트랜잭션 전파
📌 하나의 트랜잭션이 다른 트랜잭션 내에서 어떻게 동작할지를 결정하는 규칙으로 여러 개의 트랜잭션이 포함된 시스템에서 특정 작업이 다른 작업에 어떻게 영향을 미칠지를 정의한다.
- 현재 클래스의 트랜잭션과 다른 클래스의 트랜잭션을 교통정리 한다.

- 트랜잭션이 여러 계층 또는 메서드에서 어떻게 처리될지 정의한다.(@Transactional)
- propagation 속성을 통해 트랜잭션의 동작 방식을 제어할 수 있다.
- 다양한 비즈니스 요구 사항에 맞춰 복잡한 트랜잭션 흐름을 유연하게 설계할 수 있도록 돕는다.
- 데이터 무결성과 비지니스 로직의 안정성을 보장할 수 있다.
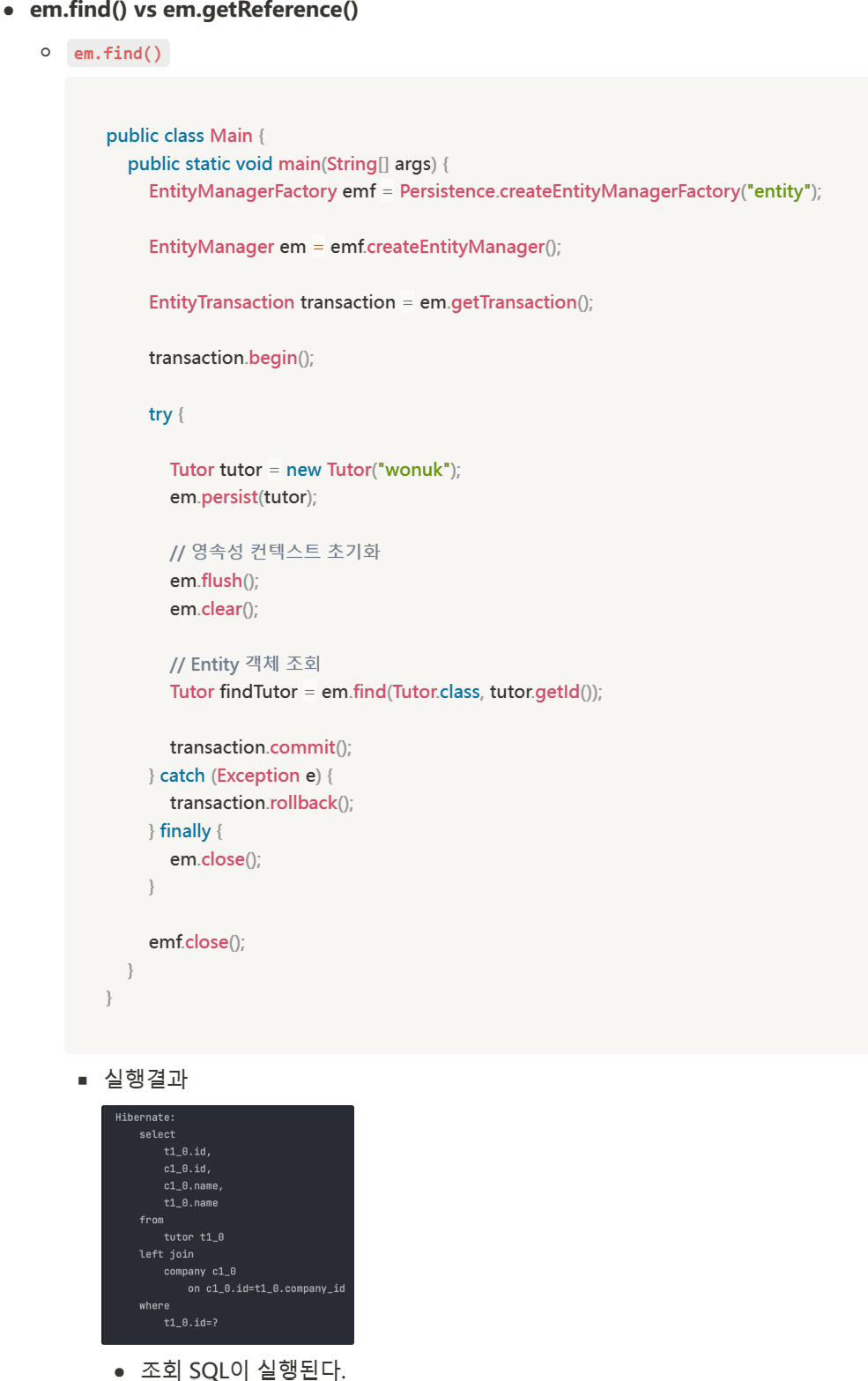
