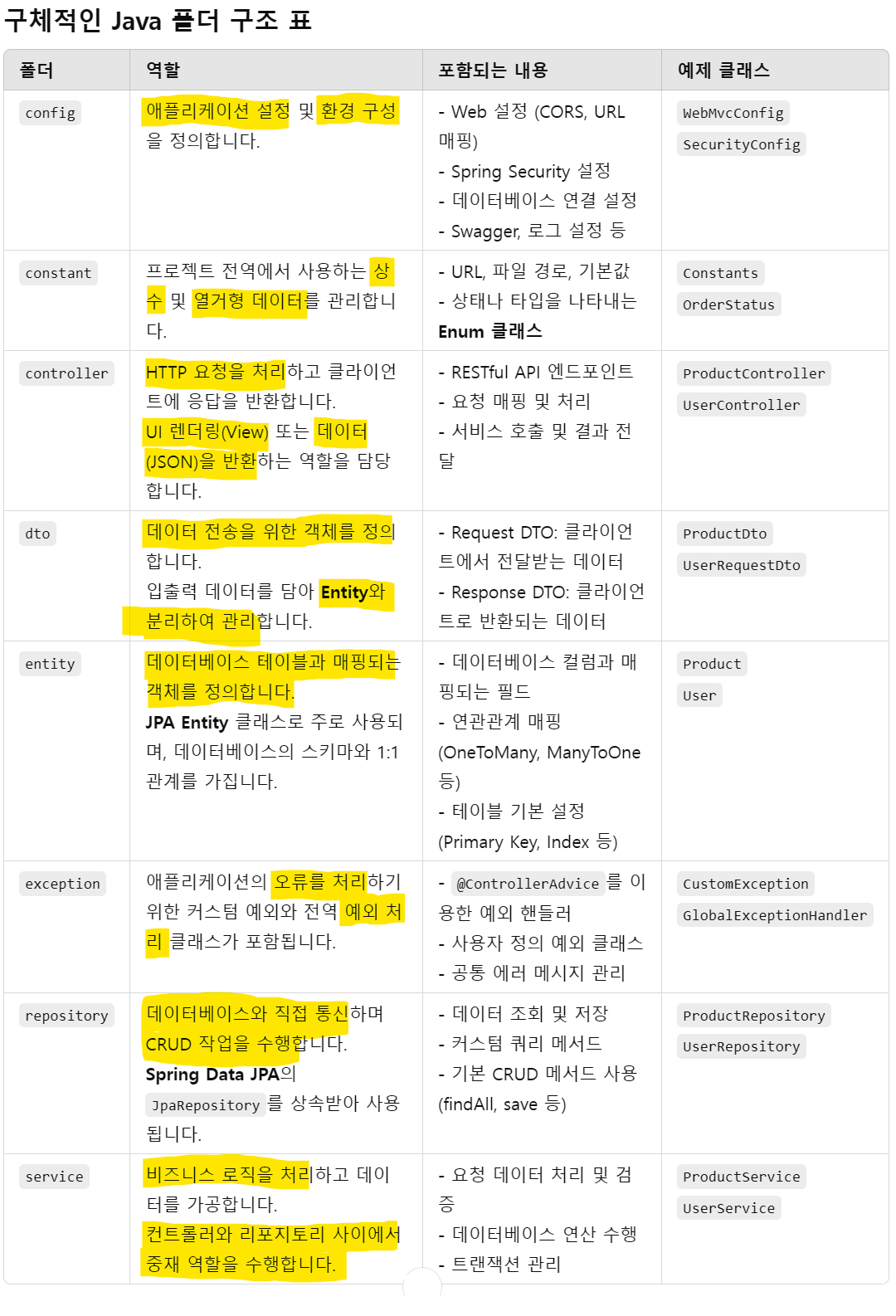
[Elasticsearch Config]
package com.example.coupang.search.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.TransportUtils;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 🛠 ElasticsearchConfig
* Elasticsearch 연결을 위한 Spring Boot 설정 클래스
*/
@Configuration // 📌 Spring에서 이 클래스를 설정(Configuration) 클래스로 인식하도록 함
public class ElasticsearchConfig {
// 📌 application.properties 또는 application.yml에서 값을 가져옴
@Value("${elasticsearch.host}")
private String host; // Elasticsearch 호스트 (예: "localhost" 또는 "127.0.0.1")
@Value("${elasticsearch.port}")
private Integer port; // Elasticsearch 포트 (보통 9200)
@Value("${elasticsearch.username}")
private String username; // Elasticsearch 인증을 위한 사용자명
@Value("${elasticsearch.password}")
private String password; // Elasticsearch 인증을 위한 비밀번호
@Value("${elasticsearch.fingerprint:}") // 기본값을 빈 문자열("")로 설정
private String fingerprint; // (옵션) 보안 인증을 위한 SSL fingerprint
private final ObjectMapper objectMapper;
/**
* 🔹 생성자 주입 방식으로 ObjectMapper를 받음
* - `JavaTimeModule`을 등록하여 LocalDateTime 직렬화를 지원
*/
public ElasticsearchConfig(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
this.objectMapper.registerModule(new JavaTimeModule()); // ✅ Java 날짜/시간 타입(LocalDateTime) 지원
}
/**
* 🛠 ElasticsearchClient Bean 생성
* - Elasticsearch 서버와의 연결을 위한 Java API 클라이언트 객체 생성
* - 보안 인증 및 JSON 직렬화를 설정
*/
@Bean
public ElasticsearchClient elasticsearchClient() {
// 🔹 기본 인증을 위한 `CredentialsProvider` 객체 생성
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// 🔹 RestClient를 생성하여 Elasticsearch 서버와 HTTP 통신을 담당
RestClient restClient = RestClient.builder(new HttpHost(host, port, "http")) // HTTP 프로토콜로 연결
.setHttpClientConfigCallback(httpClientBuilder -> {
if (fingerprint != null && !fingerprint.isEmpty()) {
// 🔹 SSL 인증서 검증을 위한 컨텍스트 설정 (SSL fingerprint 기반 보안)
httpClientBuilder = httpClientBuilder.setSSLContext(
TransportUtils.sslContextFromCaFingerprint(fingerprint)
);
}
// 🔹 기본 인증 (Username/Password) 적용
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
})
.build(); // 최종 RestClient 객체 생성
// 🔹 JSON 직렬화를 위해 Jackson 기반의 JSON Mapper 생성
JacksonJsonpMapper jacksonJsonpMapper = new JacksonJsonpMapper(objectMapper);
// 🔹 ElasticsearchTransport 객체 생성
