는 Java EE 표준 사양으로, 특정 구현체(Hibernate, EclipseLink 등)에 독립적.
추상화 제공:
SQL 작성 없이 데이터베이스 작업 가능.
JPA는 JPQL(Java Persistence Query Language)을 통해 객체 중심의 쿼리 제공.
2. JPA 주요 구성 요소
Entity:
데이터베이스 테이블과 매핑되는 Java 클래스.
@Entity 어노테이션을 사용하여 매핑.
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Getters and Setters
}
EntityManager:
JPA의 핵심 인터페이스로, 엔티티를 관리.
데이터베이스의 CRUD 작업을 처리.
주요 메서드:
persist(): 엔티티 저장.
find(): 엔티티 조회.
merge(): 엔티티 갱신.
remove(): 엔티티 삭제.
Persistence Context:
엔티티를 관리하는 메모리 공간.
1차 캐시로 작동하여 같은 엔티티를 중복 조회할 때 데이터베이스를 재호출하지 않음.
JPQL:
JPA에서 사용하는 객체지향 쿼리 언어.
SQL과 유사하지만 엔티티와 속성을 대상으로 동작.
String jpql = "SELECT u FROM User u WHERE u.name = :name";
List<User> users = entityManager.createQuery(jpql, User.class)
.setParameter("name", "John")
.getResultList();
3. JPA의 동작 방식
객체를 생성하고 저장:
EntityManager를 사용해 Java 객체를 데이터베이스에 저장.
SQL은 JPA가 자동 생성.
EntityManager em = entityManagerFactory.createEntityManager();
em.getTransaction().begin();
User user = new User();
user.setName("John");
user.setEmail("john@example.com");
em.persist(user); // INSERT SQL 생성 및 실행
em.getTransaction().commit();
데이터 읽기:
EntityManager의 find() 메서드를 사용해 데이터를 조회.
SQL은 자동 생성.
User user = em.find(User.class, 1L); // SELECT SQL 생성 및 실행
데이터 갱신:
엔티티 객체의 속성을 변경하면 JPA가 자동으로 데이터베이스에 반영(Dirty Checking).
em.getTransaction().begin();
user.setEmail("newemail@example.com"); // UPDATE SQL 생성 및 실행
em.getTransaction().commit();
데이터 삭제:
remove() 메서드를 호출해 엔티티 삭제.
em.getTransaction().begin();
em.remove(user); // DELETE SQL 생성 및 실행
em.getTransaction().commit();
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getUsersByName(String name) {
return userRepository.findByName(name);
}
}
8. JPA와 다른 데이터 접근 방식 비교
항목 JPA MyBatis JDBC
주요 방식
ORM
SQL 매퍼 기반
직접 SQL 작성
생산성
높음
중간
낮음
유지보수
상대적으로 쉬움
중간
어렵다
성능
설정에 따라 최적화 가능
효율적 (SQL 직접 작성 가능)
효율적
사용 사례
객체 중심 데이터 처리
복잡한 SQL 처리
단순한 데이터 처리
9. JPA를 사용할 때 주의사항
N+1 문제:
연관 관계에서 데이터가 예상보다 더 많이 로드될 수 있음.
해결책: Fetch Join 또는 @BatchSize 사용.
캐싱 전략 관리:
1차 캐시와 2차 캐시 사용 시 일관성을 유지해야 함.
데이터베이스 트랜잭션 관리:
JPA는 트랜잭션이 필요하므로 Spring과 함께 사용하는 경우 @Transactional로 트랜잭션 범위를 명시.
복잡한 비즈니스 로직:
JPA만으로 모든 문제를 해결할 수 없으므로, 복잡한 쿼리는 Native Query 활용.
ORM(Object-Relational Mapping)
객체와 관계형 DB를 자동으로 Mapping하여 패러다임 불일치 문제를 해결한다.
JDBC API
ORM(Object-Relational Mapping)
🐳 객체 지향 프로그래밍의 객체와 관계형 데이터베이스의 테이블을 자동으로 매핑해주는 기술
1. ORM의 주요 개념
객체-관계 불일치 해결:
객체지향 언어에서는 데이터를 객체로 표현하지만, 관계형 데이터베이스는 데이터를 테이블로 저장.
ORM은 객체와 테이블 간의 매핑을 통해 이 불일치를 해결.
자동화된 데이터 처리:
SQL 쿼리 작성 없이 객체를 사용하여 데이터 저장, 조회, 수정, 삭제를 처리.
데이터베이스 독립성:
ORM을 사용하면 코드가 특정 데이터베이스에 종속되지 않음.
2. ORM의 주요 기능
CRUD 작업 자동화:
Create, Read, Update, Delete 작업을 객체를 통해 처리.
SQL 대신 메서드를 호출하여 데이터 조작.
객체와 테이블 매핑:
클래스 → 테이블, 필드 → 컬럼으로 매핑.
연관 관계 매핑:
객체의 연관 관계(1:1, 1:N, N:M)를 데이터베이스 테이블의 외래 키 관계로 매핑.
캐싱 지원:
1차 캐시(영속성 컨텍스트) 및 2차 캐시를 통해 데이터베이스 호출 최소화.
