📌 클라이언트와 서버 간의 상태를 유지하기 위해 서버가 클라이언트별로 생성하고 관리하는 데이터입니다.
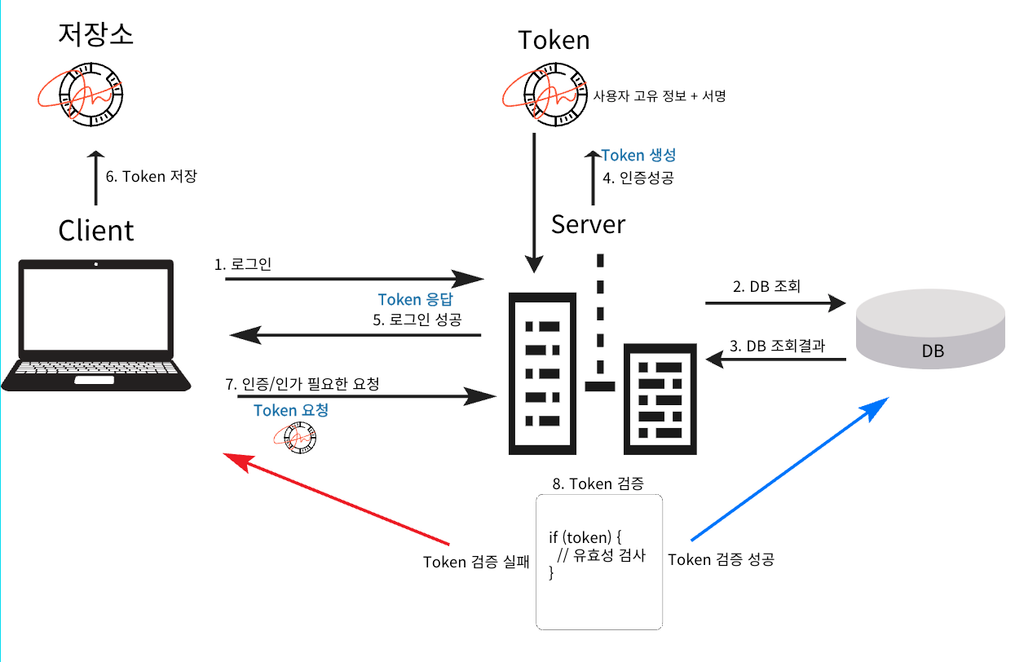
결국 보안 문제를 해결하려면 중요한 정보는 모두 서버에서 저장해야한다. Client와 서버는 예측이 불가능한 임의의 값으로 연결해야 한다.
서버에서 중요한 정보를 보관하며 로그인 연결을 유지하는 방법을Session이라고 한다. 앞서 배운 Cookie는 중요한 정보를 Client측에서 보관하고 있는것이다.
Session 생성 순서
로그인에 성공하면 Server에서 임의로 만든 Session ID를 생성한다.
Session ID는 예측이 불가능해야 한다.
UUID와 같은 값을 활용한다.
생성된 Session ID와 조회한 User 인스턴스를 서버의 Session 저장소에 저장한다.
서버에 유저와 관련된 중요한 정보를 저장한다.
Session 동작 순서
로그인
상태유지를 위해 Cookie를 사용한다.
서버는 클라이언트에 Set-Cookie: SessionId=임의생성값 을 전달한다.
클라이언트는 Cookie 저장소에 전달받은 SessionId 값을 저장한다.
Sessions을 사용하면유저와 관련된 정보는 클라이언트에 없다.
로그인 이후 요청
클라이언트는 모든 요청에 Cookie 의 SessionId를 전달한다.
서버에서는 Cookie를 통해 전달된 SessionId로 Session 저장소를 조회한다.
로그인 시 저장하였던 Session 정보를 서버에서 사용한다.
Session 특징
Session을 사용하여 서버에서 민감한 정보들을 저장한다.
예측이 불가능한 세션 ID를 사용하여 쿠키값을 변조해도 문제가 없다.
세션 ID에 중요한 정보는 들어있지 않다.
시간이 지나면 세션이 만료되도록 설정한다.
해킹이 의심되는 경우 해당 세션을 제거하면 된다.
Session은 특별한것이 아니라 단지 Cookie를 사용하여 클라이언트가 아닌 서버에서 데이터를 저장해두는 방법이다.
Servlet은 Session 을 자체적으로 지원한다.
Servlet의 HttpSession
Servlet이 공식적으로 지원하는 Session인 HttpSession은 Session 구현에 필요한 다양한 기능들을 지원한다.
상수를 클래스로 관리하는 방법
// 추상클래스 -> O
public abstract class Const {
public static final String LOGIN_USER = "loginUser";
}
// 인터페이스 -> O
public interface Const {
String LOGIN_USER = "loginUser";
}
// 클래스 -> X
public class Const { // new Const();
public static final String LOGIN_USER = "loginUser";
}
// Const.LOGIN_USER; O
// new Const(); X
상수로 활용할 class는 인스턴스를 생성(new)하지 않는다.
abstract 추상클래스 혹은 interface 로 만들어 상수값만 사용하도록 만들어두면 된다.
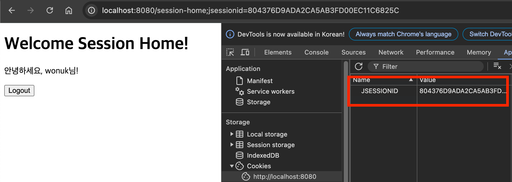
Servlet을 통해 HttpSession 을 생성하게되면 SessionId 가 JSESSIONID로 생성되고 JSESSIONID의 Value는 예측 불가능한 랜덤값으로 생성된다.
= Servlet 환경에서 HttpSession을 생성할 때 서버가 JSESSIONID라는 이름의 쿠키를 발급하고, 그 값이 랜덤하게 생성된 고유 식별자라는 뜻입니다. 이를 통해 세션을 식별하고 사용자와 서버 간의 상태를 유지합니다.
Session에 Data를 저장하는 방법으로 request.setAttribute(); 와 비슷하다.
하나의 Session에 여러개의 데이터를 메모리에 저장할 수 있다.
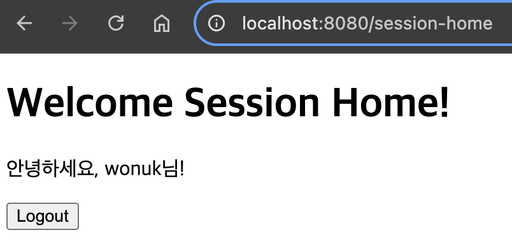
SessionHomeController
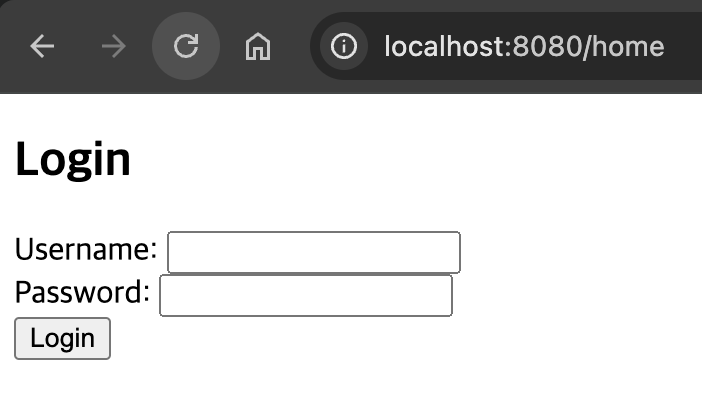
요구사항1. 로그인한 회원이면 home 페이지로 이동한다. 요구사항2. home 페이지를 보려면 로그인이 필수이다. 요구사항3. 로그인하지 않은 회원이면 login 페이지로 이동한다.
@Controller
@RequiredArgsConstructor
public class SessionHomeController {
private final UserService userService;
@GetMapping("/session-home")
public String home(
HttpServletRequest request,
Model model
) {
// default인 true로 설정되면 로그인하지 않은 사람들도 값은 비어있지만 세션이 만들어진다.
// session을 생성할 의도가 없다.
HttpSession session = request.getSession(false);
// session이 없으면 로그인 페이지로 이동
if(session == null) {
return "session-login";
}
// session에 저장된 유저정보 조회
// 반환타입이 Object여서 Type Casting이 필요하다.
UserResponseDto loginUser = (UserResponseDto) session.getAttribute(Const.LOGIN_USER);
// Session에 유저 정보가 없으면 login 페이지 이동
if (loginUser == null) {
return "session-login";
}
// Session이 정상적으로 조회되면 로그인된것으로 간주
model.addAttribute("loginUser", loginUser);
// home 화면으로 이동
return "session-home";
}
}
@Getter
public class User {
// 식별자
private Long id;
// 이름
private String name;
// 나이
private Integer age;
// 로그인 ID
private String userName;
// 비밀번호
private String password;
public User(Long id, String name, Integer age, String userName, String password) {
this.id = id;
this.name = name;
this.age = age;
this.userName = userName;
this.password = password;
}
}
User 클래스 설계
로그인 요청 DTO
// 필드 전체를 매개변수로 가진 생성자가 있어야 @ModelAttribute가 동작한다.
@Getter
@AllArgsConstructor
public class LoginRequestDto {
// 사용자가 입력한 아이디
@NotBlank
private final String userName;
// 사용자가 입력한 비밀번호
@NotNull
private final String password;
}
일반적으로 DTO는 클라이언트의 요청혹은 서버의 응답이기 때문에 변경되면 안된다.
final을 사용하여 불변 객체로 관리한다.
Java17 버전에 나온 record를 사용할 수 있다.
로그인 응답 DTO
@Getter
public class LoginResponseDto {
private final Long id;
// 이외 응답에 필요한 데이터들을 필드로 구성하면 된다.
// 필요한 생성자
public LoginResponseDto(Long id) {
this.id = id;
}
}
유저 조회 응답 DTO
@Getter
public class UserResponseDto {
// 유저 식별자
private final Long id;
// 유저 이름
private final String name;
public UserResponseDto(Long id, String name) {
this.id = id;
this.name = name;
}
}
HomeController
@Controller
@RequiredArgsConstructor
public class HomeController {
private final UserService userService;
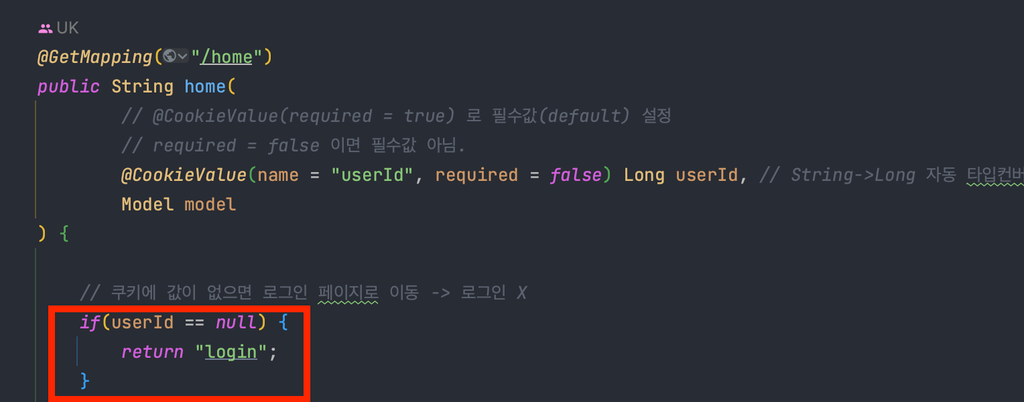
@GetMapping("/home")
public String home(
// @CookieValue(required = true) 로 필수값(default) 설정
// required = false 이면 필수값 아님.
@CookieValue(name = "userId", required = false) Long userId, // String->Long 자동 타입컨버팅
Model model
) {
// 쿠키에 값이 없으면 로그인 페이지로 이동 -> 로그인 X
if(userId == null) {
return "login";
}
// 실제 DB에 데이터 조회 후 결과가 없으면 로그인 페이지로 이동 -> 일치하는 회원정보 X
UserResponseDto loginUser = userService.findById(userId);
if(loginUser == null) {
return "login";
}
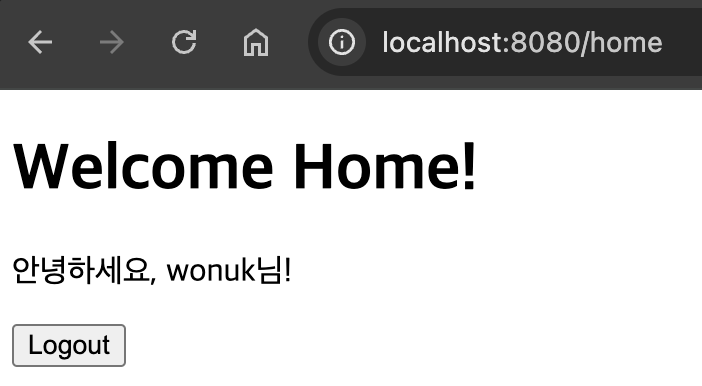
// 정상적으로 로그인 된 사람이라면 View에서 사용할 데이터를 model 객체에 데이터 임시 저장
model.addAttribute("loginUser", loginUser);
// home 화면으로 이동
return "home";
}
}
View에서는 model 객체에 담겨있는 loginUser 를 활용하여 변수로 사용할 수 있다.