ElasticsearchTransport transport = new RestClientTransport(restClient, jacksonJsonpMapper);
// 🔹 ElasticsearchClient 객체 생성 및 반환
return new ElasticsearchClient(transport);
}
}
[Elasticsearch Service]
package com.example.coupang.search.service;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
// Elasticsearch Java API Client. Elasticsearch와 통신하는 핵심 클래스
import co.elastic.clients.elasticsearch._types.ElasticsearchException;
import co.elastic.clients.elasticsearch._types.query_dsl.DisMaxQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.MatchPhraseQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.MatchQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.Query;
import co.elastic.clients.elasticsearch.core.DeleteByQueryRequest;
import co.elastic.clients.elasticsearch.core.DeleteByQueryResponse;
import co.elastic.clients.elasticsearch.core.SearchRequest;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.*;
import com.example.coupang.search.entity.SearchKeyword;
// 검색 키워드 정보를 담는 Elasticsearch 문서(Entity) 클래스
import com.example.coupang.search.repository.SearchKeywordRepository;
// Spring Data Elasticsearch 리포지토리. CRUD 기능 제공
import co.elastic.clients.elasticsearch._types.aggregations.TermsAggregationExecutionHint;
// Terms Aggregation 최적화(실행 힌트) 지정용 enum
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.time.LocalDateTime;
import java.util.*;
import java.util.stream.Collectors;
/**
* 🛠 SearchService
* Elasticsearch를 활용한 검색/저장/조회 기능을 제공하는 서비스 클래스
*/
@Slf4j // (Lombok) 로깅 기능 추가 -> log.info(), log.error() 등 메서드 사용 가능
@RequiredArgsConstructor // (Lombok) final 필드만 포함된 생성자를 자동 생성
@Service // Spring Service 계층으로 스캔되어 빈(Bean) 등록
public class SearchService {
// ▶ Spring Data Elasticsearch 리포지토리 주입
private final SearchKeywordRepository searchKeywordRepository;
// ▶ Elasticsearch Java API Client 주입
private final ElasticsearchClient client;
// ▶ Elasticsearch 인덱스명 지정
private static final String INDEX_NAME = "search_keywords";
// ---------------------------------------------------------------------
// 1. 검색어 저장/업데이트 기능
// ---------------------------------------------------------------------
/**
* 검색어를 저장하거나 업데이트합니다.
* 이미 존재하면 검색 횟수를 증가시키고, 없으면 새로 생성합니다.
