객체와 관계형 데이터베이스
📌 객체는 클래스를 통해 만들어지며 속성(field)와 기능(method)를 포함하며 관계형 데이터베이스는 데이터를 테이블 형식으로 표현하며 각 테이블은 열(column)과 행(row)으로 구성된다.
객체 지향 언어 Java
- 객체를 저장할 수 있는 다양한 종류의 Database
- RDB(무결성, 일관성)
- NoSQL
- File
- 기타 등등..
- 관계형 데이터베이스와 객체 지향의 패러다임 불일치 문제가 발생한다.
관계형 DB에 객체 저장 시 발생하는 문제점
1. 관계형 DB와 객체 간의 구조적 차이
- 객체 지향 vs. 관계형 모델:
- 객체지향 언어(Java, Python 등)는 객체를 중심으로 설계되며, 상태(필드)와 행동(메서드)을 결합.
- 관계형 데이터베이스는 테이블과 행(row)을 기반으로 데이터를 저장하며, 테이블 간 관계(Primary Key, Foreign Key)를 정의.
- 데이터 표현 차이:
- 객체는 복잡한 데이터 구조를 포함할 수 있지만, 데이터베이스 테이블은 정규화된 단순 구조로 데이터를 저장.
- 매핑 복잡성:
- 객체를 RDB 테이블에 맞게 변환(매핑)하는 과정에서 많은 문제가 발생.

2. CRUD 반복 문제
객체 지향 프로그래밍에서 관계형 데이터베이스와 상호작용할 때 리소스별 CRUD 작업을 반복적으로 작성해야 하는 문제가 자주 발생합니다.
예제 상황
- 애플리케이션에 User, Product, Order라는 객체가 존재.
- 각각의 객체에 대해 CRUD(Create, Read, Update, Delete) 작업이 필요.
문제점
- 반복적인 SQL 작성:
- 각 리소스마다 유사한 SQL 쿼리(CRUD)를 작성해야 함.
- 예:
- INSERT INTO users ...
- SELECT * FROM users ...
- UPDATE users SET ...
- DELETE FROM users WHERE ...
- 코드 중복:
- 객체를 저장하거나 읽을 때 매번 SQL을 수동으로 작성해야 하며, 이 과정에서 비슷한 코드가 반복됨.
- 유지보수 어려움:
- 리소스가 추가되거나 변경될 때, 관련 SQL이나 매핑 코드를 모두 수정해야 함.
- 변경에 따른 리스크:
- 데이터베이스 스키마가 변경되면, 관련된 모든 CRUD 코드를 수정해야 하므로 버그 발생 가능성이 증가.
INSERT, UPDATE, SELECT, DELETE
- Java Object to SQL
- SQL to Java Object
패러다임 불일치 문제
📌 객체에서는 상속과 다형성을 통해 객체 관계를 표현할 수 있지만 RDB는 이 개념을 직접 지원하지 않고 별도 매핑이 필요하다. 또한, 객체는 참조로 관계를 표현하고 RDB는 JOIN을 사용하여 관계를 결합한다.