UserController
@Controller
@RequiredArgsConstructor
public class UserController {
private final UserService userService;
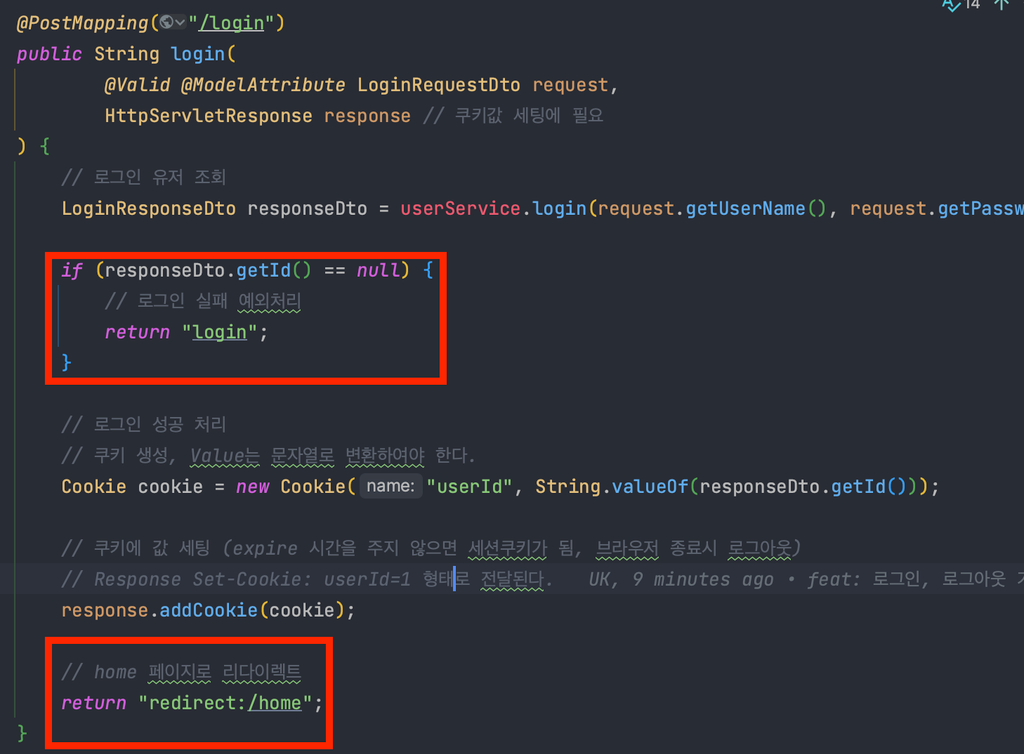
@PostMapping("/login")
public String login(
@Valid @ModelAttribute LoginRequestDto request,
HttpServletResponse response // 쿠키값 세팅에 필요
) {
// 로그인 유저 조회
LoginResponseDto responseDto = userService.login(request.getUserName(), request.getPassword());
if (responseDto.getId() == null) {
// 로그인 실패 예외처리
return "login";
}
// 로그인 성공 처리
// 쿠키 생성, Value는 문자열로 변환하여야 한다.
Cookie cookie = new Cookie("userId", String.valueOf(responseDto.getId()));
// 쿠키에 값 세팅 (expire 시간을 주지 않으면 세션쿠키가 됨, 브라우저 종료시 로그아웃)
// Response Set-Cookie: userId=1 형태로 전달된다.
response.addCookie(cookie);
// home 페이지로 리다이렉트
return "redirect:/home";
}
@PostMapping("/logout")
public String logout(
HttpServletResponse response
) {
Cookie cookie = new Cookie("userId", null);
// 0초로 쿠키를 세팅하여 사라지게 만듬
cookie.setMaxAge(0);
response.addCookie(cookie);
// home 페이지로 리다이렉트
return "redirect:/home";
}
}
Cookie 이름(Key)은 userId , 값(Value)은 회원 index 값을 담아둔다.
Set-Cookie: userId=1
만료 시간을 지정하지 않으면 세션 쿠키로 만들어진다.
브라우저 종료 전까지 userId 가 모든 요청 헤더의 Cookie에 담겨서 전달된다.
로그아웃 기능
새로운 Cookie를 userId = null로 생성한다.
setMaxAge(0) 설정으로 만료시킨다.
응답에 만료된 쿠키를 담아 보낸다.
UserService
@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
public LoginResponseDto login(String userName, String password) {
// 입력받은 userName, password와 일치하는 Database 조회
Long index = userRepository.findIdByUserNameAndPassword(userName, password);
return new LoginResponseDto(index);
}
public UserResponseDto findById(Long id) {
return userRepository.findById(id);
}
}
UserRepository
@Repository
public class UserRepository {
private static final User USER1 = new User(1L, "wonuk", 100, "wonuk", "1234");
private static final User USER2 = new User(2L, "wonuk2", 200, "wonuk2", "2345");
private static final List<User> USERS = Arrays.asList(USER1, USER2);
public Long findIdByUserNameAndPassword(String userName, String password) {
return USERS.stream()
.filter(user -> user.getUserName().equals(userName) && user.getPassword().equals(password))
.map(User::getId)
.findFirst()
.orElse(null);
}
public UserResponseDto findById(Long id) {
return USERS.stream()
.filter(user -> Objects.equals(user.getId(), id))
.map(user -> new UserResponseDto(user.getId(), user.getName()))
.findFirst()
.orElse(null);
}
}
나를 위한 커밋이 아니라 팀원을 위한 커밋을 하기 위해 메시지 내용을 어떻게 쓸 지 고민해
프로젝트를 진행하면서 활용하면 좋을 것 같은 다양한 로직과 기술을 사용하고 공유함 (코드 컨벤션, 소스패키지 구조 시각화 등)
정규표현식과 regxp를 사용해 입력패턴을 적용해 봄
팀의 분위기를 긍정적으로 이끌어가기 위해 노력함
깃 컨벤션을 미리 정해놓은 부분이 좋았음
코드의 안정성을 위해 공통 기능을 우선적으로 준비하고 프로젝트를 시작했던 점이 추후 도움이 되었음
비즈니스 로직 간소화
검증 로직은 별도 메서드로 이원화
팀원들과 화목한 관계 추구 노력
PROBLEM
📌 불편하게 느꼈고 수정하고 싶은 부분 = 문제였던 부분
선행학습이 부족해 다른 팀원이 사용하는 기술을 이해하지 못함
계획을 세우지 않아 시간을 효율적으로 관리하지 못하고, 개인 학습 시간을 전혀 가지지 못함
깃허브 커멋 컨벤션이 엄격하게 지켜지지 않음
테이블 설계시, 처음에 고려치 못한 부분에 대해 우선순위에서 밀렸다는 이유로 반영 못함
다른 브랜치에 푸쉬하는 실수를 저질렀음
실제 애플리케이션 배포까지 경험해보자라는 목표로 프로젝트에 임했지만 AWS에 대한 이해 부족으로 배포 단계까지 가지 못함
예외 처리를 다소 복잡함. 어느 수준까지 분기할 건지 고민 필요
API Url 설계할 때 조금 더 RESTful하게 만들 필요가 있음. url path만 보고 어떤 역할을 하는지 이해하기 쉽지 않은 API 다수
소규모 프로젝트라, 패키지 구조를 [controller, service, repository, domain, dto ...] 이런 식으로 만들었는데, 생각보다 DTO 클래스가 많아 조금만 더 프로젝트 규모가 커지면 유지보수 불가. domain 단위 패키지 구조로 마이그레이션 고려
TRY
📌 문제 해결을 위해 실행 가능한 것들 = 앞으로의 목표
혼자 해보기엔 어려웠던 기능을 팀원들과 협업하면서 시도해보기
계획표를 꼭 세우고, 개인 학습 시간 챙기기
다음에는 컨벤션을 더 확실히 정하고 프로젝트를 시작하기
타 팀의 잘한 점을 최대한 흡수하기, 새로운 인사이트를 얻기
우선은 필요 기능을 모두 구현하고, 디테일을 살리기
데이터베이스 설계나 sql에 대해 공부를 더 해야겠다는 생각이 들었음
기능을 왜 쓰는지, 어떻게 쓰는건지 정확히 파악하는 것이 가장 중요하다는 것을 알게됨
다음 프로젝트에서는 간트 차트를 작성해 보고자 함
테스트 코드를 작성
더미데이터를 정합성 있게 제조
테스트 코드가 github에서 자동으로 빌드되고, 애플리케이션이 자동으로 서버에 배포되는 단계까지 적용
@Data
public class TestDto {
// 테스트 하고싶은 Annotation으로 변경 가능
@NotBlank
private String stringField;
@NotNull
@Range(min = 1, max = 9999)
private Integer integerField;
}
import static org.assertj.core.api.Assertions.assertThat;
public class BeanValidationTest {
@Test
void beanValidation() {
// Spring과 통합하면 아래 두줄의 코드는 사용하지 않는다.
ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
Validator validator = factory.getValidator();
// Test 하고싶은 상황을 만들어서 검증 가능
TestDto dto = new TestDto();
dto.setStringField(" ");
dto.setIntegerField(1);
// DTO를 검증
Set<ConstraintViolation<TestDto>> violations = validator.validate(dto);
// 검증 결과가 예상대로 발생했는지 확인
// 검증에 걸린 필드가 있어야 함
assertThat(violations).isNotEmpty();
// 2개의 제약 위반 발생
assertThat(violations.size()).isEqualTo(2);
// Validation에 걸린 내역을 출력
for(ConstraintViolation<TestDto> violation : violations) {
// 아래의 결과에 Message가 있으면 Validation에 걸린것.
// Default Message가 있기 때문에 출력됨
// Message를 수정하고싶다면 Annotation 속성값(message="입력")으로 설정할 수 있다.
// 결과가 비어있으면 Validation에 걸리지 않은것.
System.out.println("violation = " + violation.getMessage());
}
}
}
import가 org.hibernate.validator로 시작하면 하이버네이트를 사용할 때만 제공되는 검증 기능으로 다른 구현체로 validator를 교체하였을 경우 동작하지 않는다. 하지만 org.hibernate.validator를 대부분 사용한다.
Validator
📌 유효성 검증(Validation) 인터페이스입니다. 특정 객체에 대한 데이터 유효성을 검사하고, 유효하지 않은 경우 오류 메시지를 생성하여 처리할 수 있도록 설계되었습니다. 이 인터페이스는 커스텀 유효성 검증 로직을 구현하거나, 스프링의 유효성 검증 프레임워크와 통합할 때 사용됩니다.
단순히 Annotation을 선언해주면 검증이 완료되는 이유는Validator(Validation을 사용하는것)가 존재하기 때문이다.
@Valid 는 JAVA 표준이고 @Validated 는 Spring 에서 제공하는 Annotation이다.
@Validated 를 통해 Group Validation 혹은 Controller 이외 계층에서 Validation이 가능하다.
@Valid 는 MethodArgumentNotValidException 예외를 발생시킨다.
@Validated 는 ConstraintViolationException 예외를 발생시킨다.