*
* @param searchIc (임의) 검색 요청 고유 식별자
* @param searchText 실제 검색 문자열
* @return 저장된 SearchKeyword 객체
*/
public SearchKeyword saveOrUpdateSearchKeyword(String searchIc, String searchText) {
// 🔹 기존에 같은 검색어가 있는지 확인
SearchKeyword keyword = searchKeywordRepository.findBySearchText(searchText);
if (keyword != null) {
// 🔹 이미 존재한다면 count(검색 횟수) +1 증가
keyword.setCount(keyword.getCount() + 1);
} else {
// 🔹 존재하지 않으면 새로 생성 후 기본값 설정
keyword = new SearchKeyword();
keyword.setSearchIc(searchIc);
keyword.setSearchText(searchText);
keyword.setCount(1);
keyword.setTimestamp(LocalDateTime.now());
}
// 🔹 생성 또는 업데이트된 검색어를 Elasticsearch 인덱스에 저장
return searchKeywordRepository.save(keyword);
}
// ---------------------------------------------------------------------
// 2. 인기 검색어 조회 기능 (Aggregation 이용)
// ---------------------------------------------------------------------
/**
* Elasticsearch Aggregation을 사용하여 인기 검색어(상위 10개)를 조회합니다.
* - "searchText.keyword" 필드를 대상으로 Terms Aggregation 수행
*/
public List<String> getPopularKeywords() throws IOException {
// 🔹 SearchRequest: Aggregation을 설정하여 popular_searches라는 이름으로 Terms Aggregation 수행
SearchRequest searchRequest = new SearchRequest.Builder()
.index("search_keywords") // 대상 인덱스
.aggregations("popular_searches", a -> a
.terms(t -> t
.field("searchText.keyword") // ✅ 검색어의 keyword 필드 사용
.size(1000))) // 상위 1000개까지 추출
.build();
// 🔹 Elasticsearch에 요청 및 응답 받기
SearchResponse<Void> response = client.search(searchRequest, Void.class);
// 🔹 Aggregation 결과에서 인기 검색어 목록 추출
List<String> popularKeywords = new ArrayList<>();
// 🔹 "popular_searches"라는 이름의 Aggregation 결과 존재 여부 확인
if (response.aggregations() != null && response.aggregations().containsKey("popular_searches")) {
// 🔹 popular_searches -> stringTerms -> buckets
response.aggregations()
.get("popular_searches")
.sterms() // StringTerms를 의미
.buckets().array() // Bucket 리스트
.forEach(bucket -> popularKeywords.add(bucket.key().stringValue()));
} else {
// 🔹 Aggregation 결과가 없을 경우
System.out.println("⚠️ Aggregation 결과가 없습니다!");
}
return popularKeywords;
}
/**
* getPopularKeywords()를 최적화한 버전
* - executionHint를 Map으로 설정하여 메모리 사용 대비 성능을 조절
*/
public List<String> getPopularKeywordsOptimized() throws IOException {
// 🔹 SearchRequest 생성 (executionHint = Map)
SearchRequest searchRequest = new SearchRequest.Builder()
.index("search_keywords")
.aggregations("popular_searches", a -> a
.terms(t -> t
.field("searchText.keyword") // keyword 필드
.size(1000) // 상위 1000개
.executionHint(TermsAggregationExecutionHint.Map))) // ✅ 실행 힌트 (Map) 적용
.build();
// 🔹 Elasticsearch에 요청 및 응답 받기
SearchResponse<Void> response = client.search(searchRequest, Void.class);
// 🔹 popular_searches Aggregation 결과 파싱
List<String> popularKeywords = new ArrayList<>();
response.aggregations()
.get("popular_searches")
.sterms()
.buckets().array()
.forEach(bucket -> popularKeywords.add(bucket.key().stringValue()));
return popularKeywords;
}
/**
* getPopularKeywords()를 더 빠르게 만든 버전
* - requestCache(true)를 통해 반복되는 쿼리에 대한 캐시 활성화
*/
public List<String> getPopularKeywordsFastest() throws IOException {