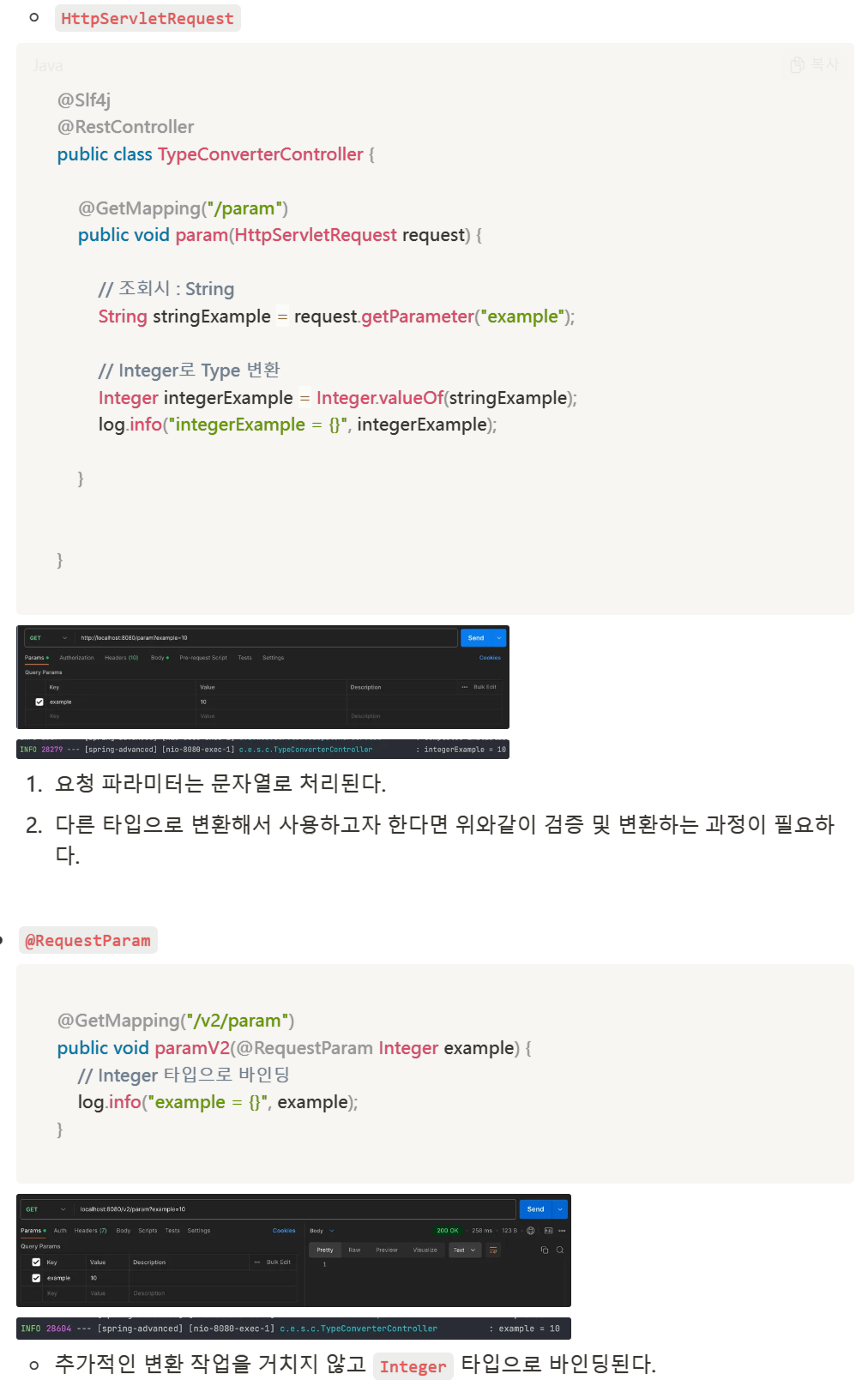
- 코드 예시
- REQUIRED(Default) 사용
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
public void addPoints(Long memberId, int points) {
// 포인트 지급 로직
pointRepository.save(new Point(memberId, points));
}
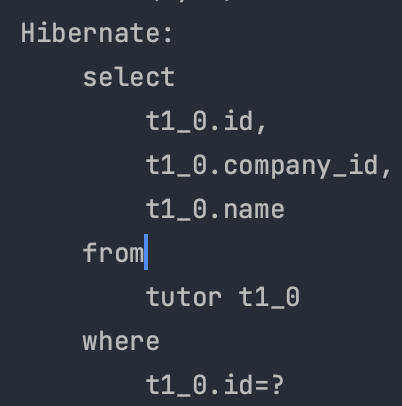
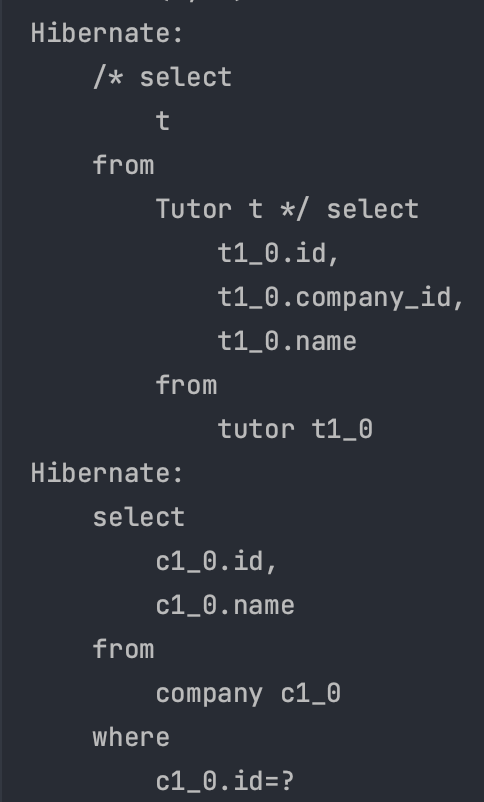
}- signUp() 메서드에 @Transactional 을 통해 트랜잭션 설정
- 하위 addPoints() 메서드에 트랜잭션이 전파된다.
- 하위 메서드가 실패하면 롤백된다.
- 포인트 지급 로직에서 문제가 발생해도 회원 등록은 롤백된다.
- 트랜잭션 동작

- 트랜잭션 전파 종류
- propagation 속성
- REQUIRED(Default)
- 기존 트랜잭션이 있다면 기존 트랜잭션을 사용한다.
- 기존 트랜잭션이 없다면 트랜잭션을 새로 생성한다.
- REQUIRES_NEW
- 항상 새로운 트랜잭션을 시작하고, 기존의 트랜잭션은 보류한다.
- 두 트랜잭션은 독립적으로 동작한다.
- SUPPORTS
- 기존 트랜잭션이 있으면 해당 트랜잭션을 사용한다.