상속
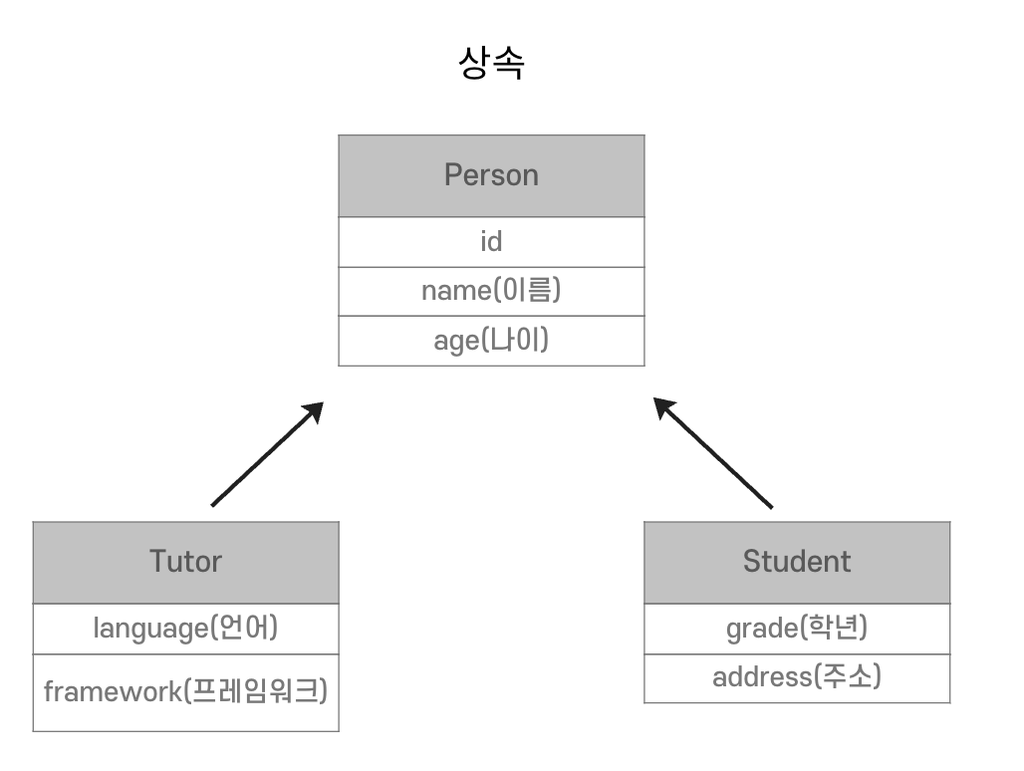
DB는 상속관계가 없다.
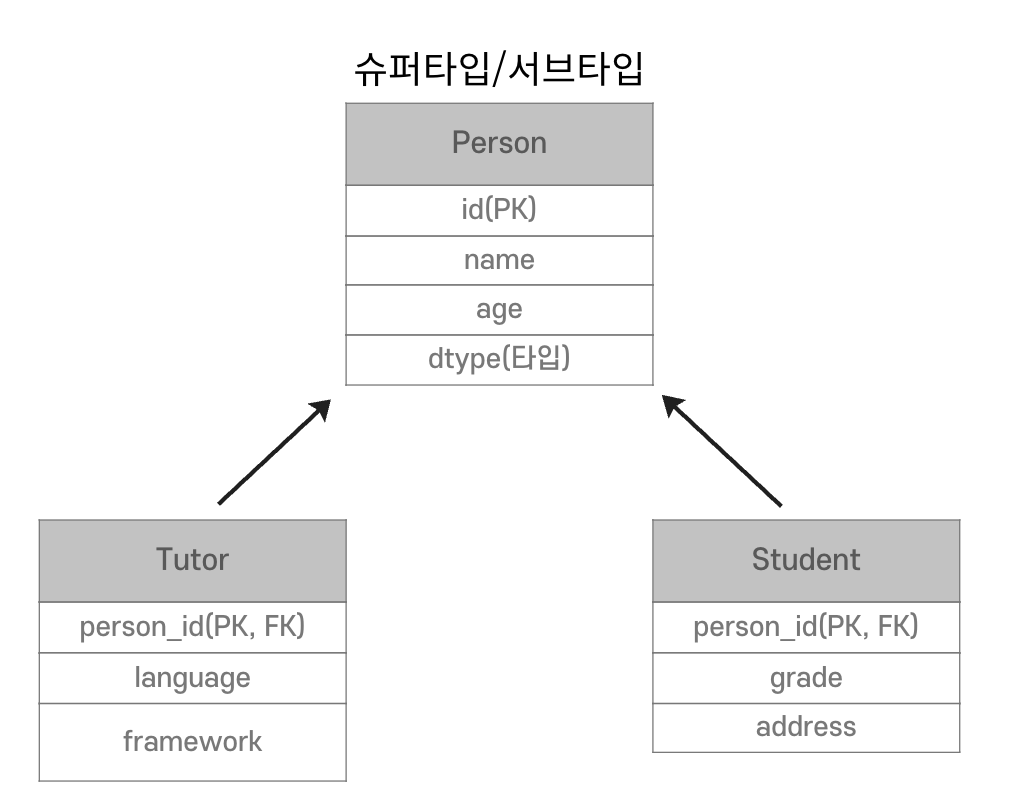
관계형 DB에서는 Data를 슈퍼타입, 서브타입 관계로 설정한다.