// 🔹 SearchRequest 생성 (requestCache = true)
SearchRequest searchRequest = new SearchRequest.Builder()
.index("search_keywords")
.aggregations("popular_searches", a -> a
.terms(t -> t
.field("searchText.keyword")
.size(1000)))
.requestCache(true) // ✅ 쿼리 캐싱 활성화
.build();
// 🔹 Elasticsearch에 요청 및 응답 받기
SearchResponse<Void> response = client.search(searchRequest, Void.class);
// 🔹 popular_searches Aggregation 결과 파싱
List<String> popularKeywords = new ArrayList<>();
response.aggregations()
.get("popular_searches")
.sterms()
.buckets().array()
.forEach(bucket -> popularKeywords.add(bucket.key().stringValue()));
return popularKeywords;
}
// ---------------------------------------------------------------------
// 4. 도서 검색 기능 (고급 검색 쿼리, 하이라이팅 적용)
// ---------------------------------------------------------------------
/**
* 검색어(keyword)를 이용해 Elasticsearch에서 검색을 수행
* - DisMax 쿼리로 여러 Match 쿼리를 결합해 가장 높은 스코어를 채택
* - 하이라이팅(Highlight) 적용
*
* @param keyword 사용자가 입력한 검색어
* @return 검색 결과로 매핑된 SearchKeyword 엔티티 목록
*/
public List<SearchKeyword> searchKeywords(String keyword) {
// 🔹 고정값 정의
final String INDEX = "search_keywords"; // 검색할 인덱스
final String FIELD_NAME = "searchText"; // 기본 검색 필드
final Integer SIZE = 10; // 검색 결과 최대 개수
// 🔹 boost 값 설정
final Float KEYWORD_BOOST_VALUE = 2f; // 단일 키워드 부스트
final Float PHRASE_BOOST_VALUE = 1.5f; // 문구(phrase) 부스트
final Float LANGUAGE_BOOST_VALUE = 1.2f; // 언어별 필드 부스트
final Float DEFAULT_BOOST_VALUE = 1f; // 기본 부스트
final Float PARTIAL_BOOST_VALUE = 0.5f; // 부분 매칭 부스트
// 🔹 검색어에 한글이 포함되었는지 체크 -> 필드 접미사 결정
String[] fieldSuffixes = containsKorean(keyword)
? new String[]{"", "_chosung", "_jamo"} // 한글이면 초성/자모 필드도 매칭
: new String[]{"", "_engtokor"} // 영문이면 영->한 변환 필드
// 🔹 fieldSuffix + boostValue를 함께 관리할 Map
Map<String, Float> boostValueByMultiFieldMap = Map.of(
"", KEYWORD_BOOST_VALUE, // 기본 필드 (ex: "searchText") -> boost 2
".edge", DEFAULT_BOOST_VALUE, // Edge n-gram 필드 -> boost 1
".partial", PARTIAL_BOOST_VALUE // partial 필드 -> boost 0.5
);
// 🔹 멀티 필드 MatchQuery 리스트 생성
List<Query> queryList = createMatchQueryList(fieldSuffixes, boostValueByMultiFieldMap, keyword)
.stream()
.map(MatchQuery::_toQuery) // MatchQuery를 Query로 변환
.collect(Collectors.toList());
// 🔹 언어별 필드 (한글 or 영어) 쿼리 추가
String languageField = FIELD_NAME + (containsKorean(keyword) ? ".kor" : ".en");
// Match 쿼리 (boost = 1.2f)
queryList.add(createMatchQuery(keyword, languageField, LANGUAGE_BOOST_VALUE)._toQuery());
// MatchPhrase 쿼리 (boost = 1.5f)
queryList.add(createMatchPhraseQuery(keyword, languageField, PHRASE_BOOST_VALUE)._toQuery());
// 🔹 DisMax 쿼리: 여러 개의 쿼리 중 가장 높은 스코어를 채택
DisMaxQuery disMaxQuery = new DisMaxQuery.Builder()
.queries(queryList)
.build();
// 🔹 하이라이팅 설정: 검색어 부분을 <strong> 태그로 감싸서 반환
Highlight highlight = createHighlightFieldMap(Arrays.asList(
FIELD_NAME,
FIELD_NAME + ".en",
FIELD_NAME + ".kor",
FIELD_NAME + ".edge",
FIELD_NAME + ".partial"
));
// 🔹 최종 검색 요청 구성
SearchRequest searchRequest = new SearchRequest.Builder()
.index(INDEX)
.size(SIZE)
.query(q -> q.disMax(disMaxQuery)) // DisMax 쿼리 적용