- 기존 트랜잭션이 없으면 트랜잭션 없이 실행한다.
- NOT_SUPPORTED
- 기존 트랜잭션이 있어도 트랜잭션을 중단하고 트랜잭션 없이 실행된다.
- MANDATORY
- 기존 트랜잭션이 반드시 있어야한다.
- 트랜잭션이 없으면 실행하지 않고 예외를 발생시킨다.
- NEVER
- 트랜잭션 없이 실행되어야 한다.
- 트랜잭션이 있으면 예외를 발생시킨다.
- NESTED
- 현재 트랜잭션 내에서 중첩 트랜잭션을 생성한다.
- 중첩 트랜잭션은 독립적으로 롤백할 수 있다.
- 기존 트랜잭션이 Commit되면 중첩 트랜잭션도 Commit 된다.
- REQUIRED(Default)
- propagation 속성
- REQUIRES_NEW
- 회원 가입과 동시에 회원에게 포인트를 지급해야 하는 경우
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addPoints(Long memberId, int points) {
// 포인트 지급 로직
pointRepository.save(new Point(memberId, points));
}
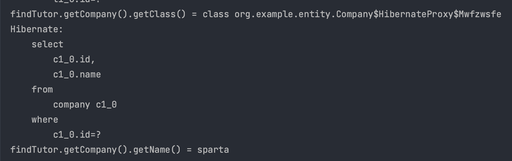
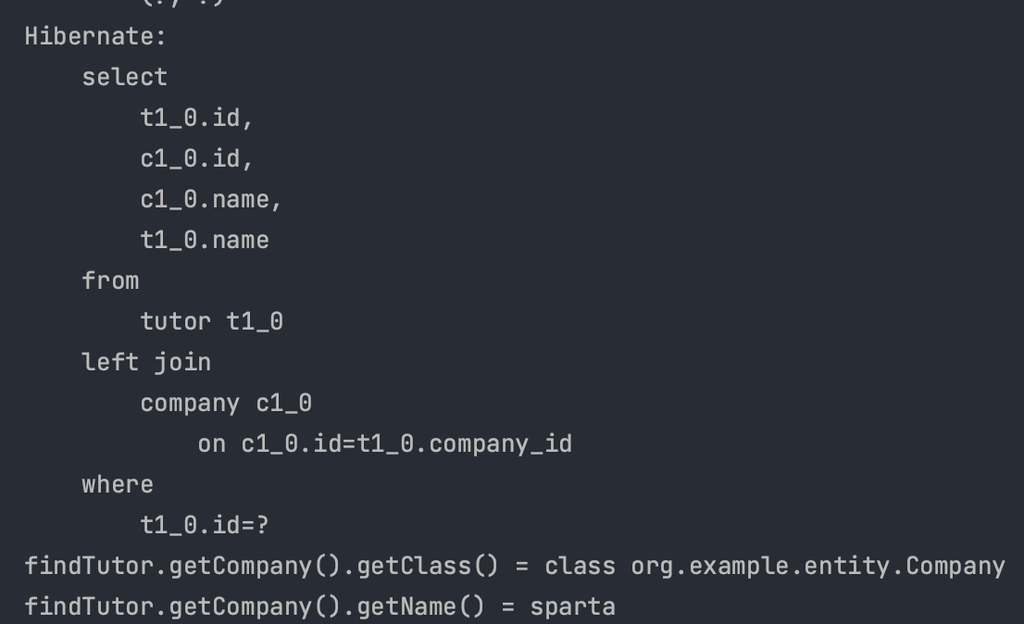
}- 요구사항 : 포인트 지급에 **실패**해도 회원가입은 완료되어야 한다.
- REQUIRES_NEW 설정(독립적인 트랜잭션 유지)
- 포인트 지급 로직에서 문제가 발생해도 회원 등록은 롤백되지 않는다.