쿼리 생성:
JPQL이나 Query DSL 등을 통해 객체 기반의 쿼리 작성 가능.
3. ORM의 장점
생산성 증가:
SQL 쿼리를 작성하지 않아도 CRUD 작업을 수행 가능.
데이터베이스 처리 로직의 코드 양을 크게 줄임.
유지보수성 향상:
객체 중심의 코드 작성으로 가독성이 높아지고, 데이터베이스 변경 시 코드 변경이 최소화.
데이터베이스 독립성:
코드가 특정 DBMS에 의존하지 않으므로 DB를 쉽게 교체 가능.
보안 강화:
SQL 인젝션 같은 보안 취약점을 예방하기 쉬움.
연관 관계 처리:
객체 간의 관계를 직접 정의하고 활용 가능.
4. ORM의 단점
학습 곡선:
ORM 도구의 설정 및 사용법을 이해하는 데 시간이 필요.
성능 문제:
ORM이 자동 생성한 쿼리가 비효율적일 수 있음.
복잡한 쿼리는 직접 작성해야 할 수도 있음(Native Query 사용).
디버깅 어려움:
ORM이 생성한 SQL을 디버깅하거나 최적화하기 어렵다.
추상화 한계:
데이터베이스 고유 기능(예: 저장 프로시저, 특정 SQL 구문) 사용 시 어려움.
5. ORM 동작 방식
1) 매핑 설정
객체를 데이터베이스 테이블에 매핑.
클래스는 테이블에 매핑.
필드는 테이블의 컬럼에 매핑.
Java JPA 예제:
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(unique = true, nullable = false)
private String email;
// Getters and Setters
}
2) 데이터 저장
객체를 데이터베이스에 저장하면, ORM이 INSERT 쿼리를 생성하고 실행.
User user = new User();
user.setName("John Doe");
user.setEmail("john@example.com");
entityManager.persist(user); // INSERT SQL 실행
3) 데이터 조회
객체를 조회하면 ORM이 자동으로 SELECT 쿼리를 생성.
User user = entityManager.find(User.class, 1L); // SELECT SQL 실행
6. JPA와 ORM의 관계
JPA는 Java에서 ORM 표준을 정의한 API.
Hibernate, EclipseLink 같은 구현체는 JPA의 표준을 따르며, 이를 기반으로 ORM 기능 제공.
7. ORM 사용 시 주의점
N+1 문제:
연관된 데이터를 가져올 때 추가적인 쿼리가 반복 실행될 수 있음.
해결책: Fetch Join, @BatchSize 사용.
복잡한 쿼리:
복잡한 JOIN 쿼리나 데이터베이스 고유 기능 사용 시 Native Query 작성 필요.
캐싱 전략 관리:
1차 캐시와 2차 캐시 사용을 적절히 조정해야 성능을 최적화.
스키마 설계:
ORM은 데이터베이스 설계를 자동화하지 않으므로, 스키마 설계는 여전히 중요.
8. ORM이 적용된 데이터 처리 흐름
애플리케이션 개발:
개발자는 객체(Entity) 중심으로 코드를 작성.
ORM 매핑:
ORM이 객체와 테이블 간의 매핑을 수행.
쿼리 생성 및 실행:
CRUD 작업 시 ORM이 SQL을 생성하여 데이터베이스와 통신.
결과 매핑:
SQL 실행 결과를 객체로 변환하여 반환.
Java EE 표준
🐳 Java를 사용하여 대규모 엔터프라이즈 애플리케이션을 개발하기 위한 표준 플랫폼입니다.
1. Java EE의 주요 개념
표준화된 사양:
엔터프라이즈 애플리케이션 개발을 위한 API와 스펙이 표준화되어 있어 다양한 구현체에서 동일하게 작동.
컨테이너 기반 실행 환경:
Java EE 애플리케이션은 애플리케이션 서버(Java EE 컨테이너)에서 실행되며, 컨테이너가 리소스 관리, 보안, 트랜잭션 등을 처리.
엔터프라이즈 개발 도구:
데이터베이스 액세스, 메시징, 웹 서비스, 의존성 주입 등 대규모 애플리케이션에 필요한 기능 제공.
2. Java EE의 주요 구성 요소
1) Web Tier
Servlet:
HTTP 요청/응답을 처리하는 자바 기반 웹 컴포넌트.
JSP (Java Server Pages):
HTML과 Java 코드를 결합하여 동적인 웹 콘텐츠 생성.
JSF (Java Server Faces):
MVC 패턴을 기반으로 한 컴포넌트 기반 UI 프레임워크.
2) Business Tier
EJB (Enterprise JavaBeans):
트랜잭션, 보안, 동시성 관리 등을 포함한 비즈니스 로직 실행.
CDI (Contexts and Dependency Injection):
의존성 주입(Dependency Injection)을 제공하여 객체 간의 결합도 감소.
3) Persistence Tier
JPA (Java Persistence API):
ORM(Object Relational Mapping) 표준으로, 데이터베이스와 객체 간의 매핑을 제공.
4) Integration Tier
JMS (Java Messaging Service):
메시징 시스템과 통합을 지원.