- Tutor 저장
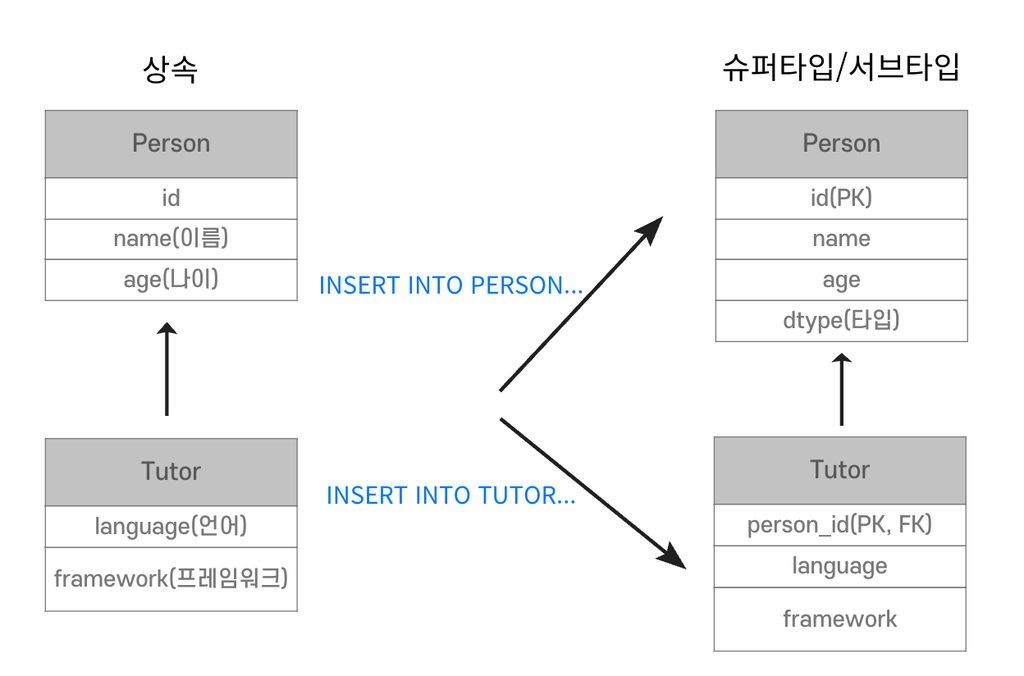
- Tutor 조회
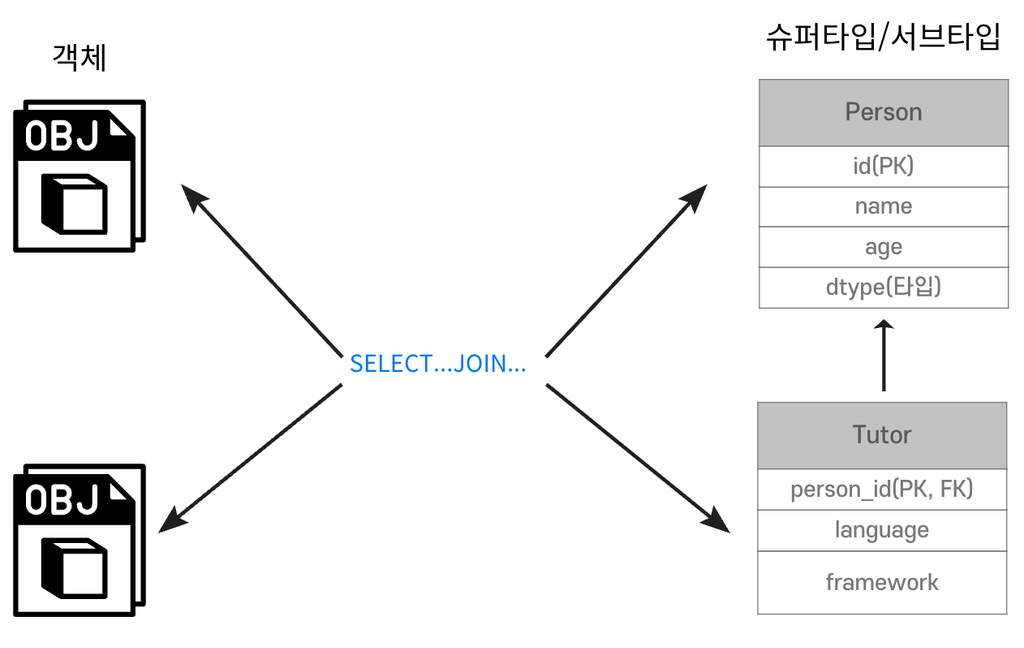
- 각각의 객체별로 JOIN SQL 작성, 객체 생성 및 데이터 세팅이 필요하다.
- 까다롭기 때문에 DB에 저장할 객체는 상속 관계를 사용하지 않는다.
연관관계
📌 테이블의 연관관계는 외래 키를 사용한다.

📌 객체의 연관관계는 참조를 사용한다

연관탐색
📌 객체 지향 언어에서 데이터와 동작을 함께 캡슐화하는 방식과, RDB가 데이터를 정규화된 테이블에 관계 중심으로 저장하는 방식의 차이에서 발생한다. 이로 인해 객체를 데이터베이스에 저장하거나 조회할 때 복잡한 매핑과 변환이 필요해지고 코드의 복잡성과 개발자의 부담이 증가한다.