- 트랜잭션 동작

트랜잭션
**트랜잭션(Transaction)**은 데이터베이스에서 작업의 논리적인 단위를 의미합니다. 트랜잭션은 하나의 작업 단위를 구성하며, 이 단위가 완전히 성공하거나 실패해야 데이터의 무결성을 보장합니다.
트랜잭션의 특징 (ACID 속성)
- 원자성 (Atomicity):
- 트랜잭션 내의 모든 작업이 모두 성공하거나 모두 실패해야 합니다.
- 일부 작업만 실행되고 나머지가 실패하면, 전체 작업을 취소(롤백)하여 데이터 일관성을 유지합니다.
- 일관성 (Consistency):
- 트랜잭션이 성공적으로 완료되면, 데이터베이스가 항상 일관성 있는 상태로 유지됩니다.
- 예: 은행 송금 시, 한 계좌에서 돈을 빼면 다른 계좌에 같은 금액이 추가되어야 함.
- 고립성 (Isolation):
- 여러 트랜잭션이 동시에 실행될 경우, 각 트랜잭션은 서로 독립적으로 실행되어야 합니다.
- 한 트랜잭션의 중간 결과가 다른 트랜잭션에 노출되지 않음.
- 지속성 (Durability):
- 트랜잭션이 커밋된 후에는 영구적으로 데이터베이스에 반영되어야 합니다.
- 서버가 중단되거나 시스템 장애가 발생해도 데이터는 손실되지 않습니다.
트랜잭션의 상태
- 활성 (Active):
- 트랜잭션이 시작되고 작업이 진행 중인 상태.
- 부분 완료 (Partially Committed):
- 트랜잭션의 마지막 명령이 실행되었지만, 아직 커밋되지 않은 상태.
- 완료 (Committed):
- 트랜잭션이 성공적으로 완료되어 데이터베이스에 반영된 상태.
- 실패 (Failed):
- 트랜잭션이 오류로 인해 중단된 상태.
- 철회 (Aborted):
- 트랜잭션이 실패하거나 취소되어 롤백된 상태.
트랜잭션의 처리 과정
- 트랜잭션 시작:
- 트랜잭션을 시작하여 작업 단위를 정의.
- 작업 실행:
- 트랜잭션 내에서 여러 데이터베이스 작업(쿼리, 삽입, 업데이트, 삭제 등)을 실행.
- 커밋 또는 롤백:
- 모든 작업이 성공하면 커밋하여 데이터베이스에 변경 사항을 반영.
- 작업 중 오류가 발생하면 롤백하여 변경 사항을 취소.
Spring에서의 트랜잭션 관리
Spring은 프록시 기반 AOP를 사용하여 트랜잭션 관리를 제공합니다. Spring의 트랜잭션 관리 기능은 선언적 방식과 프로그래밍 방식으로 사용 가능합니다.
1. 선언적 트랜잭션 관리
Spring에서는 @Transactional 어노테이션을 사용하여 선언적으로 트랜잭션을 관리할 수 있습니다.
@Service
public class UserService {
@Transactional
public void createUser(User user) {
userRepository.save(user);
emailService.sendWelcomeEmail(user); // 예외 발생 시 전체 롤백
}
}
- @Transactional이 붙은 메서드는 트랜잭션이 시작되고, 예외 발생 시 롤백됩니다.
- 커밋은 메서드 실행이 성공적으로 종료되면 수행됩니다.
2. 프로그래밍 방식 트랜잭션 관리
프로그래밍 방식으로 PlatformTransactionManager를 사용하여 트랜잭션을 직접 관리할 수 있습니다.
@Service
public class UserService {
@Autowired
private PlatformTransactionManager transactionManager;
public void createUser(User user) {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
userRepository.save(user);
emailService.sendWelcomeEmail(user);
transactionManager.commit(status); // 성공 시 커밋
} catch (Exception e) {
transactionManager.rollback(status); // 실패 시 롤백
}
}
}
트랜잭션 전파 수준 (Propagation)
트랜잭션 전파(Propagation)는 트랜잭션이 다른 메서드 호출 시 어떻게 동작할지 정의합니다.