JAX-RS (Java API for RESTful Web Services):
RESTful 웹 서비스 개발을 위한 API.
JAX-WS (Java API for XML Web Services):
SOAP 기반 웹 서비스 개발을 지원.
5) Other APIs
JTA (Java Transaction API):
분산 트랜잭션 관리.
JavaMail:
이메일 송수신 기능 제공.
Batch API:
대량 데이터 처리(batch processing) 지원.
3. Java EE의 특징
표준 기반:
모든 Java EE 애플리케이션은 표준화된 API를 사용하므로 다양한 애플리케이션 서버에서 동작.
확장성:
모듈 기반 설계를 통해 애플리케이션을 확장하기 쉽고, 대규모 애플리케이션 개발에 적합.
컨테이너 관리:
Java EE 컨테이너가 보안, 트랜잭션, 리소스 관리, 의존성 주입 등을 자동으로 처리.
플랫폼 독립성:
Java 기반으로 설계되었기 때문에 플랫폼에 독립적.
다양한 구현체 지원:
다양한 Java EE 구현체(Hibernate, WildFly, GlassFish, Apache TomEE 등)에서 실행 가능.
4. Java EE의 주요 애플리케이션 서버
Java EE 사양은 여러 애플리케이션 서버에서 구현됩니다. 대표적인 서버는 다음과 같습니다:
서버
특징
GlassFish
Oracle가 Java EE의 참조 구현체로 제공한 서버. 현재는 Eclipse 재단에서 관리.
WildFly
JBoss의 오픈소스 애플리케이션 서버.
Apache TomEE
Tomcat 기반 경량 Java EE 서버.
WebLogic
Oracle에서 제공하는 상용 애플리케이션 서버.
WebSphere
IBM의 상용 엔터프라이즈 애플리케이션 서버.
5. Jakarta EE와의 관계
2017년, Oracle이 Java EE의 관리를 Eclipse 재단에 넘기면서 이름이 Jakarta EE로 변경됨.
최신 표준은 Jakarta EE이며, 기존 Java EE의 발전된 버전.
6. Java EE의 주요 사용 사례
엔터프라이즈 애플리케이션:
대규모 비즈니스 로직을 처리하는 시스템 개발.
예: 금융, 통신, 물류 시스템.
웹 애플리케이션 개발:
JSP, Servlet, JSF 등을 사용하여 웹 애플리케이션 구현.
분산 시스템:
EJB, JMS를 활용하여 여러 시스템 간의 통합.
RESTful API 개발:
JAX-RS를 사용하여 RESTful 웹 서비스를 개발.
데이터 처리:
JPA와 JDBC를 통해 데이터베이스와 상호작용.
7. Java EE의 장단점
장점
표준화:
다양한 구현체에서 동일한 사양을 따름.
풍부한 기능:
엔터프라이즈 애플리케이션 개발에 필요한 대부분의 기능 포함.
확장성과 유연성:
대규모 시스템 설계 및 확장에 적합.
컨테이너 관리:
트랜잭션, 보안 등 복잡한 작업을 컨테이너가 자동 처리.
단점
복잡성:
학습 곡선이 높으며, 초기 설정과 구조 설계가 복잡.
무거운 사양:
Java EE의 모든 기능을 사용하지 않더라도 큰 오버헤드가 있을 수 있음.
의존성:
애플리케이션 서버의 성능 및 설정에 영향을 받음.
8. Java EE의 기본 동작 흐름
클라이언트 요청:
HTTP 요청 또는 메시지 큐를 통해 서버로 전달.
Web Tier 처리:
Servlet, JSP 또는 JSF에서 요청을 처리.
Business Tier 처리:
EJB 또는 POJO에서 비즈니스 로직 실행.
Database와 상호작용:
JPA 또는 JDBC를 통해 데이터베이스에 접근.
응답 생성:
처리 결과를 클라이언트로 반환.
생산성
// 저장
jpa.persist(tutor);
// 조회
Tutor tutor = jpa.find(Tutor.class, tutorId);
// 수정
tutor.setName("수정할 이름");
// 삭제
jpa.remove(tutor);
persist란 영구히 저장한다는 뜻
마치 컬렉션에 저장한듯 객체가 저장되어 조회가 간편하다.
수정하고자 할 때 꺼낸 객체에 setName() 하면된다.
유지보수성
// 기존
public class Tutor {
private String id;
private String name;
}
// 필드 수정
public class Tutor {
private String id;
private String name;
private Integer age;
}
객체 필드가 수정 되어도 SQL은 JPA가 알아서 처리한다.
패러다임 불일치 문제 해결
상속
연관관계
tutor.setCompany(company);
jpa.persist(company);
Collection처럼 사용할 수 있다.