Validator 적용
Validator 적용 전
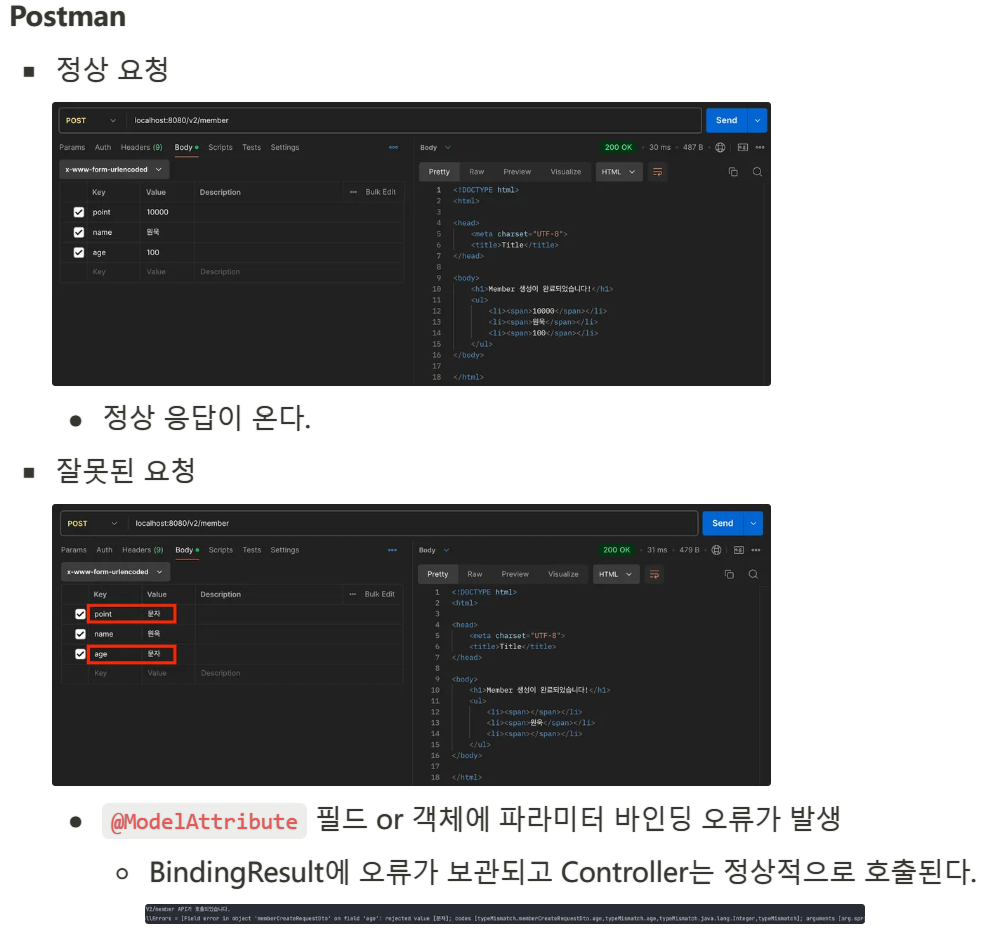
@ModelAttribute 각각의 필드 타입에 맞추어 바인딩(변환) 시도
성공 : Controller 정상 호출
실패 : TypeMismatch FieldError 발생
Validator 적용 후
@ModelAttribute → 각 필드 바인딩 → 성공한 필드만 Bean Validation 적용
Integer 타입 필드에 문자가 오면 애초에 검증의 의미가 없다.
성공 : String 필드에 문자입력 → 바인딩 성공 → String 필드에 Bean Validation 적용
실패 : Integer 필드에 문자입력 → 바인딩 실패 → bindingResult에 TypeMismatch FieldError 추가 → 바인딩에 실패한 필드는 값이 없음(null) → Bean Validation 적용하지 않음
Bean Validator는 바인딩에 실패한 필드는 Bean Validation을 적용하지 않는다. 바인딩(변환)에 성공한 필드만이 Bean Validation을 적용하는 의미가 있다.
에러 메세지
📌 Spring의 Bean Validation은 Default로 제공하는 Message들이 존재하고 임의로 수정할 수 있다
Error Message
Bean Validation을 적용하고 BindingResult에 등록된 검증 오류를 확인해보면 오류가 Annotation 이름으로 등록되어 있다.
@Data
public class TestDto {
@NotBlank
private String stringField;
@NotNull
@Range(min = 1, max = 9999)
private Integer integerField;
}
@Slf4j
@RestController
public class BeanValidationController {
@PostMapping("/error-message")
public String beanValidation(
@Validated @ModelAttribute TestDto dto,
BindingResult bindingResult
) {
// bindingResult Field Error 출력
if (bindingResult.hasErrors()) {
return String.valueOf(bindingResult.getFieldError());
}
// 성공시 문자열 반환
return "회원가입 성공";
}
}
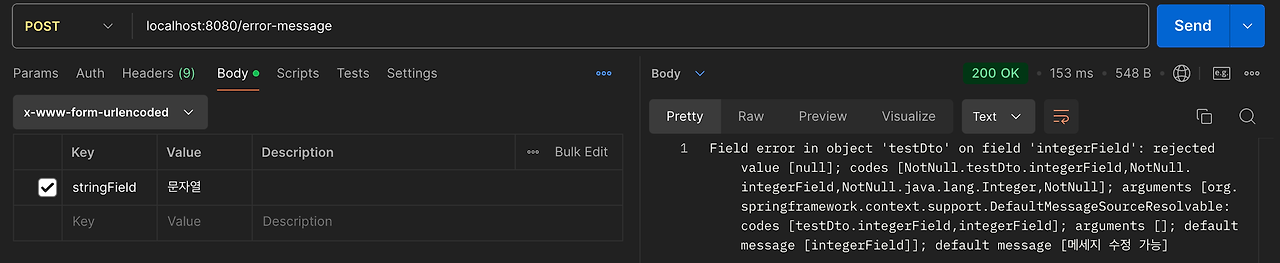
Postman
integerField 는 비워두고 stringField 만 값(”문자열”) 입력
출력결과
Field error in object 'testDto' on field 'integerField': rejected value [null]; codes [NotNull.testDto.integerField,NotNull.integerField,NotNull.java.lang.Integer,NotNull]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [testDto.integerField,integerField]; arguments []; default message [integerField]]; default message [널이어서는 안됩니다]
NotNull 오류 코드를 기반으로 MessageCodesResolver 를 통해 메세지 코드 생성
Spring 에서는 오류 메시지 코드관리를 위해 MessageCodesResolver 인터페이스의 구현체인 DefaultMessageCodesResolver를 기본으로 사용한다.
에러 메세지 수정하기
NotNull.Object.fieldName
Annotation의 message 속성 사용
@Data
public class TestDto {
@NotBlank(message = "메세지 수정 가능")
private String stringField;
}
NotNull.fieldName(MessageSource)
필드명에 맞춘 사용자 정의 Message
NotNull.FieldType(MessageSource)
필드 타입에 맞춘 사용자 정의 Message
NotNull
Annotation 자체에 포함된 Default Message
네가지 방법중 Annotation의 message 속성을 사용하여 에러 메세지를 수정하면 됩니다.
MessageSource란 Spring에서 지원하는 인터페이스로 메세지의 국제화를 위해 사용된다.
Object Error
필드 단위가 아닌 객체 전체에 대한 오류를 나타낸다. 예를들어 두 필드 간의 관계를 검증할 때 ObjectError를 통해 해당 오류를 BindingResult에 기록할 수 있다.
지금까지 위에서 배운 내용은 객체가 아닌 필드 단위를 검증해서 발생하는 Field Error에 대한 내용
@ScriptAssert
코드예시
비밀번호와 비밀번호 확인 필드가 동일한지 검증
@Data
@ScriptAssert(lang = "javascript", script = "_this.password === _this.confirmPassword", message = "Passwords do not match")
public class UserRegistrationDto {
@NotBlank(message = "Password is required")
private String password;
@NotBlank(message = "Confirm password is required")
private String confirmPassword;
}
실제로 @ScriptAssert는 제약사항 때문에 사용하지 않는다.
실무에서는 훨씬 복잡한 Validation들이 필요하지만 대응이 불가능하다.
ex) 다른 객체끼리의 비교 혹은 DB조회 결과와 비교
Object Error의 경우 Java 코드로 직접 Validation 한다.
Java 코드로 구현하기
요구사항 : 총 구매 가격이 10000원 이상이여야 한다.
price * count ≥ 10000
@Getter
@AllArgsConstructor
public class OrderRequestDto {
@NotNull
@Range(min = 1000)
private Integer price;
@NotNull
@Range(min = 1)
private Integer count;
}
@Slf4j
@RestController
public class BeanValidationController {
@PostMapping("/object-error")
public String objectError(
@Validated @ModelAttribute OrderRequestDto requestDto,
BindingResult bindingResult
) {
// 합이 10000원 이상인지 확인
int result = requestDto.getPrice() * requestDto.getCount();
if (result < 10000) {
// Object Error
bindingResult.reject("totalMin", new Object[]{10000, result}, "총 합이 10000 이상이어야 합니다.");
}
// Error가 있으면 출력
if (bindingResult.hasErrors()) {
log.info("errors={}", bindingResult);
return bindingResult.getAllErrors().get(0).getDefaultMessage();
}
// 성공로직 ...
return "성공";
}
}
Object Error는 로직으로 구현하면 된다.
Postman
Bean Validation의 충돌
📌 등록, 수정 API에서 각각 다른 Validation이 적용된다면?
요구사항
상품
id (식별자)
name (이름)
price (가격)
count (재고)
상품 등록 API
식별자 값은 필수가 아니다.
name은 null, “”, “ “을 허용하지 않는다.
price는 10 ~ 10000 사이의 숫자로 생성한다.
count는 1 ~ 999 사이의 숫자로 생성한다.
상품 수정 API
식별자 값이 필수이다.
name은 null, “”, “ “을 허용하지 않는다.
price는 무제한으로 허용한다.
count는 1 ~ 999 사이의 숫자로 생성한다.
일반적으로 수정 API를 만들 때 식별자 id값을 항상 Controller에서 받도록 구성한다. HTTP 요청은 사용자가 임의로 변경하여 요청할 수 있음으로 항상 서버에서 최종적으로 추가 검증을 진행 해야한다. ex) 게시글 수정시 요청자 본인이 쓴 글인지 확인한다.
Product 저장 API
@Data
public class ProductRequestDto {
// 식별자는 Database에서 자동생성
@NotBlank
private String name;
@NotNull
@Range(min = 10, max = 10000)
private Integer price;
@NotNull
@Range(min = 1, max = 999)
private Integer count;
}
@Slf4j
@RestController
public class ConflictValidationController {
@PostMapping("/product")
public String save(
@Validated @ModelAttribute ProductRequestDto requestDto
) {
log.info("생성 API가 호출 되었습니다.");
// Validation 성공시 repository 저장로직 호출
return "상품 생성이 완료되었습니다";
}
}
Product 수정 API
@Data
public class ProductRequestDto {
@NotBlank
private String name;
// price 무제한 요구사항 반영
@NotNull
private Integer price;
@NotNull
@Range(min = 1, max = 999)
private Integer count;
}
@Slf4j
@RestController
public class ConflictValidationController {
@PutMapping("/product/{id}")
public String update(
@PathVariable Long id,
@Validated @ModelAttribute ProductRequestDto test
) {
log.info("수정 API가 호출 되었습니다.");
// Validation 성공시 repository 수정로직 호출
return "상품 수정이 완료되었습니다.";
}
}
@PathVariable의 required 속성의 기본값은 true이다.
해결방법
저장할 Object를 직접 사용하지 않고 SaveRequestDto, UpdateRequestDto 따로 사용한다.
Bean Validation의 groups 기능을 사용한다.
groups
Bean Validation의 groups 속성은 다양한 유효성 검사 시나리오를 정의할 때 사용된다. 동일한 객체에 대한 검증을 상황에 따라 다르게 적용하고 싶을 때 groups를 활용할 수 있다.
// 저장용 group
public interface SaveCheck {
}
// 수정용 group
public interface UpdateCheck {
}
@Data
public class ProductRequestDtoV2 {
// 저장, 수정 @NotBlank Validation 적용
@NotBlank(groups = {SaveCheck.class, UpdateCheck.class})
private String name;
// 사용하는 모든곳에서 @NotNull Validation 적용
@NotNull
// 저장만 @Range 반영
@Range(min = 10, max = 10000, groups = SaveCheck.class)
private Integer price;
@NotNull
@Range(min = 1, max = 999)
private Integer count;
}
@Slf4j
@RestController
public class ProductController {
@PostMapping("/v2/product")
public String save(
// 저장 속성값 설정
@Validated(SaveCheck.class) @ModelAttribute ProductRequestDtoV2 requestDtoV2
) {
log.info("생성 API가 호출 되었습니다.");
// Validation 성공시 repository 저장로직 호출
return "상품 생성이 완료되었습니다";
}
@PutMapping("/v2/product/{id}")
public String update(
@PathVariable Long id,
// 수정 속성값 설정
@Validated(UpdateCheck.class) @ModelAttribute ProductRequestDto test
) {
log.info("수정 API가 호출 되었습니다.");
// Validation 성공시 repository 수정로직 호출
return "상품 수정이 완료되었습니다.";
}
}
groups VS DTO 분리
📌 Bean Validation의 충돌이 발생하는 경우 대부분 DTO를 분리하는 방법이 적절하다.
groups VS DTO 분리
groups 속성을 사용하면 등록과 수정시 각각 다르게 Validation이 적용된다.