.highlight(highlight) // 하이라이팅 적용
.build();
// 🔹 Elasticsearch에 검색 요청
SearchResponse<SearchKeyword> response;
try {
response = client.search(searchRequest, SearchKeyword.class);
} catch (ElasticsearchException e) {
// 🛑 Elasticsearch에서 발생한 예외 처리
throw new RuntimeException("Elasticsearch 검색 실패", e);
} catch (IOException e) {
// 🛑 I/O 예외 처리
throw new RuntimeException("Elasticsearch I/O 실패", e);
}
// 🔹 검색 결과 수 파악
TotalHits total = response.hits().total();
boolean isExactResult = total != null && total.relation() == TotalHitsRelation.Eq;
log.info("There are {}{} results",
isExactResult ? "" : "more than ",
total != null ? total.value() : 0);
// 🔹 검색 결과 목록(Hit) -> 실제 문서(Source) 추출
List<Hit<SearchKeyword>> hits = response.hits().hits();
List<SearchKeyword> result = hits.stream()
.map(Hit::source)
.collect(Collectors.toList());
log.info("Search result: {}", result);
return result;
}
// ---------------------------------------------------------------------
// 4-1. 검색 헬퍼 메서드들
// ---------------------------------------------------------------------
/**
* 문자열에 한글이 포함되어 있는지 확인
* @param text 입력 문자열
* @return true면 한글 존재
*/
private boolean containsKorean(String text) {
return text != null && text.matches(".*[ㄱ-ㅎㅏ-ㅣ가-힣]+.*");
}
/**
* 멀티 필드에 대해 boost 값을 달리하여 MatchQuery 리스트를 생성
* @param fieldSuffixes 필드 접미사 배열
* @param boostValueByMultiFieldMap (".edge" -> 1.0, ".partial" -> 0.5 등)
* @param keyword 검색 문자열
* @return MatchQuery 리스트
*/
private List<MatchQuery> createMatchQueryList(String[] fieldSuffixes,
Map<String, Float> boostValueByMultiFieldMap, String keyword) {
// 🔹 fieldSuffixes와 boostValueByMultiFieldMap를 조합하여 MatchQuery 생성
return Arrays.stream(fieldSuffixes)
.flatMap(fieldSuffix -> boostValueByMultiFieldMap.entrySet().stream()
.map(entry ->
createMatchQuery(keyword, "searchText" + fieldSuffix + entry.getKey(), entry.getValue())
)
)
.collect(Collectors.toList());
}
/**
* 일반 MatchQuery 빌더
* @param keyword 검색어
* @param fieldName 매칭할 필드명
* @param boostValue 부스트 값
* @return MatchQuery
*/
private MatchQuery createMatchQuery(String keyword, String fieldName, Float boostValue) {
// 🔹 Elasticsearch Java API에서 제공하는 MatchQuery 빌더
return new MatchQuery.Builder()
.query(keyword)
.field(fieldName)
.boost(boostValue)
.build();
}
/**
* MatchPhraseQuery 빌더 (문구 검색)
* @param keyword 검색어
* @param fieldName 필드명
* @param boostValue 부스트 값
* @return MatchPhraseQuery
*/
private MatchPhraseQuery createMatchPhraseQuery(String keyword, String fieldName, Float boostValue) {
// 🔹 Elasticsearch Java API에서 제공하는 MatchPhraseQuery 빌더
return new MatchPhraseQuery.Builder()
.query(keyword)
.field(fieldName)
.boost(boostValue)
.build();
}
/**
* 하이라이팅 적용할 필드들의 Map을 생성
* @param fieldNames 하이라이팅 적용할 필드 목록
* @return Highlight 객체
*/
private Highlight createHighlightFieldMap(List<String> fieldNames) {
// 🔹 각 필드에 대해 <strong>, </strong> 태그로 감싸도록 설정
Map<String, HighlightField> highlightFieldMap = new HashMap<>();
for (String fieldName : fieldNames) {
highlightFieldMap.put(fieldName,
new HighlightField.Builder()
.preTags("<strong>")
.postTags("</strong>")