객체 그래프 탐색
Tutor tutor = jpa.find(Tutor.class, tutorId);
Company company = tutor.getCompany();
// 지연 로딩
Tutor tutor = tutorRepository.find(tutorId); // SELECT * FROM tutor
Company company = tutor.getCompany();
String companyName = company.getName(); // SELECT * FROM company
// 즉시 로딩
// SELECT t.*, c.* FROM tutor t JOIN Company c ON
Tutor tutor = tutorRepository.find(tutorId);
Company company = tutor.getCompany();
String companyName = company.getName();
지연로딩
필요할 때만 조회하기 때문에 통신 비용 감소
즉시로딩
한번만 조회하기 때문에 네트워크 통신 비용 감소
hibernate.dialect
📌 Hibernate가 사용하는 데이터베이스 방언(dialect)을 지정하는 설정으로 데이터베이스와 Hibernate가 상호작용할 때 특정 데이터베이스에 맞게 SQL 구문을 자동으로 조정하는 역할을 수행한다.
데이터베이스 방언(Dialect) = 서로 다른 데이터베이스 시스템의 SQL 문법과 기능 차이를 처리하기 위해 제공
📌 객체는 클래스를 통해 만들어지며 속성(field)와 기능(method)를 포함하며 관계형 데이터베이스는 데이터를 테이블 형식으로 표현하며 각 테이블은 열(column)과 행(row)으로 구성된다.
객체 지향 언어 Java
객체를 저장할 수 있는 다양한 종류의 Database
RDB(무결성, 일관성)
NoSQL
File
기타 등등..
관계형 데이터베이스와 객체 지향의 패러다임 불일치 문제가 발생한다.
관계형 DB에 객체 저장 시 발생하는 문제점
1. 관계형 DB와 객체 간의 구조적 차이
객체 지향 vs. 관계형 모델:
객체지향 언어(Java, Python 등)는 객체를 중심으로 설계되며, 상태(필드)와 행동(메서드)을 결합.