전파 속성 설명
| REQUIRED | 기본값. 기존 트랜잭션이 있으면 참여하고, 없으면 새 트랜잭션 생성. |
| REQUIRES_NEW | 항상 새 트랜잭션을 생성. 기존 트랜잭션은 일시 중단. |
| NESTED | 중첩 트랜잭션을 생성. 롤백은 부모 트랜잭션과 독립적. |
| MANDATORY | 기존 트랜잭션이 없으면 예외 발생. |
| SUPPORTS | 트랜잭션이 있으면 참여, 없으면 트랜잭션 없이 실행. |
| NOT_SUPPORTED | 항상 트랜잭션 없이 실행. 기존 트랜잭션은 일시 중단. |
| NEVER | 트랜잭션 없이 실행하며, 기존 트랜잭션이 있으면 예외 발생. |
트랜잭션 격리 수준 (Isolation)
트랜잭션 격리 수준은 동시에 실행되는 트랜잭션 간의 상호작용을 제어합니다.
격리 수준 설명
| DEFAULT | 데이터베이스의 기본 격리 수준을 따름. |
| READ_UNCOMMITTED | 다른 트랜잭션이 커밋하지 않은 데이터도 읽을 수 있음. (Dirty Read 가능) |
| READ_COMMITTED | 다른 트랜잭션이 커밋한 데이터만 읽을 수 있음. |
| REPEATABLE_READ | 같은 트랜잭션 내에서 동일 데이터를 반복적으로 읽어도 동일한 결과를 보장. |
| SERIALIZABLE | 가장 높은 격리 수준. 트랜잭션을 순차적으로 실행하여 충돌 방지. |
트랜잭션 롤백 조건
Spring의 @Transactional은 기본적으로 런타임 예외가 발생할 때 롤백합니다.
롤백 예외 설정
@Transactional(rollbackFor = Exception.class)
public void process() {
// Exception 발생 시 롤백
}
롤백 제외 설정
@Transactional(noRollbackFor = CustomException.class)
public void process() {
// CustomException 발생 시 롤백하지 않음
}
트랜잭션의 장점
- 데이터 무결성 보장:
- 작업 도중 오류가 발생해도 데이터 손상 방지.
- 동시성 제어:
- 여러 사용자가 동시에 데이터베이스에 접근해도 데이터 충돌 방지.
- 복잡한 작업 관리:
- 여러 작업 단위를 하나의 트랜잭션으로 묶어 관리 가능.
- 자동화된 관리:
- Spring의 트랜잭션 관리를 통해 선언적으로 간단하게 설정 가능.
정리
**트랜잭션(Transaction)**은 하나의 논리적인 작업 단위를 정의하며, 데이터베이스의 무결성과 일관성을 보장합니다. Spring은 선언적 트랜잭션(@Transactional)을 제공하여 개발자가 쉽게 트랜잭션을 관리할 수 있도록 돕습니다.
핵심 개념:
- ACID 속성: 원자성, 일관성, 고립성, 지속성.
- Spring의 지원: 선언적(@Transactional), 프로그래밍 방식.
- 전파와 격리 수준: 트랜잭션의 실행 방식을 제어.
'DB > JPA ( Java Persistence API )' 카테고리의 다른 글
| [JPA] 쿼리 파일 만들기 (QueryMapper) (0) | 2025.01.26 |
|---|---|
| [JPA] 데이터베이스 연결 (Driver) (1) | 2025.01.25 |
| [JPA] 지연로딩, 즉시로딩 (0) | 2025.01.15 |
| [JPA] Proxy (0) | 2025.01.14 |
| [JPA] 상속관계 매핑 (0) | 2025.01.13 |