.build());
}
// 🔹 최종 Highlight 객체 생성
return new Highlight.Builder().fields(highlightFieldMap).build();
}
/**
* 전체 문서 삭제 (DeleteByQuery)
* @throws IOException Elasticsearch I/O 예외
*/
public void deleteAllDocuments() throws IOException {
// 🔹 DeleteByQueryRequest: matchAll() 쿼리를 사용하여 전체 삭제
DeleteByQueryRequest request = DeleteByQueryRequest.of(d -> d
.index(INDEX_NAME)
.query(q -> q.matchAll(m -> m))
);
// 🔹 DeleteByQuery 실행
DeleteByQueryResponse response = client.deleteByQuery(request);
// 🔹 삭제된 문서 수 확인
log.info("전체 문서 삭제 완료: {}건 삭제됨", response.deleted());
}
}
search_keywords 인덱스 매핑(JSON) 파일
{
"settings": {
"number_of_shards": 1, // 🔹 데이터 분산을 위한 샤드 개수 (1개 지정)
"number_of_replicas": 1, // 🔹 데이터 백업을 위한 복제본 개수 (1개 지정)
"analysis": { // 🔹 텍스트 분석기(Analyzer) 설정
"analyzer": {
"default": { // 🔹 기본(standard) 분석기 사용
"type": "standard"
}
}
}
},
"mappings": { // 🔹 문서 필드 매핑 설정
"properties": { // 🔹 각 필드의 유형 및 설정 정의
"searchIc": {
"type": "keyword" // 🔹 검색어 ID(고유 식별자) - 검색/정렬용으로 사용
},
"searchText": {
"type": "text", // 🔹 검색어 필드 (전체 텍스트 검색 가능)
"analyzer": "standard", // 🔹 기본 텍스트 분석기(standard) 사용
"fields": { // 🔹 multi-fields 설정 (추가적인 필드 변환 지원)
"keyword": { // 🔹 keyword 타입 추가 (정확한 검색, 집계 가능)
"type": "keyword",
"ignore_above": 256 // 🔹 256자 이상은 무시
}
}
},
"count": {
"type": "integer" // 🔹 검색 횟수를 저장하는 필드
},
"timestamp": {
"type": "date", // 🔹 검색어 저장 시각을 기록하는 필드
"format": "uuuu-MM-dd'T'HH:mm:ss||uuuu-MM-dd'T'HH:mm:ss.SSS"
// 🔹 다양한 날짜 형식 지원 (ISO-8601 표준)
},
"suggest": {
"type": "completion", // 🔹 자동완성 기능을 위한 Completion 필드
"analyzer": "simple", // 🔹 기본 분석기(simple): 공백 기준으로 나누고 소문자로 변환
"preserve_separators": true, // 🔹 단어 구분자(예: 띄어쓰기, '-' 등) 유지 여부
"preserve_position_increments": true, // 🔹 단어 위치 보존 (중간 단어도 검색 가능)
"max_input_length": 50, // 🔹 자동완성 대상 문자열의 최대 길이 (50자)
"contexts": [ // 🔹 컨텍스트 필터링 지원 (예: 특정 카테고리만 추천)
{
"name": "category", // 🔹 필터링할 컨텍스트 필드명
"type": "category" // 🔹 카테고리 필터 사용
}
]
}
}
}
}
🔹 Elasticsearch를 활용한 검색어 자동완성 및 인기 검색어 분석 프로젝트 발표
1️⃣ 프로젝트 개요
이번 프로젝트에서는 Elasticsearch를 활용한 검색어 자동완성 및 인기 검색어 분석 시스템을 구축했습니다.
사용자가 검색창에 입력하는 검색어를 실시간으로 추천하고, 검색 빈도를 분석하여 인기 검색어를 제공하는 기능을 구현했습니다.
이를 위해 Elasticsearch의 Completion Suggester, 역인덱싱(Reverse Indexing), 샤드(Shards)와 복제본(Replicas) 설정,
그리고 다양한 분석기(Analyzer)를 적용하여 검색 성능을 최적화했습니다.
2️⃣ 프로젝트 목표
✅ 1. 실시간 검색어 자동완성 기능
- 사용자가 검색창에 입력할 때, 입력된 일부 문자만으로도 적절한 검색어 추천
- 검색어 추천 시 카테고리별 필터링 지원 (예: "아이폰" 입력 시 "아이폰 14", "아이폰 Pro" 추천)
- 검색어의 자동완성 속도를 높이기 위해 Completion Suggester 적용
✅ 2. 인기 검색어 분석 기능
- 최근 사용자가 많이 검색한 상위 검색어 리스트 제공
- Elasticsearch의 Aggregation(집계) 기능을 활용하여 검색 빈도 분석
- 검색 빈도를 기반으로 검색 추천 결과에 가중치 부여 (검색 횟수가 많을수록 높은 우선순위)
✅ 3. 성능 최적화
- 역인덱싱(Reverse Indexing) 방식으로 검색 속도 향상
- 샤드(Shard)와 복제본(Replica)를 조정하여 확장성 및 장애 대응력 확보
- Ngram(엔그램), Edge Ngram 분석기를 적용하여 유사 검색어 추천 최적화
3️⃣ 프로젝트 아키텍처
🔹 데이터 저장 및 검색 구조
Elasticsearch는 역인덱싱(Reverse Indexing) 구조를 활용하여 데이터를 저장하고 빠르게 검색합니다.
데이터 저장 시, 일반적인 관계형 데이터베이스(RDBMS)의 행(row) 기반 저장 방식이 아니라,
각 문서(document)에 대해 토큰화(tokenizing) 및 색인(indexing) 과정을 거쳐 검색 속도를 높입니다.
🔹 역인덱싱(Reverse Indexing)
- 일반적인 데이터베이스에서는 특정 데이터를 검색하려면 **전체 데이터를 탐색(Sequential Scan)**해야 합니다.