| **정규화(Normalization)**는 관계형 데이터베이스 설계에서 데이터를 중복 없이 체계적으로 저장하기 위해 데이터를 여러 테이블로 나누고, 각 테이블 간에 적절한 관계를 정의하는 과정입니다. |
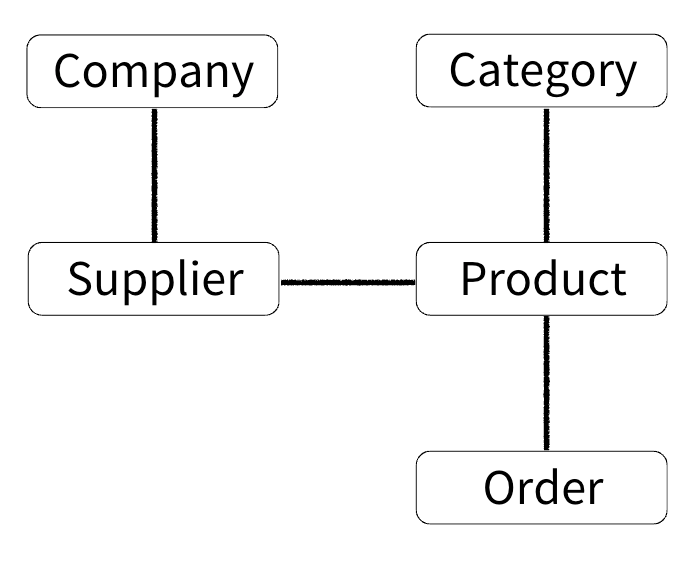
- 상속과 유사한 관계의 데이터베이스를 구축한 경우 상위 아키텍처는 다음 계층을 믿고 사용가능해야한다.
- Entity가 믿고 쓸 수 있는 상속인지 확인해야한다. productRepository.findById();의 신뢰성 확인이 필요하다.
- 매번 신뢰성 확인이 필요하니 SQL Query가 굉장히 무거워진다.