가독성이 떨어지고 코드 복잡도가 올라간다.
실무에서는 등록 폼과 수정 폼 자체를 분리해서 사용하기 때문에 DTO 분리 방법을 사용하면 된다.
단, 네이밍은 일관성있게 작성해야 한다.(SaveRequestDto, UpdateRequestDto)
DTO 분리
실제로 간단한 프로젝트를 개발해보면 저장, 수정시 Request가 비슷한 경우가 있다.
각각의 장단점이 존재하지만 어설프게 하나로 합칠 경우 유지보수시 엄청난 경험을 할 수 있다.
RequestDto가 변한다는건 해당 API의 스펙 자체가 변경되어 많은 수정이 발생한다.
실무에서는 거의 발생하지 않는 경우기 때문에 간단한게 아니라면 대부분 분리하도록 하자!
@Validated VS @Valid
@Validated
속성값이 존재한다.
spring이 제공하는 Annotation
@Valid
속성값이 존재하지 않는다, groups 기능 지원하지 않는다.
groups 기능을 사용하려면 @Validated를 사용해야 한다.
Java 표준 Annotation
@ModelAttribute, @RequestBody
📌 @Valid, @Validated는 @ModelAttribute뿐만 아니라 @RequestBody에도 적용할 수 있다. @ModelAttribute는 요청 파라미터 혹은 Form Data(x-www-urlencoded)를 다룰 때 사용하고 @RequestBody 는 HTTP Body Data를 Object로 변환할 때 사용한다.
@RequestBody 적용
@Data
public class ExampleRequestDto {
@NotBlank
private String field1;
@NotNull
@Range(min = 1, max = 150)
private Integer field2;
}
@Slf4j
@RestController
public class RequestBodyController {
@PostMapping("/example")
public Object save(
@Validated @RequestBody ExampleRequestDto dto,
BindingResult bindingResult
) {
log.info("RequestBody Controller 호출");
if(bindingResult.hasErrors()) {
log.info("validation errors={}", bindingResult);
// Field, Object Error 모두 JSON으로 반환
return bindingResult.getAllErrors();
}
// 성공 시 RequestDto 반환(의미 없음)
return dto;
}
}
Rest API 요청의 세가지 경우의 수
성공 요청: 성공
Controller 정상 호출
응답 반환
실패 요청: JSON을 객체로 변환하는 것 자체가 실패
field2에 String 입력
JSON → Object 변환 실패
중요! Controller가 호출되지 않는다.
반드시 JSON → Object로 변환이 되어야 Validation이 진행된다.
검증 오류 요청: JSON을 객체로 변환하는 것은 성공, 검증에서 실패
field2의 값에 범위를 넘어서는 값 입력 @Range(max = 150)
bindingResult.getAllErrors() 가 MessageConverter에 의해 JSON으로 변환되어 반환된다.
Controller를 실제로 호출한다.
log로 작성한 bindingResult error들이 콘솔에 출력된다.
정리
@ModelAttribute와 @RequestBody 차이점
@ModelAttribute
각각의 필드 단위로 바인딩한다.
특정 필드 바인딩이 실패하여도 나머지 필드는 정상적으로 검증 처리할 수 있다.
특정필드 변환 실패
컨트롤러 호출, 나머지 필드 Validation 적용
@RequestBody
필드별로 적용되는것이 아니라 객체 단위로 적용된다.
MessageConverter가 정상적으로 동작하여 Object로 변환하여야 Validation이 동작한다.
특정필드 변환 실패
컨트롤러 미호출, Validation 미적용
추가내용
bindingResult.getAllErrors()는 FieldError와 ObjectError 모두 반환한다.
Spring은 MessageConverter를 이용해 Error 객체들을 변환하여 응답한다.
RequestDTO 의 경우, 생성, 수정, 삭제, 모두 비슷하게 생겼어도 따로 분리해서 사용하자.
작성한 코드는 예시일 뿐 실제로는 API Spec에 맞는 응답을 만들어 클라이언트에 전달 해야한다.
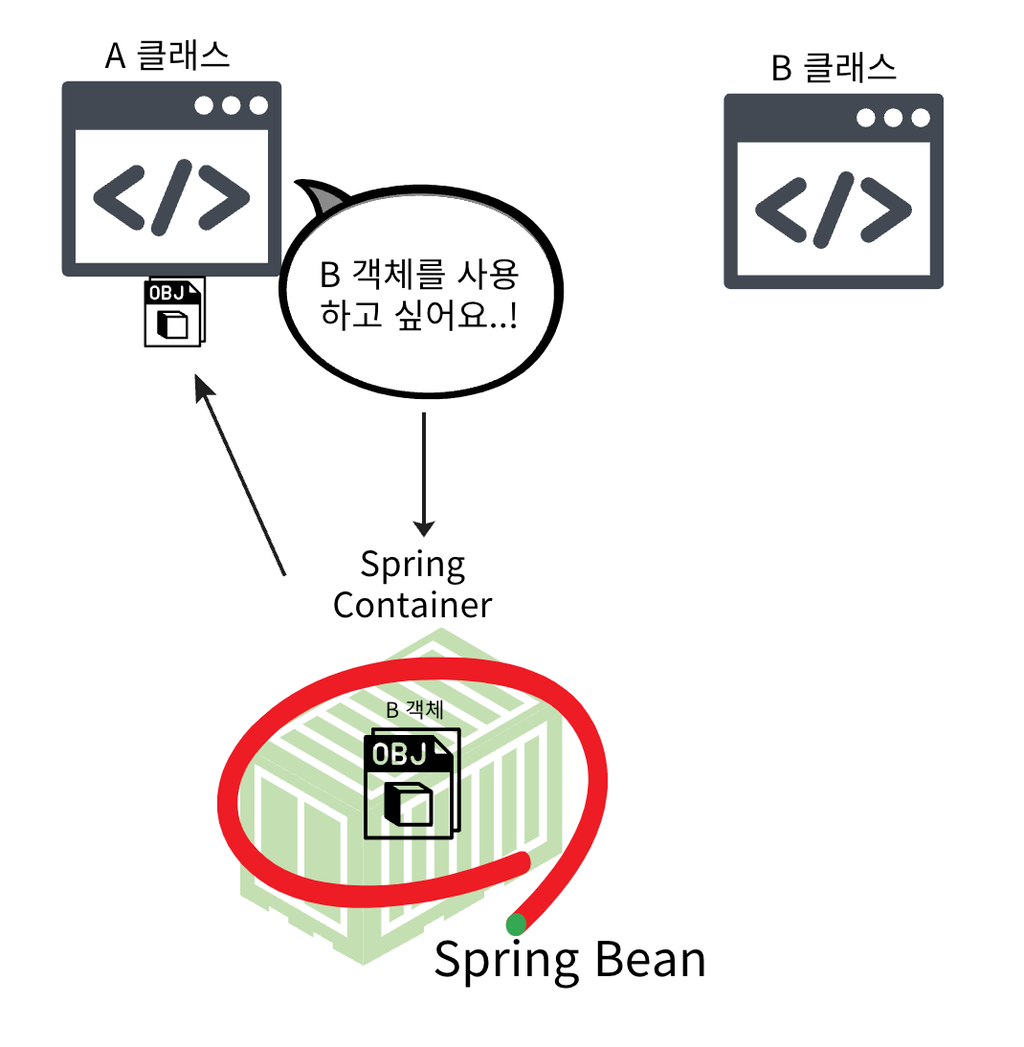
📌 객체 간의 의존성을 스프링 컨테이너가 자동으로 관리하고 주입해주는 설계 패턴입니다. 객체가 다른 객체를 필요로 할 때, 직접 생성하지 않고 외부에서 주입받아 사용하도록 설계하는 방식입니다.
@Autowired 는 의존성을 자동으로 주입할 때 사용하는 Annotation 이다.
기본적으로 주입할 대상이 없으면 오류가 발생한다.(required = true)
의존관계 주입의 기본 개념
의존성(Dependency):
A 객체가 B 객체를 사용해야 한다면, A는 B에 의존하고 있다고 말합니다.
이때 B 객체를 A 내부에서 직접 생성하지 않고,외부에서 주입받는 것을 의존관계 주입이라고 합니다.
스프링 DI:
스프링 컨테이너가 객체(빈)를 생성하고 관리하면서 필요한 의존성을 자동으로 주입합니다.
개발자는 직접 의존성을 생성하거나 연결할 필요가 없으며, 컨테이너가 이를 처리합니다.
왜 의존성 주입인가?
@Autowired와 스프링 컨테이너가 있기 때문에, 개발자가 의존 객체를 직접 생성하지 않아도 되고, 컨테이너가 이를 대신 처리합니다. 이 점이 의존성 주입의 핵심입니다.
장점
결합도 감소:
MyApp은 MyService의 구체적인 구현체를 몰라도 됩니다. (DIP 원칙 준수)
다른 구현체로 변경할 때 코드 수정이 필요 없습니다.
유연성 증가:
스프링 컨테이너에서 주입받는 객체를 쉽게 교체하거나 확장할 수 있습니다.
테스트 용이성:
테스트 환경에서 Mock 객체를 주입할 수 있습니다.
1. 생성자 주입
생성자를 통해 의존성을 주입하는 방법.
최초에 한번 생성된 후 값이 수정되지 못한다.[불변, 필수]
public interface MyService {
void doSomething();
}
// Spring Bean으로 등록
@Service
public class MyServiceImpl implements MyService {
@Override
public void doSomething() {
System.out.println("MyServiceImpl 메서드 호출");
}
}
// 생성자 주입 방식
@Component
public class MyApp {
// 필드에 final 키워드 필수! 무조건 값이 있도록 만들어준다.(필수)
private final MyService myService;
// 생성자를 통해 의존성 주입, 생략 가능
@Autowired
public MyApp(MyService myService) {
this.myService = myService;
}
public void run() {
myService.doSomething();
}
}
@ComponentScan(basePackages = "com.example.springdependency.test")
public class Main {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(Main.class);
// 등록된 MyApp 빈 가져오기
MyApp myApp = context.getBean(MyApp.class);
// 빈 메서드 호출
myApp.run();
}
}
-------------------------------------
// 생성자가 두개인 경우 생략이 불가능하다.
@Component
public class MyApp {
// 필드에 final 키워드 필수! 무조건 값이 있도록 만들어준다.(필수)
private final MyService myService;
public MyApp(MyService myService, String myRepository) {
this.myService = myService;
}
// 생성자를 통해 의존성 주입
// @Autowired를 생략하기 위해서는 생성자가 하나여야 한다.
public MyApp(MyService myService) {
this.myService = myService;
}
public void run() {
service.doSomething();
}
}
생성자가 하나인 경우 @Autowired 생략이 가능하다.
둘중 어떤 생성자를 사용해야 하는지 Spring은 알지 못한다.
2. Setter 주입
Setter 메서드를 통해 의존성을 주입하는 방법.
@Component
public class MyApp {
private MyService myService;
// Setter 주입
@Autowired
public void setMyService(MyService myService) {
this.myService = myService;
}
public void run() {
myService.doSomething();
}
}
선택하거나, 변경 가능한 의존관계에 사용한다.(생성자 주입은 필수 값)
// MyService가 Spring Bean으로 등록되지 않은 경우에도 주입이 가능하다.
@Autowired(required = false)
public void setMyService(MyService myService) {
this.myService = myService;
}
// 실행 도중 인스턴스를 바꾸고자 하는 경우
// setMyService(); 메서드를 외부에서 호출하면 된다.(이런 경우는 거의 없음)
3. 필드 주입
필드에 직접적으로 주입하는 방법 (가장 추천되지 않음).
@Component
public class MyApp {
@Autowired
private MyService myService; // 필드에 직접 주입
public void run() {
myService.doSomething();
}
}
코드는 간결하지만 Spring이 없으면 사용할 수 없다.
사용하지 않아야 한다.
// Spring을 사용하지 않는 경우 실행이 불가능하다.
public class MainV2 {
public static void main(String[] args) {
MyApp myApp = new MyApp();
myApp.run();
}
}
외부에서 myService 값을 설정하거나 변경할 방법이 없다.
결국 setter를 만들어야 한다.
순수 Java 코드로 사용할 수 없다. = 테스트 코드 작성이 힘들다.
Application의 실행과 관계 없는 @SpringBootTest 테스트 코드나 Spring에서만 사용하는 @Configuration 같은 곳에서 주입할 때 주로 사용한다.
4. 일반 메서드 주입
생성자, setter 주입으로 대체가 가능하기 때문에 사용하지 않는다.