관계형 데이터베이스는 테이블과 행(row)을 기반으로 데이터를 저장하며, 테이블 간 관계(Primary Key, Foreign Key)를 정의.
데이터 표현 차이:
객체는 복잡한 데이터 구조를 포함할 수 있지만, 데이터베이스 테이블은 정규화된 단순 구조로 데이터를 저장.
매핑 복잡성:
객체를 RDB 테이블에 맞게 변환(매핑)하는 과정에서 많은 문제가 발생.
2. CRUD 반복 문제
객체 지향 프로그래밍에서 관계형 데이터베이스와 상호작용할 때 리소스별 CRUD 작업을 반복적으로 작성해야 하는 문제가 자주 발생합니다.
예제 상황
애플리케이션에 User, Product, Order라는 객체가 존재.
각각의 객체에 대해 CRUD(Create, Read, Update, Delete) 작업이 필요.
문제점
반복적인 SQL 작성:
각 리소스마다 유사한 SQL 쿼리(CRUD)를 작성해야 함.
예:
INSERT INTO users ...
SELECT * FROM users ...
UPDATE users SET ...
DELETE FROM users WHERE ...
코드 중복:
객체를 저장하거나 읽을 때 매번 SQL을 수동으로 작성해야 하며, 이 과정에서 비슷한 코드가 반복됨.
유지보수 어려움:
리소스가 추가되거나 변경될 때, 관련 SQL이나 매핑 코드를 모두 수정해야 함.
변경에 따른 리스크:
데이터베이스 스키마가 변경되면, 관련된 모든 CRUD 코드를 수정해야 하므로 버그 발생 가능성이 증가.
INSERT, UPDATE, SELECT, DELETE
Java Object to SQL
SQL to Java Object
패러다임 불일치 문제
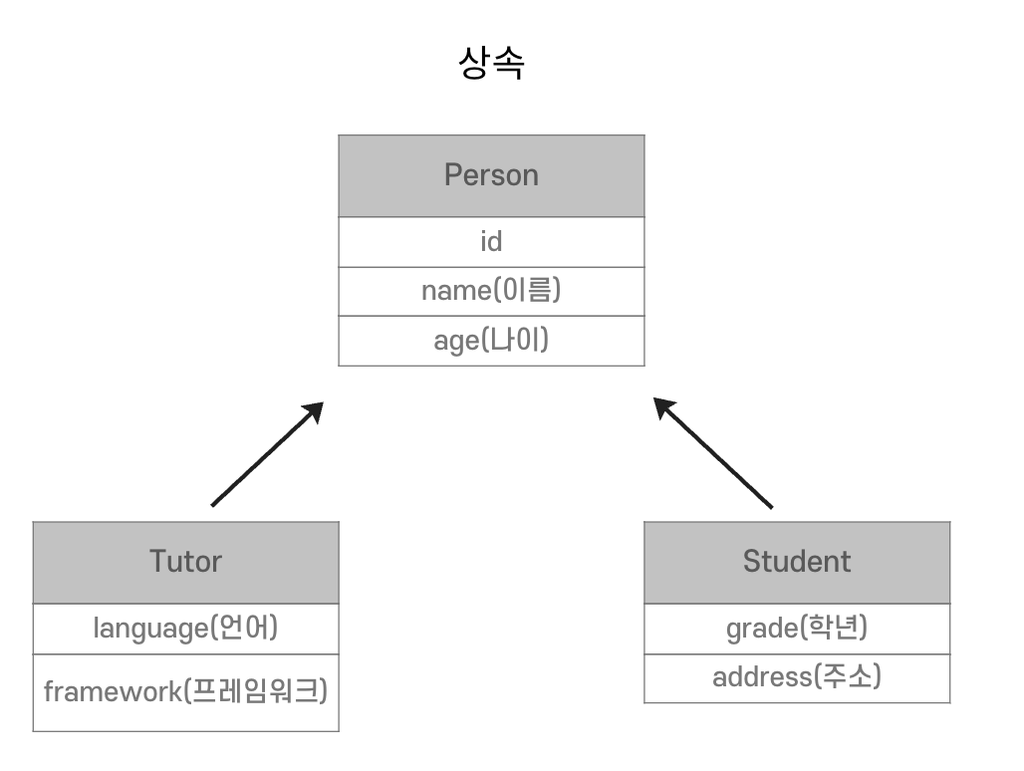
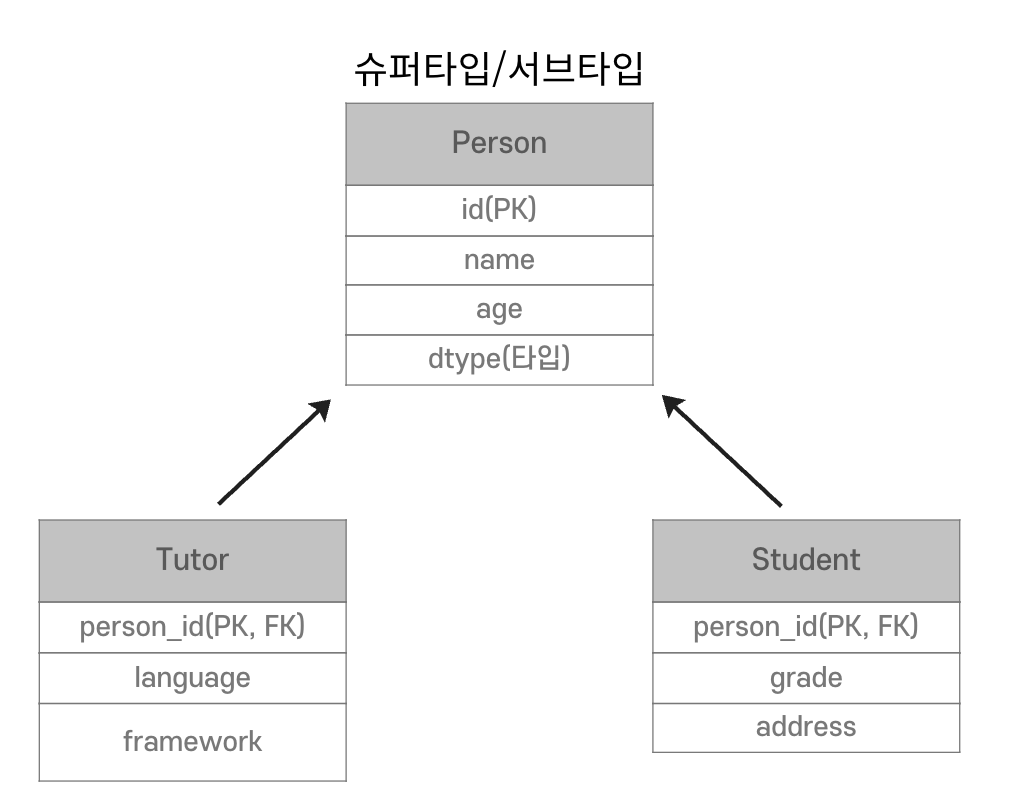
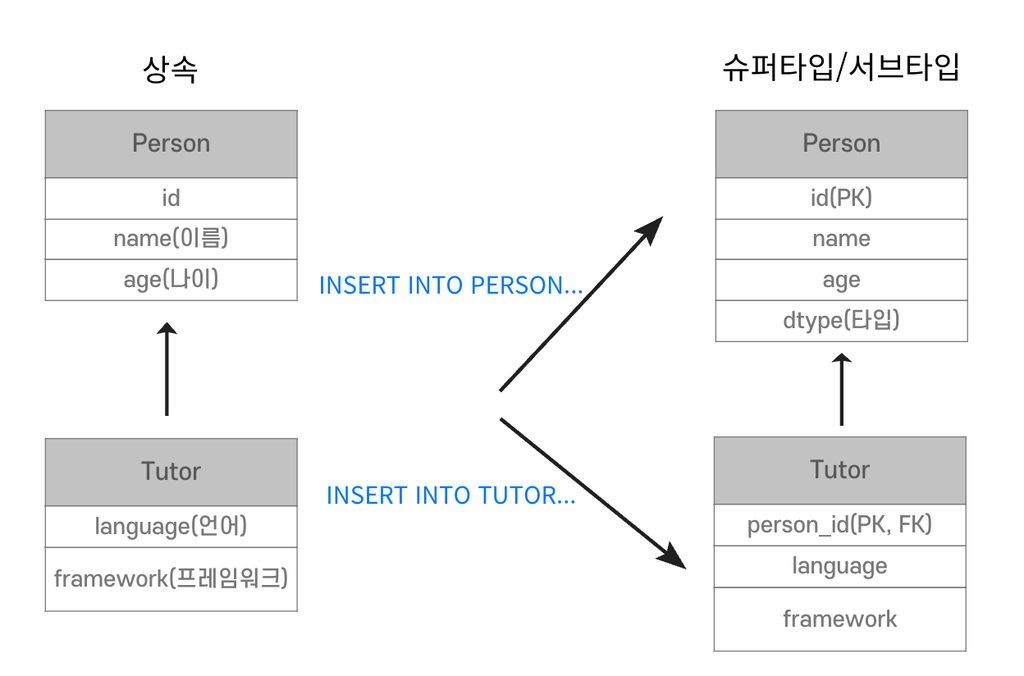
📌 객체에서는 상속과 다형성을 통해 객체 관계를 표현할 수 있지만 RDB는 이 개념을 직접 지원하지 않고 별도 매핑이 필요하다. 또한, 객체는 참조로 관계를 표현하고 RDB는 JOIN을 사용하여 관계를 결합한다.