- 진정한 의미의 계층 분할이 어렵다.
- 필요 없는 데이터도 항상 함께 조회된다. (연관된거 싹다 들고온다)

객체의 비교
Product product1 = productRepository.findById(productId);
Product product2 = productRepository.findById(productId);
product1 == product2; // false- 데이터는 같지만, 새로운 인스턴스기 때문에 객체의 주소값이 다르다.
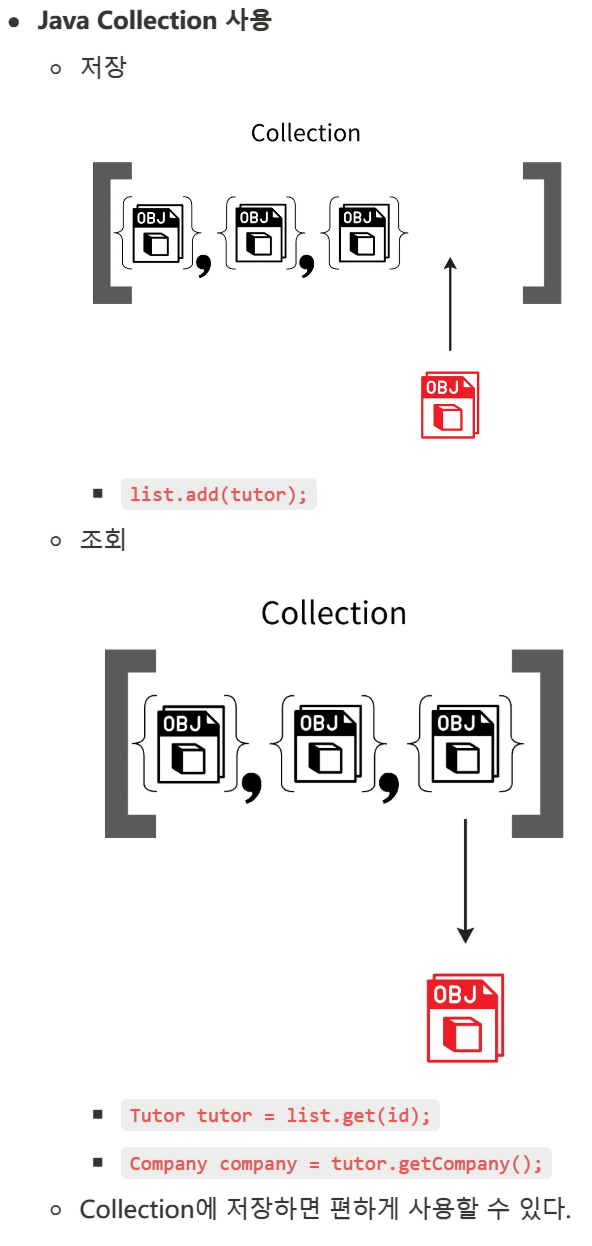
결론
- 객체 지향적으로 설계하면 코드가 점점 복잡해진다.
- SQL Query, Mapping이 까다롭다.
- Collection처럼 객체가 관리된다면 편리해진다.
// Entity 신뢰 가능
Product product = list.get(productId);
Category category = product.getCategory();
// 비교 가능
Product product1 = list.get(productId);
Product product2 = list.get(productId);
product1 == product2; // true- JPA(Java Persistence API) 등장
- 마치 Java의 Collection처럼 객체를 저장하고 사용할 수 있게 해준다.
- JPA를 사용하면 패러다임 불일치 문제를 모두 해결할 수 있다.
'DB > JPA ( Java Persistence API )' 카테고리의 다른 글
| [JPA] 연관관계 (0) | 2025.01.12 |
|---|---|
| [JPA] Spring Data JPA (0) | 2025.01.07 |
| [JPA] 연관관계 Mapping (0) | 2025.01.06 |
| [JPA] Entity (1) | 2025.01.05 |
| [JPA] 영속성 컨텍스트 (2) | 2025.01.04 |