@Component
public class MyApp {
private MyService myService;
// 일반 메서드 주입
@Autowired
public void init(MyService myService) {
this.myService = myService;
}
public void run() {
myService.doSomething();
}
}
의존관계를 자동으로 주입할 객체가 Spring Bean으로 등록되어 있어야 @Autowired 로 주입이 가능하다.
생성자 주입
📌 과거 setter, 필드 주입도 사용했지만 현재는 DI를 가지고 있는 대부분의 Framework가 생성자 주입 방식을 권장한다.
생성자 주입을 선택하는 이유
불변(immutable)
어떤 요리(Web Application)를 만들지 정해졌다면 이미 재료(Bean)와 의존 관계가 결정된다.
객체를 생성할 때 최초 한번만 호출된다.(불변)
setter 주입을 사용하면 접근제어자가 public 으로 설정되어 누구나 수정할 수 있게된다.
실수 방지
순수 Java 코드로 사용할 때(주로 테스트 코드) 생성자의 필드를 필수로 입력하도록 만들어준다.(NPE 방지)
컴파일 시점에 오류를 발생 시킨다. 즉, 실행 전에 오류를 알 수 있다.
public class MyApp {
private MyService myService;
public MyApp() {
this.myService = new MyService(); // 직접 생성
}
public void run() {
myService.doSomething();
}
}
---------------------------------------
@Component // 해당 어노테이션이 MyService 객체를 bean으로 만들어준다. 즉 스프링이 객체 MyService를 저장한다.
public class MyApp {
private final MyService myService;
@Autowired
public MyApp(MyService myService) {
this.myService = myService; // 외부에서 주입 (직접 선언이 아니라 스프링에 저장된 객체 사용)
}
public void run() {
myService.doSomething();
}
}
위 코드 참고
@Autowired: 스프링 컨테이너가 MyService 타입의 빈을 찾아서 자동으로 주입합니다.
MyApp은 MyService를 직접 생성하지 않습니다. 대신, 스프링 컨테이너가 제공한 인스턴스를 사용합니다.
Spring Framework에 의존하지 않아도 객체 지향 특성을 가장 잘 사용하는 방법이다.
필드에 final 은 생성자 주입 방식만 사용할 수 있다. 나머지 주입 방식들은 모두 생성 이후에 호출되어 사용할 수 없다.
@RequiredArgsConstructor
📌 실제 Web Application을 개발하면 대부분이 불변 객체이고 생성자 주입 방식을 선택하게 된다. 이런 반복되는 코드를 편안하게 작성하기 위해 Lombok에서 제공하는 Annotation 이다.
@RequiredArgsConstructor
final 필드를 모아서 생성자를 자동으로 만들어 주는 역할
Annotation Processor 가 동작하며 컴파일 시점에 자동으로 생성자 코드를 만들어준다.
사용 방법
@Component
@RequiredArgsConstructor
public class MyApp {
// 필드에 final 키워드 필수! 무조건 값이 있도록 만들어준다.(필수)
private final MyService myService;
// Annotation Processor가 만들어 주는 코드
// public MyApp(MyService myService) {
// this.myService = myService;
// }
public void run() {
myService.doSomething();
}
}
📌 Spring이 특정 패키지 내에서 @Component, @Service, @Repository, @Controller같은 Annotation이 붙은 클래스를 자동으로 검색하고, 이를 Bean으로 등록하는 기능이다. 개발자가 Bean을 직접 등록하지 않고도 Spring이 자동으로 관리할 객체들을 찾는다.
ComponentScan의 역할
Chef가 요리할 재료를 자동으로 식료품 저장고에서 찾아오는 과정, Chef는 스스로 필요한 재료를 찾아 요리에 사용한다.
요리사(개발자)가 직접 재료(Bean)를 찾아서 가져올 필요가 없다.
@ComponentScan
특정 패키지 내에 @Component Annotation이 붙은 클래스를 자동으로 찾아서 Spring Bean으로 등록한다.
Annotation을 이용해 Bean을 등록할 수 있어 코드가 간결해지고 유지보수가 쉬워진다.
스캐닝 범위는 주로 애플리케이션의 루트(최상위) 패키지에서 시작된다.
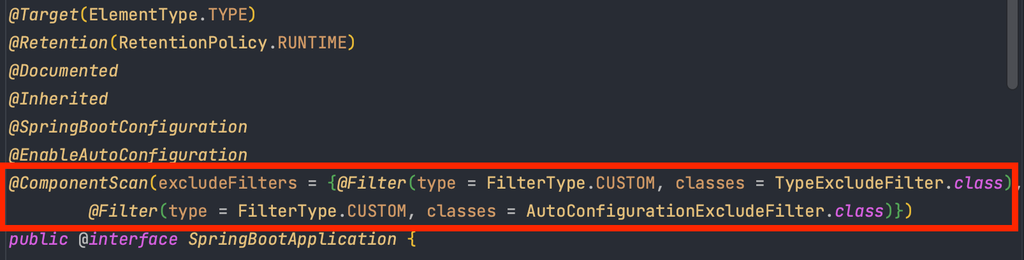
@SpringBootApplication
스프링 부트 애플리케이션의 시작점을 정의하기 위해 사용하는 애너테이션입니다. 이 애너테이션은 여러 기능을 결합한 복합 애너테이션으로, 스프링 부트 애플리케이션을 간단히 설정하고 실행할 수 있도록 돕습니다.
SpringBoot로 프로젝트를 생성하면 main() 메서드가 있는 클래스 상단에 @SpringBootApplication Annotation 이 존재한다.
@ComponentScan의 속성
basePackages: 특정 패키지를 스캔할 때 사용, 배열로 여러개를 선언할 수 있다.
Spring Application이 실행되면 @ComponentScan이 지정된 패키지를 탐색한다.
@ComponentScan은 @Component, @Service, @Repository, @Controller 등의 애너테이션이 붙은 클래스를 탐색합니다.
해당 클래스들을 스프링 빈으로 등록합니다.
구현 클래스뿐만 아니라, 인터페이스와 그 구현체도 함께 빈으로 등록됩니다.
2. 의존성 정의 (인터페이스 기반 설계)
일반적으로 **인터페이스(추상화)**를 의존성으로 정의합니다. 구현체는 스프링이 자동으로 선택하고 주입합니다.
3. 구현체 자동 연결
스프링은 등록된 빈 중에서 의존성으로 선언된 인터페이스에 맞는 구현체를 자동으로 찾아 주입합니다.
이 과정은 타입 매칭을 통해 이루어집니다.
@Configuration, @Bean
📌 Spring Bean을 등록하는 방법에는 수동, 자동 두가지가 존재한다.
Spring Bean 등록 방법
Spring Bean은 Bean의 이름으로 등록된다.
1. 자동 Bean 등록(@ComponentScan, @Component)
@Component 이 있는 클래스의 앞글자만 소문자로 변경하여 Bean 이름으로 등록한다.
// myService 라는 이름의 Spring Bean
@Component
public class MyService {
public void doSomething() {
System.out.println("Spring Bean 으로 동작");
}
}
@ComponentScan 을 통해 @Component로 설정된 클래스를 찾는다.
2. 수동 Bean 등록(@Configuration, @Bean)
@Configuration 이 있는 클래스를 Bean으로 등록하고 해당 클래스를 파싱해서 @Bean 이 있는 메서드를 찾아 Bean을 생성한다. 이때 해당 메서드의 이름으로 Bean의 이름이 설정된다.
// 인터페이스
public interface TestService {
void doSomething();
}
// 인터페이스 구현체
public class TestServiceImpl implements TestService {
@Override
public void doSomething() {
System.out.println("Test Service 메서드 호출");
}
}
// 수동으로 빈 등록
@Configuration
public class AppConfig {
// TestService 타입의 Spring Bean 등록
@Bean
public TestService testService() {
// TestServiceImpl을 Bean으로 등록
return new TestServiceImpl();
}
}
// Spring Bean으로 등록이 되었는지 확인
public class MainApp {
public static void main(String[] args) {
// Spring ApplicationContext 생성 및 설정 클래스(AppConfig) 등록
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
// 등록된 TestService 빈 가져오기
TestService service = context.getBean(TestService.class);
// 빈 메서드 호출
service.doSomething();
}
}
수동으로 Bean을 등록할 때는 항상@Configuration과 함께 사용해야 Bean이 싱글톤으로 관리된다. CGLIB 라이브러리와 연관이 있다.
**@Configuration**은 스프링에서 Java Config 클래스를 정의할 때 사용하는 애너테이션입니다. 이 애너테이션을 붙인 클래스는 스프링 컨테이너가 관리하는 설정 클래스로 동작하며, 해당 클래스에 정의된 Bean은 싱글톤으로 관리됩니다.
싱글톤 관리:
@Configuration이 붙은 클래스는 내부적으로 CGLIB 동적 프록시 객체로 변환됩니다.
이 프록시 객체는 @Bean 메서드 호출 시, 이미 생성된 Bean이 있으면 이를 반환하고, 없으면 새로운 Bean을 생성합니다.
이를 통해 동일한 Bean이 여러 번 생성되지 않도록 보장합니다.
Bean 충돌
📌 Bean 등록 방법에는 수동, 자동 두가지가 존재하고 Bean은 각각의 이름으로 생성된다. 이때 이름이 같은 Bean이 설정되고자 한다면 충돌이 발생한다.
같은 이름의 Bean 등록
자동 Bean 등록 VS 자동 Bean 등록
public interface ConflictService {
void test();
}
// Bean의 이름을 service로 설정
@Component("service")
public class ConflictServiceV1 implements ConflictService {
@Override
public void test() {
System.out.println("Conflict V1");
}
}
// Bean의 이름을 service로 설정
@Component("service")
public class ConflictServiceV2 implements ConflictService {
@Override
public void test() {
System.out.println("Conflict V2");
}
}
// componentScan의 범위를 conflict 패키지 하위로 설정
@ComponentScan(basePackages = "com.example.springconcept.conflict")
public class ConflictApp {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(ConflictApp.class);
// Service 빈을 가져와서 실행
ConflictService service = context.getBean(ConflictService.class);
service.test();
}
}
ConflictingBeanDefinitionException 발생
수동 Bean 등록 VS 자동 Bean 등록
// conflictService 이름으로 Bean 생성
@Component
public class ConflictService implements MyService {
@Override
public void doSomething() {
System.out.println("ConflictService 메서드 호출");
}
}
public class ConflictServiceV2 implements MyService {
@Override
public void doSomething() {
System.out.println("ConflictServiceV2 메서드 호출");
}
}
// 수동으로 Bean 등록
@Configuration
public class ConflictAppConfig {
// conflictService 이름으로 Bean 생성
@Bean(name = "conflictService")
MyService myService() {
return new ConflictServiceV2();
}
}
@ComponentScan(basePackages = "com.example.springconcept.conflict2")
public class ConflictApp2 {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(ConflictApp2.class);
// Service 빈을 가져와서 실행
MyService service = context.getBean(MyService.class);
service.doSomething();
}
}
수동 Bean 등록이 자동 Bean 등록을 오버라이딩해서 우선권을 가진다.
의도한 결과라면 다행이지만, 아닌 경우(실수)가 대부분이다. → 버그 발생
Spring Boot에서는 수동과 자동 Bean등록의 충돌이 발생하면 오류가 발생한다.
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
// 수동, 자동 Bean을 동시에 등록할 때 이름이 같으면 수동 Bean이 오버라이딩
spring.main.allow-bean-definition-overriding=true
// 기본값
spring.main.allow-bean-definition-overriding=false
@Qualifier, @Primary
📌 같은 타입의 Bean이 중복된 경우 해결하기 위해 사용하는 Annotation
같은 타입의 Bean 충돌 해결 방법
@Autowired + 필드명 사용
@Autowired 는 타입으로 먼저 주입을 시도하고 같은 타입의 Bean이 여러개라면 필드 이름 혹은 파라미터 이름으로 매칭한다.
public interface MyService { ... }
@Component
public class MyServiceImplV1 implements MyService { ... }
@Component
public class MyServiceImplV2 implements MyService { ... }
@Component
public class ConflictApp {
// 필드명을 Bean 이름으로 설정
@Autowired
private MyService myServiceImplV2;
...
}
@Qualifier 사용
Bean 등록 시 추가 구분자를 붙여 준다.
생성자 주입, setter 주입 사용 가능
@Component
@Qualifier("firstService")
public class MyServiceImplV1 implements MyService { ... }
@Component
@Qualifier("secondService")
public class MyServiceImplV2 implements MyService { ... }
@Component
public class ConflictApp {
private MyService myService;
// 생성자 주입에 구분자 추가
@Autowired
public ConflictApp(@Qualifier("firstService") MyService myService) {
this.myService = myService;
}
// setter 주입에 구분자 추가
@Autowired
public void setMyService(@Qualifier("firstService") MyService myService) {
this.myService = myService;
}
...