상속
DB는 상속관계가 없다.
관계형 DB에서는 Data를 슈퍼타입, 서브타입 관계로 설정한다.
Tutor 저장
Tutor 조회
각각의 객체별로 JOIN SQL 작성, 객체 생성 및 데이터 세팅이 필요하다.
까다롭기 때문에 DB에 저장할 객체는 상속 관계를 사용하지 않는다.
연관관계
📌 테이블의 연관관계는 외래 키를 사용한다.
📌객체의 연관관계는 참조를 사용한다
연관탐색
📌 객체 지향 언어에서 데이터와 동작을 함께 캡슐화하는 방식과, RDB가 데이터를 정규화된 테이블에 관계 중심으로 저장하는 방식의 차이에서 발생한다. 이로 인해 객체를 데이터베이스에 저장하거나 조회할 때 복잡한 매핑과 변환이 필요해지고 코드의 복잡성과 개발자의 부담이 증가한다.
**정규화(Normalization)**는 관계형 데이터베이스 설계에서 데이터를 중복 없이 체계적으로 저장하기 위해 데이터를 여러 테이블로 나누고, 각 테이블 간에 적절한 관계를 정의하는 과정입니다.
상속과 유사한 관계의 데이터베이스를 구축한 경우 상위 아키텍처는 다음 계층을 믿고 사용가능해야한다.
Entity가 믿고 쓸 수 있는 상속인지 확인해야한다. productRepository.findById();의 신뢰성 확인이 필요하다.
📌 애플리케이션 전반에 걸쳐 여러 모듈이나 레이어에서 공통적으로 필요하지만, 특정 비즈니스 로직과 직접적으로 관련이 없는 기능을 의미합니다.
이러한 기능은 여러 곳에서 반복적으로 사용되며, 코드 중복을 초래하거나 모듈 간의 결합도를 높이는 원인이 될 수 있습니다.
같은 말로 횡단 관심사 라고 하며 여러 위치에서 공통적으로 사용되는 부가 기능이고 Filter가 나오게된 이유는 공통 관심사(Cross Cutting Concern)의 처리 때문이다.
요구사항 : 로그인 한 유저만 특정 API를 사용할 수 있어야 한다.
해결방법
언제나 핵심은 수정에 있다!
화면에서 로그인 하지 않으면 API를 사용하지 못하도록 막는다.
유저가 HTTP 요청을 마음대로 조작할 수 있다.
Controller에서 로그인 여부를 체크하는 Logic을 작성한다.
실제로는 인증이 필요한 모든 컨트롤러에 공통으로 로그인 여부를 체크해야 한다.
로그인 로직이 변경될 때 마다 로그인 여부를 체크하는 Logic 또한 변경될 가능성이 높다.
@RestController
@RequestMapping("/post")
public class PostController {
@PostMapping
public PostResponseDto create(PostCreateRequestDto request) {
// 로그인 여부 확인 로직
// 생성 로직
}
@PutMapping("/{postId}")
public void update(
@PathVariable Long postId,
PostUpdateRequestDto request
) {
// 로그인 여부 확인 로직
// 수정 로직
}
@DeleteMapping("/{postId}")
public void delete(@PathVariable Long postId) {
// 로그인 여부 확인 로직
// 삭제 로직
}
}
위와같이 여러가지 로직에서 공통으로 관심이 있는 부분을 공통 관심사 라고 한다.
로그인 여부 확인 로직 -> 공통 관심사 (인증 : 로그인)
공통 관심사는 로그인뿐만 아니라 더 큰범위를 의미한다.
Spring AOP를 활용할 수 있다.
Web과 관련된 공통 관심사는 Servlet Filter나 Spring Intercepter를 사용한다.
HttpServletRequest 객체를 제공하기 때문에 HTTP 정보나 URL 정보에 접근하기 쉽다.
ex) HTTP Header Cookie → 인증
ex ) 특정 URL의 요청은 인증을 할것이다. → URL 정보 필요
Spring AOP(Aspect-Oriented Programming, 관점 지향 프로그래밍)
📌 로깅, 보안, 트랜잭션 관리 등과 같은 횡단 관심사를 개별적인 Aspect(관점)로 모듈화할 수 있도록 합니다.
이를 통해 핵심 비즈니스 로직과 부가적인 로직을 분리하여 코드의 가독성과 유지보수성을 높일 수 있습니다.