- 하지만 Elasticsearch는 역인덱싱(Reverse Indexing) 방식을 사용하여 검색 속도를 획기적으로 향상시킵니다.
- 예를 들어, "아이폰 14 프로"라는 검색어가 저장될 때:
{ "아이폰": [1], "14": [1], "프로": [1] }- 각 단어를 키로 삼고, 해당 단어가 등장하는 문서 ID를 저장하는 방식으로 색인이 구축됨.
- 검색 시 특정 단어가 포함된 문서를 즉시 조회할 수 있어 검색 속도가 매우 빠름.
4️⃣ 주요 기능 및 기술 적용
🔹 1. Elasticsearch 인덱스 매핑 및 샤드(Shard) 설정
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"searchText": {
"type": "text",
"analyzer": "standard",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"suggest": {
"type": "completion",
"analyzer": "simple",
"contexts": [
{
"name": "category",
"type": "category"
}
]
}
}
}
}
📌 적용된 기술
- 샤드(Shards): number_of_shards: 1
- 단일 노드에서 운영되므로 샤드 개수를 1로 설정.
- 검색 성능 최적화를 위해 추후 클러스터 확장 가능하도록 설계.
- 복제본(Replicas): number_of_replicas: 1
- 가용성을 높이기 위해 복제본을 1개 추가 (장애 발생 시 자동 복구 가능).
- Completion Suggester 적용: "suggest" 필드를 completion 타입으로 설정.
- 자동완성 추천을 빠르게 제공하기 위해 적용.
🔹 2. 검색어 자동완성 기능 (Completion Suggester 활용)
사용자가 검색창에 입력하는 초성, 중간 단어 포함 검색이 가능하도록 설정.
{
"suggest": {
"text": "아이폰",
"completion": {
"field": "suggest",
"contexts": {
"category": ["아이폰 14"]
}
}
}
}
📌 주요 특징
- "아이폰"을 입력하면 "아이폰 14", "아이폰 14 Pro" 등을 자동 추천.
- 카테고리(Contexts)를 활용하여 특정 범주 내에서 추천 가능.
🔹 3. 인기 검색어 분석 기능 (Aggregation 활용)
{
"aggregations": {
"popular_searches": {
"terms": {
"field": "searchText.keyword",
"size": 10
}
}
}
}
📌 주요 특징
- terms aggregation을 사용하여 상위 검색어 10개 조회.
- "searchText.keyword" 필드를 사용하여 정확한 단어 기준으로 검색.
🔹 4. 검색 성능 최적화를 위한 분석기(Analyzer) 적용
| 분석기 | 설명 |
| standard | 기본 영어/한글 토큰화 지원 |
| simple | 소문자로 변환 후 토큰화 |
| ngram | 입력된 단어를 작은 조각으로 나누어 검색 정확도 향상 |
| edge_ngram | 단어의 앞부분을 기반으로 검색 가능하게 설정 (자동완성 추천 최적화) |
🔹 예제: edge_ngram 적용 시 검색 동작
{
"settings": {
"analysis": {
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": ["letter", "digit"]
}
}
}
}
}
- "아이폰"을 입력하면 "아이폰 14", "아이폰 14 프로", "아이폰 13" 등 연관 검색어 추천 가능.
5️⃣ 프로젝트 성과 및 결론
✅ 성공적인 성능 향상
- 기존의 RDBMS 기반 검색 대비 평균 3배 이상 빠른 검색 성능을 확보.
- 완전한 자동완성 기능을 제공하며, 검색 정확도를 향상.
✅ Elasticsearch 기능 최적 활용
- 샤드(Shard)와 복제본(Replica)를 최적화하여 장애 대응력 향상.
- 역인덱싱 구조를 활용하여 실시간 검색 성능을 개선.
✅ 실제 서비스에 적용 가능
- 다양한 전자상거래(eCommerce) 플랫폼 및 콘텐츠 검색 서비스에서 활용 가능.