}
@Primary 사용
@Primary로 지정된 Bean이 우선 순위를 가진다.
@Component
public class MyServiceImplV1 implements MyService { ... }
@Component
@Primary
public class MyServiceImplV2 implements MyService { ... }
@Component
public class ConflictApp {
private MyService myService;
@Autowired
public ConflictApp(MyService myService) {
this.myService = myService;
}
...
}
실제 적용 사례
Database가 (메인 MySQL, 보조 Oracle) 두개 존재하는 경우
기본적으로 MySQL을 사용할 때 @Primary를 사용하면 된다.
필요할 때 @Qualifier로 Oracle을 사용하도록 만들 수 있다.
동시에 사용되는 경우 @Qualifier 의 우선순위가 높다.
같은 타입의 Bean이 여러개 조회되었지만 모든 Bean이 필요하다면, Java의 자료구조 Map, List를 사용하는 방법도 있다.
수동 VS 자동
📌 Annotation 기반의 Spring에서는 자동 Bean 등록과 의존관계 주입을 사용하는 경우를 주로 사용한다. @Component 뿐만 아니라 @Controller, @Service, @Repository 등 자동으로 쉽게 등록할 수 있는 Annotation들을 지원하고 Spring Boot는 ComponentScan 방식을 기본으로 사용한다.
📌 Spring으로 구성된 애플리케이션에서 객체(Bean)를 생성, 관리, 소멸하는 역할을 담당한다. 애플리케이션 시작 시, 설정 파일이나 Annotation을 읽어 Bean을 생성하고 주입하는 모든 과정을 컨트롤한다. 심지어는 의존성마저 주입한다.
총괄주방장 = shef 라고 보면 편하다.
Spring Container를 사용하면 인터페이스에만 의존하는 설계가 가능해진다.
OCP, DIP 준수
Spring Container의 종류
BeanFactory
Spring Container의 최상위 인터페이스
Spring Bean을 관리하고 조회한다.
ApplicationContext
BeanFactory의 확장된 형태(implements) -> 진화된 버전
Application 개발에 필요한 다양한 기능을 추가적으로 제공한다.
국제화, 환경변수 분리, 이벤트, 리소스 조회
일반적으로 ApplicationContext를 사용하기 때문에 ApplicationContext를 Spring Container라 표현한다.
Spring Bean
📌 Spring 컨테이너가 관리하는 객체를 의미한다. 자바 객체 자체는 특별하지 않지만, Spring이 이 객체를 관리하는 순간부터 Bean이 된다. Spring은 Bean을 생성, 초기화, 의존성 주입 등을 통해 관리한다.
모든 객체가 Bean인게 아니라 spring container가 관리하는 객체를 bean이라 하는 것
Bean은 new 키워드 대신 사용하는 것이다.
Spring Container가 제어한다.
Spring Bean의 역할
Chef인 Spring Container가 요리할 음식에 사용될 재료(Bean)
요리(Application)의 핵심을 이루는 재료(Bean)
Spring Bean의 특징
Spring 컨테이너에 의해 생성되고 관리된다.
기본적으로 Singleton( 애플리케이션 전역에서 단 하나의 인스턴스만 생성하도록 보장하는 디자인 패턴 )으로 설정된다.
의존성 주입(DI)을 통해 다른 객체들과 의존 관계를 맺을 수 있다.
생성, 초기화, 사용, 소멸의 생명주기를 가진다.
Bean 등록 방법
XML, Java Annotation, Java 설정파일 등을 통해 Bean으로 등록할 수 있다.
XML
<beans>
<!-- myBean이라는 이름의 Bean 정의 -->
<bean id="myBean" class="com.example.MyBean" />
</beans>
--------------------------------------------------------------------
public class MyApp {
public static void main(String[] args) {
// Spring 컨테이너에서 Bean을 가져옴
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
MyService myService = context.getBean("myService", MyService.class);
myService.doSomething();
}
}
Annotation
@ComponentScan
개발자가 일일이 빈(Bean)을 설정하지 않아도, 지정한 패키지에서 필요한 클래스들을 자동으로 찾아서 애플리케이션 컨텍스트에 빈(Bean) 등록해 줍니다.
// 이 클래스를 Bean으로 등록
// @Controller, @Service, @Repository
@Component
public class MyService {
public void doSomething() {
System.out.println("Spring Bean 으로 동작");
}
}
------------------------------------
@Component
public class MyApp {
private final MyService myService;
@Autowired // 의존성 자동 주입
public MyApp(MyService myService) {
this.myService = myService;
}
public void run() {
myService.doSomething();
}
}
---------------------------------------------
// com.example 패키지를 스캔하여 Bean 등록
@Configuration
@ComponentScan(basePackages = "com.example")
public class AppConfig {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
MyApp app = context.getBean(MyApp.class);
app.run();
}
}
Java 설정파일
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyService();
}
}
------------------------------------
public class MyApp {
public static void main(String[] args) {
// Spring 컨테이너에서 Bean을 가져옴
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
MyService myService = context.getBean(MyService.class);
myService.doSomething();
}
}
IOC(제어의 역전, Inversion Of Control)
📌 객체의 생성과 관리 권한을 개발자가 아닌 Spring 컨테이너가 담당하는 것을 말한다. 기본적으로 개발자가 객체를 직접 생성하고 관리했지만, Spring에서는 컨테이너가 객체 생성, 주입, 소멸을 관리한다.
요리사(개발자)는 필요한 재료를 직접 준비하지 않고, Chef가 알아서 필요한 재료(Bean)을 관리하고 요리사에게 가져다준다.
IoC 개념
객체의 생성 및 생명주기 관리를 개발자가 직접 하는 것이 아니라 컨테이너가 담당한다.
객체 간의 결합도를 낮춰 유연한 코드가 된다.
DI(의존성 주입, Dependency Injection)
📌 Spring이 객체 간의 의존성을 자동으로 주입해주는 것을 의미한다. 한 객체가 다른 객체를 사용할 때, 해당 객체를 직접 생성하지 않고 Spring이 주입해주는 방식이다. IOC를 구현하는 방식 중 하나이다.
셰프가 요리를 만들 때 필요한 재료(Bean)를 자동으로 요리사에게 가져다주는 과정
요리사(개발자)는 재료를 찾을 필요 없이, Chef가 알아서 제공해준다.
의존성 = 추상화가 아닌 이유
의존성이란, 한 객체가 다른 객체를 사용하거나 그 객체의 기능에 의존하는 관계를 말합니다. 그리고 추상화는 의존성을 설계하는 중요한 방식 중 하나입니다. 하지만 의존성이 항상 추상화와 동일한 개념은 아닙니다. 의존성과 추상화의 관계를 설명하겠습니다.
의존성은 설계의 결과, 추상화는 설계의 방법:
의존성은 클래스 간의 관계를 나타냅니다.
추상화는 의존성을 관리하거나 줄이기 위한 설계 기법입니다.
구체적인 의존성도 존재:
의존성이 항상 추상화된 타입에만 연결되지 않습니다.
구체 클래스에 대한 의존성도 의존성의 한 형태입니다.
IOC, DI 주입 개발자, SPRING 비교
// Service 인터페이스
public interface MyService {
void doSomething();
}
// Repository 인터페이스
public interface MyRepository {
void queryDatabase();
}
// Service 구현체
public class MyServiceImpl implements MyService {
private MyRepository myRepository;
// 의존성 주입
public MyServiceImpl(MyRepository myRepository) {
this.myRepository = myRepository;
}
@Override
public void doSomething() {
System.out.println("서비스 작업 실행");
myRepository.queryDatabase();
}
}
// Repository 구현체
public class MyRepositoryImpl implements MyRepository {
@Override
public void queryDatabase() {
System.out.println("데이터베이스 쿼리 실행");
}
}
public class MyApp {
public static void main(String[] args) {
MyRepository repo = new MyRepositoryImpl();
// MyRepository repo2 = new MyRepositoryImplV2();
MyService myService = new MyServiceImpl(repo);
// MyService myService2 = new MyServiceImpl(repo2);
myService.doSomething();
}
}
// 새로운 Repository 구현체
public class MyRepositoryImplV2 implements MyRepository {
@Override
public void queryDatabase() {
System.out.println("데이터베이스 쿼리 실행 V2");
}
}
---------------------------------
// Service 구현체
@Service
public class MyIocService implements MyService {
private final MyRepository myRepository;
// 생성자 주입(DI 적용)
@Autowired: 스프링이 자동으로 MyRepository 타입의 빈(Bean)을 찾아 생성자에 주입하도록 지시합니다.
public MyIocService(MyRepository myRepository) {
this.myRepository = myRepository;
}
@Override
public void doSomething() {
System.out.println("IOC 서비스 작업 실행");
myRepository.queryDatabase();
}
}
// Repository 구현체
@Repository
public class MyIocRepository implements MyRepository {
@Override
public void queryDatabase() {
// 데이터베이스와 상호작용
System.out.println("IOC 데이터베이스 쿼리 실행");
}
}
// Spring Container 관리(IoC 적용)
@ComponentScan(basePackages = "com.example")
: @ComponentScan으로 지정된 com.example 패키지를 스캔하여 빈으로 등록할 클래스들을 검색합니다.
public class MyIocApp {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(MyIocApp.class);
// Service 빈을 가져와서 실행
MyService service = context.getBean(MyService.class);
service.doSomething();
}
}
// 새로운 Repository 구현체
@Repository
public class MyIocRepositoryV2 implements MyRepository {
@Override
public void queryDatabase() {
// 데이터베이스와 상호작용
System.out.println("IOC 데이터베이스 쿼리 실행 V2");
}
}
구현 코드가 변경되어도 클라이언트의 코드에는 영향이 없다.
다른 구현체를 구현하여 Bean으로 등록하면 자유롭게 변경이 가능하다.
위 예시 코드는 @Repository 로 등록된 빈이 중복되어 충돌이 발생한다.
의존성 주입(DI), 제어의 역전(IOC)을 통해 객체 간의 결합도를 낮추고 유연한 설계가 가능해진다.
IOC/DI
IoC는 객체의 제어권을 개발자가 아닌 Spring 컨테이너에게 넘기는 개념으로, Spring이 객체 생성과 관리를 담당한다.
스프링에서 Bean을 기본적으로 싱글톤으로 사용하는 이유는 싱글톤 패턴의 장점을 최대한 활용하면서도, 패턴 자체의 단점들을 해결하기 때문입니다. 이를 단계적으로 설명하겠습니다.
싱글톤 패턴의 장점
리소스 절약:
객체를 한 번만 생성하고 재사용하므로 메모리와 리소스를 절약할 수 있습니다.
전역 접근 가능:
애플리케이션 전체에서 동일한 인스턴스를 사용할 수 있어 상태 관리나 공유 자원 관리가 용이합니다.
싱글톤 패턴의 단점과 스프링의 해결책
1. 구현이 복잡하다 (코드가 많다)
문제점:
싱글톤 패턴을 구현하려면 추가적인 코드(정적 변수, 동기화 처리 등)가 필요합니다.
이를 잘못 구현하면 멀티스레드 환경에서 안전하지 않을 수 있습니다.
스프링의 해결:
스프링 컨테이너가 싱글톤 관리를 대신합니다.
개발자는 객체 생성 방식을 신경 쓸 필요 없이, @Component, @Service, @Repository 등의 애너테이션만 추가하면 스프링이 자동으로 관리합니다.
2. 구현 클래스에 의존 (DIP, OCP 위반)
문제점:
싱글톤 패턴은 클래스 자체에서 객체를 관리하기 때문에 구체 클래스에 의존하게 됩니다.
이는 **의존성 역전 원칙(DIP)**과 **개방-폐쇄 원칙(OCP)**을 위반할 가능성을 높입니다.
스프링의 해결:
스프링은 **DI(Dependency Injection)**를 사용하여 의존성을 주입합니다.
Bean을 인터페이스 기반 설계로 사용할 수 있게 하여 DIP를 준수합니다.
개발자는 객체 생성 방식을 몰라도 컨테이너가 관리하는 객체를 사용할 수 있으므로 OCP를 준수합니다.
3. 테스트 어려움
문제점:
싱글톤 객체는 전역 상태를 공유하기 때문에 테스트에서 객체의 상태를 초기화하거나 Mock 객체로 대체하기 어렵습니다.
스프링의 해결:
스프링은 DI를 통해 의존성을 주입하므로, 테스트 환경에서 Mock 객체를 쉽게 주입할 수 있습니다.