반복되는 공통 작업(예: 로깅, 보안, 트랜잭션 관리)을 한 곳에 모아서 관리할 수 있게 도와준다. 예를 들어 모든 메서드 실행 전에 로그를 냄기는 경우, 각 메서드에 System.out.println()을 넣는 대신, AOP로 한번만 설정하면 알아서 모든 메서드에 적용된다.
Spring AOP의 주요 개념
Aspect(관점)
횡단 관심사를 정의한 모듈입니다. 예: 로그 기록, 트랜잭션 관리.
Join Point(조인 포인트)
애플리케이션 실행 과정에서 Aspect를 적용할 수 있는 지점입니다. 예: 메서드 호출, 예외 발생.
Advice(어드바이스)
Join Point에서 실행되는 작업(Aspect의 구체적인 동작)입니다. Advice는 다음과 같이 구분됩니다:
Before: 메서드 실행 전에 실행.
After: 메서드 실행 후에 실행.
Around: 메서드 실행 전후에 실행.
After Returning: 메서드가 정상적으로 반환된 후 실행.
After Throwing: 메서드 실행 중 예외가 발생한 후 실행.
Pointcut(포인트컷)
Advice가 적용될 Join Point를 정의하는 표현식입니다.
Weaving(위빙)
Aspect를 애플리케이션의 대상 객체에 적용하는 과정입니다. Spring AOP에서는 런타임 위빙이 일반적으로 사용됩니다.
Spring AOP 특징
Spring AOP는 프록시 기반으로 동작합니다.
런타임 기반 AOP를 지원하며, Java 동적 프록시나 CGLIB를 사용합니다.
메서드 호출 수준의 AOP를 제공합니다. (클래스 내부의 필드 변경 등에는 적용되지 않음)
Spring AOP 사용 방법
1. 의존성 추가 Spring AOP를 사용하려면 Maven 또는 Gradle에 관련 의존성을 추가합니다:
📌 Java Servlet에서 HTTP 요청과 응답을 중간에서 처리, 이를 기반으로 다양한 처리 작업을 수행하는 데 사용되는 Interface이다.
클라이언트 → 요청 → 필터 → 서블릿/JSP → 응답 → 필터 → 클라이언트
Filter Interface의 사용 사례
인증(Authentication) 및 권한 부여(Authorization):
특정 페이지에 접근하려는 클라이언트를 필터에서 확인하고, 인증되지 않은 사용자라면 로그인 페이지로 리디렉션.
로깅(Logging):
요청의 정보를 기록(예: 요청 URL, 클라이언트 IP, 요청 시간 등).
데이터 유효성 검사:
클라이언트의 요청 데이터를 확인하고, 잘못된 값이 있으면 필터 단계에서 차단.
응답 데이터 변환:
서버의 응답 데이터를 필터에서 압축하거나 특정 포맷(예: JSON)으로 변환.
보안 처리:
HTTP 요청의 헤더를 검사해 보안 위협(예: XSS, CSRF)을 탐지 및 차단.
jakarta.servlet.Filter
Filter Interface를 Implements하여 구현하고 Bean으로 등록하여 사용한다.
Servlet Container가 Filter를 Singleton 객체로 생성 및 관리한다.
주요 메서드
init()
Filter를 초기화하는 메서드이다.
Servlet Container가 생성될 때 호출된다.
default ****method이기 때문에 implements 후 구현하지 않아도 된다.
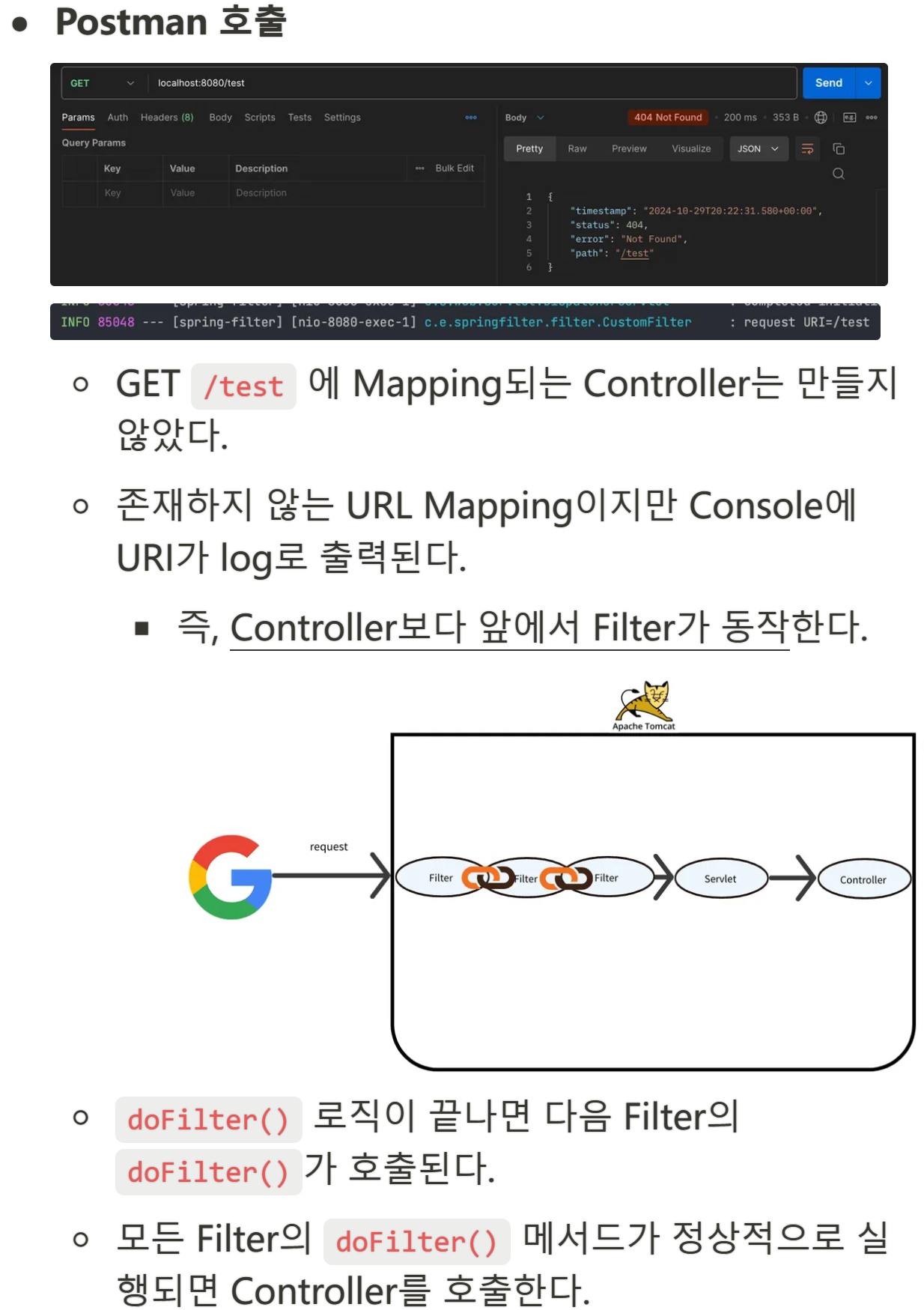
doFilter()
Client에서 요청이 올 때 마다 doFilter() 메서드가 호출된다.
doFilter() 내부에 필터 로직(공통 관심사 로직)을 구현하면 된다.
WAS에서 doFilter() 를 호출해주고 하나의 필터의 doFilter()가 통과된다면