📌 Elasticsearch vs 관계형 데이터베이스 (RDBMS) 비교 표
Elasticsearch 개념 RDBMS 개념 일상적인 예시
| Elasticsearch 개념 | RDBMS 개념 | 일상적인 예시 |
| 인덱스 (Index) | 데이터베이스 (Database) | 도서관 |
| 샤드 (Shard) | 파티션 (Partition) | 도서관에서 여러 서고(책장)로 책을 나누어 보관 |
| 타입 (Type) (현재 제거됨) | 테이블 (Table) | 한 개의 엑셀 파일에서 여러 개의 시트(예: "상품 목록", "주문 목록") |
| 문서 (Document) | 행 (Row) | 엑셀의 한 줄(예: "사용자 정보 1개") |
| 필드 (Field) | 열 (Column) | 엑셀의 열(예: "이름", "나이", "주소") |
| 매핑 (Mapping) | 스키마 (Schema) | 엑셀에서 열의 데이터 유형을 미리 지정하는 것(예: "날짜", "숫자") |
| Query DSL | SQL | 자연어 검색 vs 데이터베이스 질의문(SQL) |
| 역인덱싱 (Reverse Indexing) | B-Tree 인덱스 | 책의 색인(Index) vs 사전에서 단어를 찾는 방식 |
📌 추가 설명
- **Elasticsearch의 인덱스(Index)**는 **RDBMS의 데이터베이스(Database)**와 유사하며,
여러 개의 문서(Document, RDBMS의 행(Row))를 저장합니다. - **샤드(Shard)는 RDBMS의 파티션(Partition)**과 비슷하게, 데이터를 여러 개로 나누어 저장하고 병렬 처리하여 성능을 향상시킵니다.
- Query DSL은 SQL과 유사한 역할을 하지만, Elasticsearch는 NoSQL 기반이므로 JSON 형태로 쿼리를 작성합니다.
- **역인덱싱(Reverse Indexing)**은 Elasticsearch에서 데이터를 저장할 때 색인(검색 속도를 빠르게 하기 위한 데이터 구조)을 생성하는 방식으로,
일반적인 관계형 데이터베이스의 B-Tree 인덱스 방식과 차이가 있습니다.
✅ 정리
위 표를 통해 Elasticsearch와 관계형 데이터베이스(RDBMS)의 차이점을 쉽게 이해할 수 있습니다.
Elasticsearch는 **빠른 검색을 위해 최적화된 구조(역인덱싱, 샤드, 문서 기반 저장 방식 등)**를 사용하며,
RDBMS는 **정확한 관계형 데이터 관리(테이블, 스키마, SQL 질의문 등)**를 기반으로 운영됩니다. 🚀
| 이번 프로젝트에서는 검색어 자동완성과 인기 검색어 분석 기능을 구현했습니다. Completion Suggester를 활용해 사용자가 검색어를 입력할 때 실시간으로 추천하는 기능을 개발했고, Aggregation(집계) 기능을 적용해 많이 검색된 키워드를 분석하는 시스템을 구축했습니다. 더 나아가 100만건의 데이터를 첨부하여 필터를 적용한 인기 검색어 확인과 적용하지 않은 검색어 확인을 통해 속도의 변화를 관찰하였습니다. 또한, Elasticsearch의 인덱싱 과정에서 직렬화(Serialization) 이슈가 발생하여 이를 해결하는 데 어려움이 있었습니다. 이를 개선하기 위해 JSON 데이터 구조를 정리하고, 직렬화 방식을 최적화하여 정상적으로 데이터를 저장할 수 있도록 했습니다. |
[1 page]

이번 프로젝트에서는 검색어 자동완성과 인기 검색어 분석 기능을 구현했습니다.
Completion Suggester를 활용해 사용자가 검색어를 입력할 때 실시간으로 추천하는 기능을 개발했고,
Aggregation(집계) 기능을 적용해 많이 검색된 키워드를 분석하는 시스템을 구축했습니다.
[2 page]

엘라스틱 서치에서도 성능 향상을 위하여, 힌트(맵), 카테고리화를 적용, 성능의 변화를 직접 확인해 볼 수 있었습니다.
위는 100만개의 데이터를 추가, 각 검색 방식의 수행시간을 비교한 표입니다.
차례대로 집계만을 사용한 방식, 맵으로 구현한 힌트를 적용한 방식, 카테고리를 적용한 방식순으로 속도가 점차 빨라졌습니다.
[3 page]
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"searchIc": {
"type": "keyword"
},
"searchText": {
"type": "text",
"analyzer": "standard",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"count": {
"type": "integer"
},
"timestamp": {
"type": "date",
"format": "uuuu-MM-dd'T'HH:mm:ss||uuuu-MM-dd'T'HH:mm:ss.SSS"
},
"suggest": {
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50,
"contexts": [
{
"name": "category",
"type": "category"
}
]
}
}
}
}[3 page]
또한, Elasticsearch의 인덱싱 과정에서 매핑 이슈가 발생하여 이를 해결하는 데 어려움이 있었습니다.
이를 개선하기 위해 JSON 데이터 구조를 정리하고, 직렬화 방식을 최적화하여 정상적으로 데이터를 저장할 수 있도록 했습니다.
'Project' 카테고리의 다른 글
| 숙련 CRUD 기반의 테스트, 개선 과제 (0) | 2025.01.06 |
|---|