빈의 스코프를 싱글톤 이외로 설정(예: 프로토타입 스코프)할 수도 있습니다.
4. 유연성 부족 (안티패턴)
문제점:
전역 상태를 공유하는 싱글톤 객체는 설계의 유연성을 저하시켜 애플리케이션의 확장과 변경에 제약을 줄 수 있습니다.
스프링의 해결:
스프링은 필요에 따라 Bean의 **스코프(scope)**를 변경할 수 있습니다:
싱글톤(Singleton): 기본 설정, 모든 요청에서 동일한 인스턴스를 공유.
프로토타입(Prototype): 요청 시마다 새로운 인스턴스 생성.
요청(Request): HTTP 요청마다 새로운 인스턴스 생성.
세션(Session): HTTP 세션마다 새로운 인스턴스 생성.
웹 소켓(WebSocket): 웹소켓 연결마다 새로운 인스턴스 생성.
스프링이 싱글톤을 사용하는 이유
스프링은 싱글톤 패턴의 단점을 해결하면서도, 다음과 같은 이유로 싱글톤을 기본으로 사용합니다:
효율성:
애플리케이션에서 동일한 빈을 여러 번 생성하지 않고, 한 번 생성된 객체를 재사용하여 리소스를 절약합니다.
글로벌 상태 관리:
데이터베이스 연결, 캐시, 설정 정보 등 전역적으로 공유할 필요가 있는 객체를 관리하기 적합합니다.
유연성:
스프링은 개발자가 직접 싱글톤 패턴을 구현하지 않아도, 컨테이너가 이를 관리합니다.
필요에 따라 스코프를 변경하거나 테스트 시 Mock 객체로 대체할 수 있습니다.
단순화된 코드:
개발자는 @Component, @Service 등 애너테이션만으로 빈을 정의하고 사용할 수 있습니다. 싱글톤 관리 로직을 작성할 필요가 없습니다.
결론
스프링은 싱글톤 패턴의 장점을 최대한 활용하면서, **DI(의존성 주입)**와 유연한 스코프 관리를 통해 단점들을 극복했습니다. 이로 인해 스프링의 Bean은 싱글톤을 기본으로 사용하면서도 효율적이고 확장 가능한 구조를 제공합니다.
Singleton Pattern의 주의
📌 객체의 인스턴스를 하나만 생성하여 공유하는 싱글톤 패턴의 객체는 상태를 유지(stateful)하면 안된다.
지역 변수라면 변수여도 된다. 하지만 요청마다 값이 변경되거나 외부에서 변경 가능한 데이터가 싱글톤 객체에 저장되면 문제가 생길 수 있다.
즉 공유 객체( 여러 사용자나 스레드가 동시에 접근하여 값을 읽거나 수정할 수 있는 데이터 )는 안된다.
상태 유지(stateful)의 문제점
데이터의 불일치나 동시성 문제가 발생할 수 있다.
코드예시
public class StatefulSingleton {
private static StatefulSingleton instance;
// 상태를 나타내는 필드
private int value;
// private 생성자
private StatefulSingleton() {}
// 싱글톤 인스턴스를 반환하는 메서드
public static StatefulSingleton getInstance() {
if (instance == null) {
instance = new StatefulSingleton();
}
return instance;
}
// 상태 변경 메서드
public void setValue(int value) {
this.value = value;
}
// 상태를 반환하는 메서드
public int getValue() {
return this.value;
}
}
public class MainApp {
public static void main(String[] args) {
// 클라이언트 1: 싱글톤 인스턴스를 가져와서 상태를 설정
StatefulSingleton client1 = StatefulSingleton.getInstance();
client1.setValue(42);
System.out.println("클라이언트 1이 설정한 값: " + client1.getValue());
// 클라이언트 2: 동일한 싱글톤 인스턴스를 사용해 상태를 변경
StatefulSingleton client2 = StatefulSingleton.getInstance();
client2.setValue(100);
System.out.println("클라이언트 2가 설정한 값: " + client2.getValue());
// 클라이언트 1이 다시 값을 확인
System.out.println("클라이언트 1이 다시 확인한 값: " + client1.getValue());
}
}
클라이언트 1이 설정한 값: 42 클라이언트 2가 설정한 값: 100 클라이언트 1이 다시 확인한 값: 100
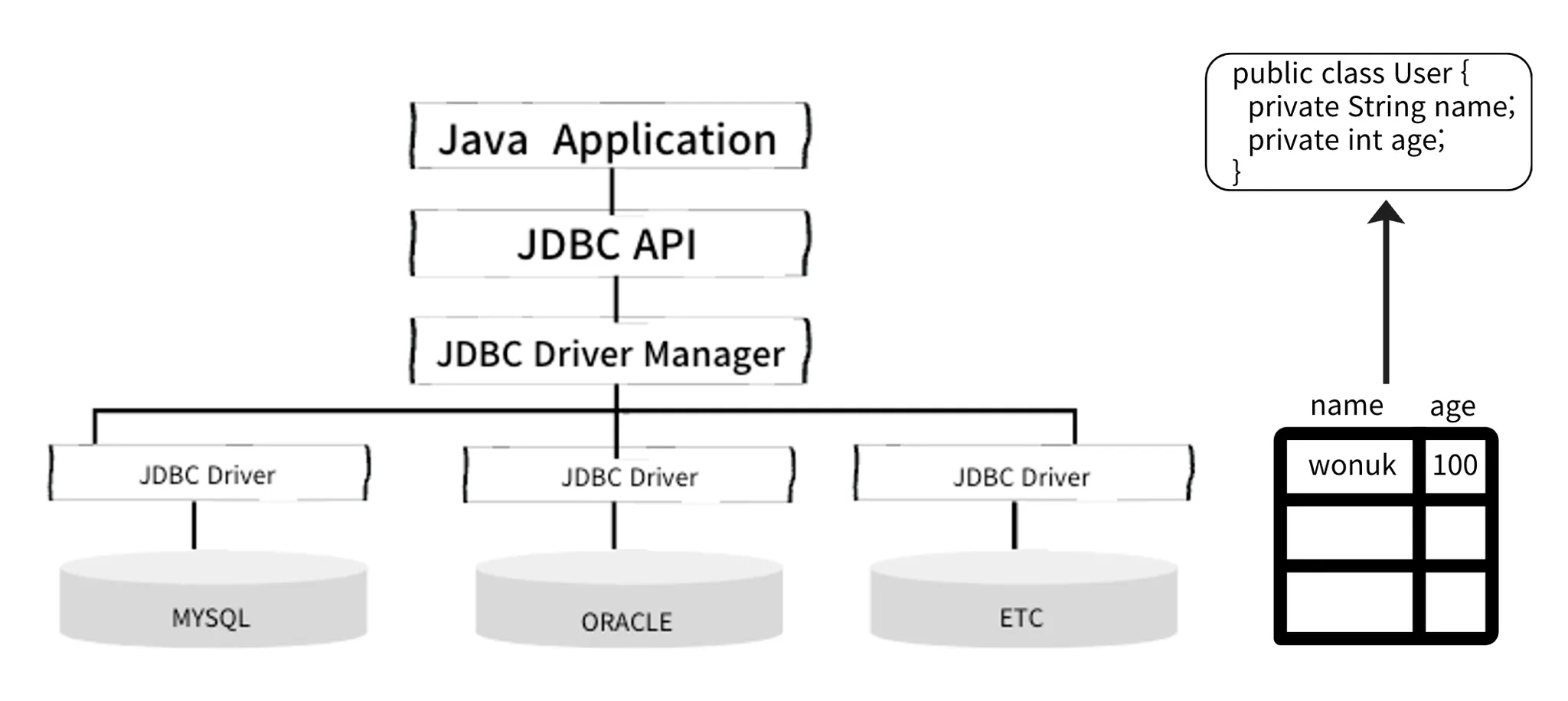
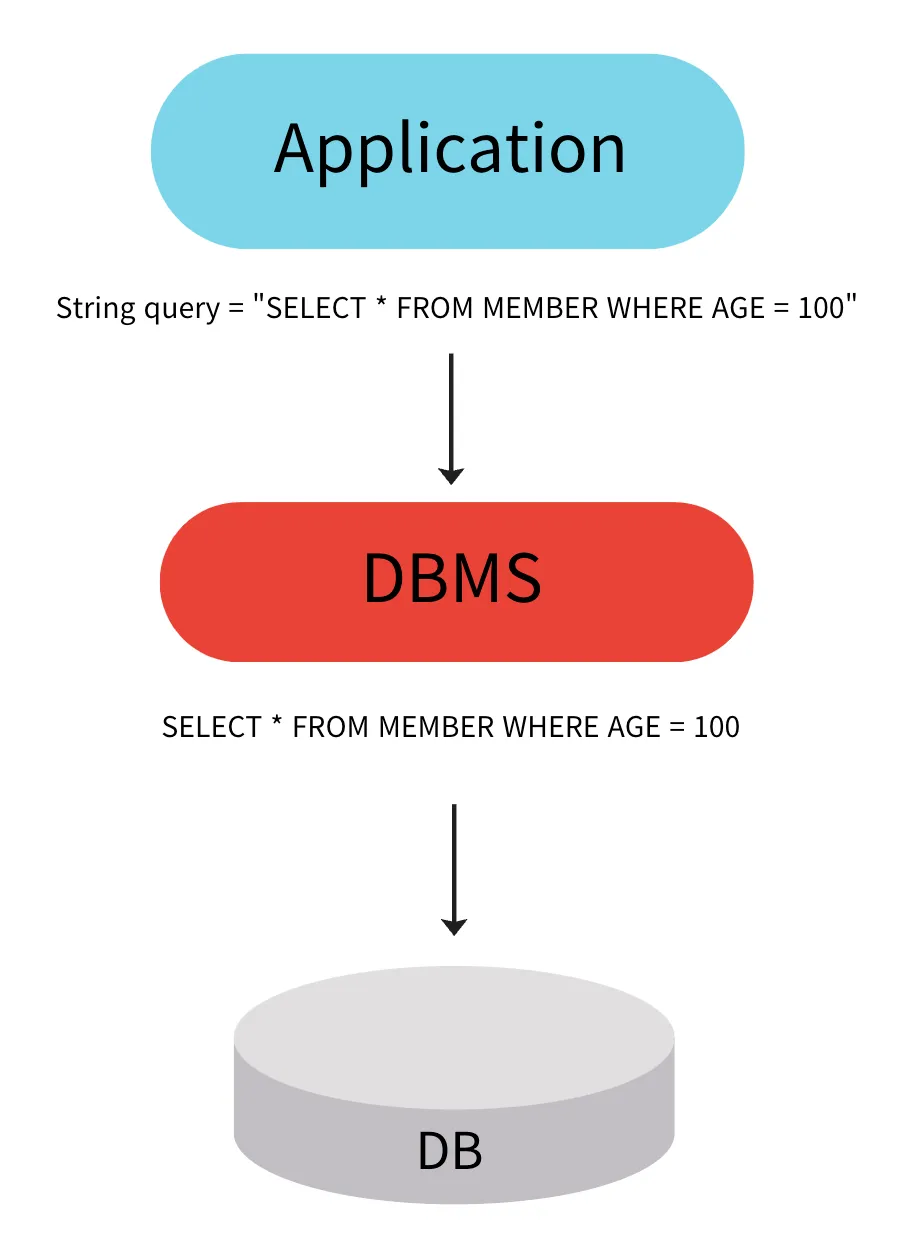
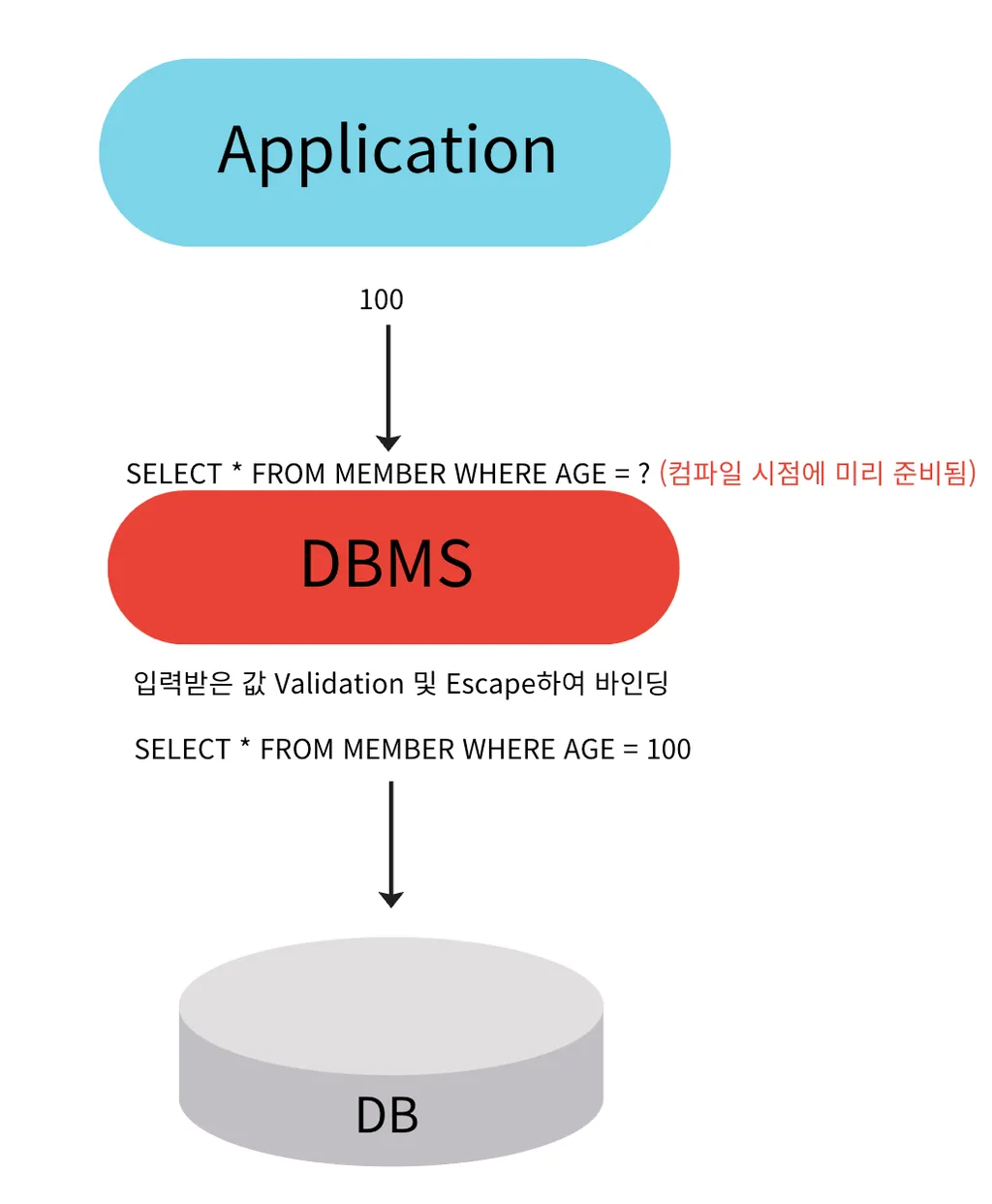
📌 애플리케이션에서 데이터를 영구적으로 저장하고 관리하기 위해 데이터베이스와 같은 저장소와의 상호 작용을 단순화하는 소프트웨어 도구이다.