Filter Chain에 따라서 순서대로 doFilter() 를 호출한다.
더이상 doFilter() 를 호출할 Filter가 없으면 Servlet이 호출된다.
destroy()
필터를 종료하는 메서드이다.
Servlet Container가 종료될 때 호출된다.
default method이기 때문에 implements 후 구현하지 않아도 된다.
Servlet Filter 구현
Filter 구현체
요청 URL을 Log로 출력하는 Filter
@Slf4j
public class CustomFilter implements Filter {
@Override
public void doFilter(
ServletRequest request,
ServletResponse response,
FilterChain chain
) throws IOException, ServletException {
// Filter에서 수행할 Logic
HttpServletRequest httpRequest = (HttpServletRequest) request;
String requestURI = httpRequest.getRequestURI();
log.info("request URI={}", requestURI);
// chain 이 없으면 Servlet을 바로 호출
chain.doFilter(request, response);
}
}
doFilter() 는 더 이상 호출할 Filter가 없다면 Servlet을 호출한다.
ServletRequest 는 기능이 별로 없어서 대부분 기능이 많은 HttpServletRequest 를 다운 캐스팅 하여 사용한다.
Filter 등록
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public FilterRegistrationBean customFilter() {
FilterRegistrationBean<Filter> filterRegistrationBean = new FilterRegistrationBean<>();
// Filter 등록
filterRegistrationBean.setFilter(new CustomFilter());
// Filter 순서 설정
filterRegistrationBean.setOrder(1);
// 전체 URL에 Filter 적용
filterRegistrationBean.addUrlPatterns("/*");
return filterRegistrationBean;
}
}
setFilter()
등록할 필터를 파라미터로 전달하면 된다.
setOrder()
Filter는 Chain 형태로 동작한다.
즉, 실행될 Filter들의 순서가 필요하다.
파라미터로 전달될 숫자에 따라 우선순위가 정해진다.
숫자가 낮을수록 우선순위가 높다.
addUrlPatterns()
필터를 적용할 URL 패턴을 지정한다.
여러개 URL 패턴을 한번에 지정할 수 있다.
규칙은 Servlet URL Pattern과 같다.
filterRegistrationBean.addUrlPatterns("/*")
모든 Request는 Custom Filter를 항상 지나간다.
Spring이 제공하는 URL Pattern은 Servlet과 다르게 더욱 세세하게 설정할 수 있다.
Servlet Filter 정리
Filter를 사용하려면 Filter Interface를 Implements 하여 구현한다.
구현한 Filter를 Bean으로 등록 한다.
HTTP 요청이 오면 doFilter() 메서드가 호출된다.
ServletRequest는 기능이 별로 없어서 HttpServletRequest로 다운 캐스팅 해야한다.