Persistence Framework 개요
JDBC의 한계
간단한 SQL을 실행하는 경우에도 중복된 코드가 너무 많았다.
public class PreparedStatementExample {
public static void main(String[] args) {
try {
// ojdbc6.jar[oracle.jdbc.driver.OracleDriver] 파일을 라이브러리에 추가한다.
Class.forName("oracle.jdbc.driver.OracleDriver");
// 1. Connection
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
String query = "SELECT * FROM employees WHERE department = ?";
// 2. Statement
PreparedStatement preparedStatement = connection.prepareStatement(query);
// 값을 설정
preparedStatement.setString(1, "HR");
// 3. ResultSet
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
// 결과 처리 코드
}
resultSet.close();
preparedStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
onnection, Prepared Statement, ResultSet 등
DB에 따라 일관성 없는 정보를 가진 채로 Checked Exception(SQL Exception) 처리를 한다.
Checked Exception인 SQLException은 개발자가 명시적으로 처리해야 한다.
각 DBMS는 고유한 SQL 문법과 오류 코드 체계를 가지고 있다.
JDBC에서 발생하는 SQLException은 이러한 DBMS에 따라 달라질 수 있으며, 예외 메시지나 코드도 DB마다 다를 수 있다. 즉, 모두 그에 맞게 처리해야 한다.
Connection과 같은 공유 자원을 제대로 반환하지 않으면 한정된 시스템 자원(CPU, Memory)에 의해 서버가 다운되는 등의 문제가 발생한다.
SQL Query를 개발자가 직접 작성한다.
중복 적인 쿼리 및 코드 작성이 필요하다.
대부분의 테이블에 CRUD하는 쿼리가 포함된다.
Persistence Framework의 등장
JDBC 처럼 복잡함이나 번거로움 없이 간단한 작업만으로 Database와 연동되는 시스템
모든 Persistence Framework는 내부적으로 JDBC API를 이용한다.
preparedStatement를 기본적으로 사용한다.
→ 위에서 JDBC를 설명한 이유.
크게 SQL Mapper, ORM 두가지로 나눌 수 있다.
JDBC, SQL MAPPER, ORM의 공통점
영속성(Persistence) 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성, 영구히 저장되는 특성
Persistence Framework의 역할
데이터 접근 로직 간소화:
JDBC와 같은 저수준 API의 반복 작업을 제거.
객체와 관계형 데이터 매핑:
객체지향 언어(Java)의 데이터와 관계형 데이터베이스 간의 불일치를 해결.
트랜잭션 관리:
데이터 작업을 트랜잭션 단위로 처리하여 데이터 무결성 보장.
데이터베이스 독립성:
특정 데이터베이스에 종속되지 않고, 다양한 RDBMS와 연동 가능.
쿼리 생성 최적화:
동적 쿼리 생성을 자동화하거나 간소화.
Persistence Framework의 특징
ORM (Object-Relational Mapping):
객체 모델과 관계형 데이터베이스를 매핑.
데이터베이스 작업을 객체지향 방식으로 처리.
SQL 추상화:
SQL 쿼리를 자동 생성하거나 간소화된 API로 대체.
트랜잭션 지원:
ACID 특성을 보장하는 트랜잭션 처리.
데이터베이스 연결 관리:
커넥션 풀을 사용해 데이터베이스 연결 성능을 최적화.
주요 Persistence Framework
a. Hibernate
설명: JPA(Java Persistence API)의 구현체 중 하나로 가장 널리 사용됨.
특징:
완전한 ORM 지원.
동적 쿼리 및 캐시 지원.
다양한 데이터베이스와 호환 가능.
b. JPA (Java Persistence API)
설명: Java 표준 ORM API로, 데이터베이스와 객체 간 매핑을 정의.
특징:
Hibernate, EclipseLink와 같은 구현체가 필요.
표준화된 인터페이스 제공.
c. MyBatis
설명: SQL 매핑 기반의 Persistence Framework.
특징:
SQL을 직접 작성하여 세부적인 제어 가능.
자동 매핑 기능 지원 (SQL 결과와 객체 매핑).
d. Spring Data JPA
설명: JPA를 더 간단하게 사용할 수 있도록 지원하는 Spring 모듈.
특징:
기본 CRUD 작업을 간소화.
Repository 패턴 지원.
e. EclipseLink
설명: JPA의 또 다른 구현체로, Oracle과 밀접한 통합.
특징:
성능 최적화와 고급 기능 지원.
ORM과 SQL 매핑 프레임워크 비교
ORM (Hibernate, JPA)
SQL 매핑 (MyBatis)
쿼리 작성 방식
자동 생성 (HQL, JPQL)
직접 작성 (SQL 문장 사용).
생산성
높은 추상화로 간단한 작업은 편리.
복잡한 쿼리 작성에 유리.
유연성
쿼리 최적화가 어려울 수 있음.
세부적인 제어 가능.
학습 곡선
ORM의 개념 이해 필요.
SQL 지식만으로 쉽게 접근 가능.
사용 사례
CRUD 중심의 애플리케이션.
복잡한 데이터 조작 및 최적화된 쿼리 필요.
Persistence Framework의 장점
생산성 향상:
데이터 접근 로직을 간소화.
데이터베이스 독립성:
다양한 RDBMS와 호환 가능.
코드 간결화:
CRUD 작업의 반복 코드를 제거.
트랜잭션 관리:
ACID 특성을 쉽게 적용 가능.
객체-관계 매핑:
객체지향적인 데이터 접근 가능.
Persistence Framework의 단점
복잡성 증가:
ORM 개념 학습과 설정이 필요.
쿼리 최적화 한계:
ORM에서는 복잡한 SQL 튜닝이 어려울 수 있음.
퍼포먼스 문제:
자동 생성된 쿼리가 비효율적일 수 있음.
추상화의 비용:
프레임워크의 내부 동작을 이해해야 문제를 해결 가능.
Persistence Framework 선택 가이드
요구사항
권장 프레임워크
간단한 CRUD 애플리케이션
Spring Data JPA, Hibernate
복잡한 SQL 쿼리 작업
MyBatis
높은 데이터베이스 독립성 필요
JPA
빠르고 세부적인 SQL 제어 필요
MyBatis
대규모 트랜잭션 관리 및 확장성 요구
Hibernate, JPA
SQL Mapper
📌 SQL 쿼리와 객체(Object) 간의 매핑을 지원하는 도구입니다. 직접 작성한 SQL 문의 실행 결과와 객체(Object)의 필드를 Mapping하여 데이터를 객체화한다. 대표적인 SQL Mapper로 Spring JDBC Template, MyBatis가 있다.
Spring JDBC Template
Spring Framework에서 제공하는 JDBC 작업을 단순화하고 개선한 유틸리티 클래스
JDBC Template의 장점
간편한 데이터베이스 연결
손수 적었던 Connection 관련 코드들을 yml 혹은 properties 파일에 설정만으로 해결한다.
Prepared Statement를 사용한다.
예외 처리와 리소스 관리
DB Connection을 자동으로 처리하여 리소스 누수를 방지한다.
결과 집합(ResultSet) 처리
데이터를 자바 객체로 변환할 수 있도록 돕는다.
배치 처리 작업을 지원한다.
매일 동일한 시간에 수행되는 쿼리, 주로 통계에 사용된다.
// 1. XML OR Gradle에 Spring JDBC 의존성 추가
// 2. application.properties OR application.yml에 데이터베이스 연결 설정
@RestController
public class MemberController {
private final MemberRepository memberRepository;
public MemberController(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@GetMapping("/members")
public List<Member> findById(Long id) {
return memberRepository.findById(id);
}
}
// Member Object
public class Member {
private Long id;
private String name;
private int age;
// Getter and Setter methods
}
// Repository Anotation의 역할에 대해 공부해주세요.
@Repository
public class MemberRepository {
private final JdbcTemplate jdbcTemplate;
public MemberRepository(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// Member 객체로 리턴한다.
public List<Member> findById(Long id) {
String query = "SELECT * FROM MEMBER WHERE id = " + id;
return jdbcTemplate.query(query, (rs, rowNum) -> {
Member member = new Member ();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
member.setAge(rs.getInt("age"));
return member;
});
}
}
대표적인 SQL Mapper
MyBatis:
SQL 기반의 가장 널리 사용되는 SQL Mapper.
간단한 XML 매핑 설정으로 SQL과 객체를 연결.
JDBC Template (Spring):
Spring에서 제공하는 SQL 처리 도구.
SQL Mapper와 비슷한 역할 수행.
iBatis:
MyBatis의 이전 버전으로, MyBatis로 발전됨.
SQL Mapper의 한계
SQL을 직접 다룬다.
특정 DB에 종속적으로 사용하기 쉽다.
DB마다 Query문, 함수가 조금씩 다르다.
→ 다른 DB를 사용하면 쿼리도 변경해야할 가능성이 높다.
테이블마다 비슷한 CRUD SQL, DAO(Data Access Object) 개발이 반복된다. → 코드 중복
테이블 필드가 변경될 시 이와 관련된 모든 DAO의 SQL문, 객체의 필드 등을 수정해야 한다.
코드상으로 SQL과 JDBC API를 분리했지만 논리적으로 강한 의존성을 가지고 있다.
객체와의 관계는 사라지고 DB에 대한 처리에 집중하게 된다. → SQL 의존적인 개발
관계형 DB와 객체지향의 패러다임 불일치
객체지향으로 설계된것을 관계형 DB에 저장하기란 어렵다.
테이블에 저장한 데이터를 다시 객체화 하는것도 어렵다.
// 1. 객체 안의 객체
public class Member {
// 필드들..
private Team team;
} -> ERD?
// 2. 상속 구조
public class Member extends Person {
// 필드들..
} -> ERD?
// 3. extends, implements
public class Member extends Person implements Workable {
// 필드들..
} -> ERD?