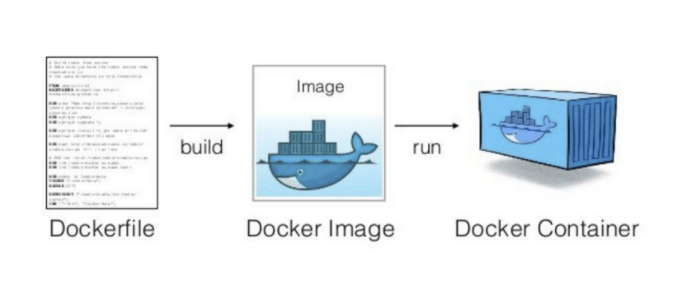
Dockerfile
📌 Dockerfile은 컴퓨터에서 돌아가는 앱을 만들기 위한 레시피라고 보면 된다. 이 레시피대로 하면 Docker 이미지라는 걸 만들 수 있다. Docker 이미지는 앱을 실행하는 데 필요한 모든 것을 담고 있다.
Dockerfile을 사용하는 이유
1. 환경 일관성
- 문제: 애플리케이션은 다양한 환경(OS, 라이브러리 버전, 설정)에 따라 다르게 동작할 수 있습니다.
- Dockerfile의 역할:
- Dockerfile을 통해 운영체제, 소프트웨어 버전, 라이브러리 등을 명시적으로 정의.
- 개발, 테스트, 운영 환경에서 동일한 컨테이너 이미지를 사용하므로 환경 차이로 인한 문제를 방지.
- "개발 환경에서 잘 동작하는데 프로덕션에서는 오류가 발생하는 문제"를 해소.
2. 자동화된 이미지 생성
- 문제: 매번 애플리케이션을 설치하거나 빌드하는 과정을 수동으로 처리하면 시간이 낭비되고 오류가 발생할 수 있습니다.
- Dockerfile의 역할:
- Dockerfile은 애플리케이션 빌드 및 설치 과정을 자동화.
- docker build 명령어로 간단히 이미지를 생성할 수 있음.
- 변경 사항이 생길 경우 Dockerfile만 업데이트하여 쉽게 새로운 이미지를 생성 가능.
3. 이식성(Portability)
- 문제: 다른 플랫폼(OS)에서 애플리케이션을 배포하려면 추가 설정과 조정이 필요할 수 있습니다.
- Dockerfile의 역할:
- Docker 이미지는 한 번 생성하면 어떤 환경에서든 동일하게 동작.
- 컨테이너를 실행할 수 있는 곳이라면(로컬, 클라우드, 서버 등) 어디서나 배포 가능.
- 운영 환경에 상관없이 안정적인 배포 보장.
4. 확장성과 모듈화
- 문제: 복잡한 시스템은 여러 애플리케이션이나 서비스가 상호작용하며 구성됩니다.
- Dockerfile의 역할:
- Dockerfile을 사용해 애플리케이션별 컨테이너를 생성하고, 이를 조합하여 마이크로서비스 아키텍처를 구현.
- 각 서비스는 독립적으로 배포, 확장 가능.
5. 버전 관리 및 재현성
- 문제: 애플리케이션 업데이트나 변경이 과거 버전과 충돌하거나 재현이 어려울 수 있음.
- Dockerfile의 역할:
- Dockerfile 자체를 소스 코드와 함께 버전 관리(Git 등)할 수 있음.
- 특정 시점의 Dockerfile로 언제든지 동일한 이미지를 재생성 가능.
6. 배포 자동화(CI/CD와 통합)
- 문제: 애플리케이션 배포 과정을 수동으로 처리하면 효율성이 떨어지고 오류가 발생할 수 있음.
- Dockerfile의 역할:
- CI/CD 파이프라인에서 Dockerfile을 사용해 자동으로 이미지를 생성하고 테스트, 배포 가능.
- GitHub Actions, Jenkins, GitLab CI/CD 등과 쉽게 통합 가능.
7. 리소스 격리
- 문제: 하나의 서버에서 여러 애플리케이션을 실행하면 서로 충돌할 가능성이 있음.
- Dockerfile의 역할:
- 컨테이너화된 애플리케이션은 호스트와 격리된 상태로 실행.
- 리소스(CPU, 메모리, 네트워크)를 독립적으로 관리 가능.
8. 경량성
- 문제: VM(가상 머신)은 운영체제와 함께 많은 리소스를 소모.
- Dockerfile의 역할:
- 컨테이너는 운영체제를 포함하지 않으므로 VM에 비해 가볍고 빠름.
- Dockerfile로 필요한 최소 구성만 정의해 경량화된 이미지를 생성.
요약: Dockerfile 사용하는 이유
| 이유 | 설명 |
| 환경 일관성 | 개발, 테스트, 운영 환경 간 차이를 없애 동일한 애플리케이션 동작 보장. |
| 자동화 | 애플리케이션 빌드 및 설정 과정을 자동화. |
| 이식성 | 어디서나 동일하게 실행 가능한 이미지를 제공. |
| 확장성 | 마이크로서비스 아키텍처 및 독립적인 서비스 확장을 지원. |
| 재현성 | 버전 관리를 통해 특정 시점의 동일 환경을 재생성 가능. |
| CI/CD 통합 | 자동화된 빌드와 배포를 지원하여 DevOps 환경에 최적화. |
| 격리 및 안전성 | 컨테이너 간 리소스 격리로 안정성 향상. |
| 경량성 | VM보다 적은 리소스 사용으로 효율적. |
Dockerfile 사용법
Dockerfile 예제
# Dockerfile
FROM ubuntu:latest # 베이스 이미지를 Ubuntu 최신 버전으로 설정
MAINTAINER Your Name <your-email@example.com> # 이미지 제작자 정보
# 필요한 패키지 업데이트 및 Nginx 설치
RUN apt-get update && apt-get install -y nginx
# index.html 파일을 Nginx의 기본 HTML 디렉토리로 복사
COPY index.html /usr/share/nginx/html
# 컨테이너가 노출할 포트를 설정
EXPOSE 80
# 컨테이너 실행 시 Nginx를 실행하고 데몬 모드를 비활성화
CMD ["nginx", "-g", "daemon off;"]
Dockerfile 명령어 설명
| 명령어 | 설명 |
| FROM | 베이스 이미지를 설정 (컨테이너의 기반 OS 또는 환경). |
| MAINTAINER | 이미지를 제작한 사람의 이름과 이메일 주소를 설정. |
| RUN | 컨테이너 이미지를 빌드할 때 실행할 명령어 (예: 패키지 설치). |
| COPY | 로컬 파일을 컨테이너 이미지로 복사. |
| EXPOSE | 컨테이너가 외부에 노출할 포트를 지정. |
| CMD | 컨테이너가 실행될 때 기본으로 실행할 명령어를 설정. |
Docker 이미지 생성 명령어
- Docker 이미지를 생성하는 명령:
docker buildx build -t my-nginx:latest .- -t: 이미지에 태그를 설정 (예: my-nginx:latest).
- .: 현재 디렉토리에서 Dockerfile을 찾음.
- buildx: 빌드 실행 도구. 일반적인 빌드 명령은 docker build를 사용.
Docker 컨테이너 실행 명령어
- 컨테이너 실행 명령:
docker run -d -p 80:80 my-nginx:latest- -d: 컨테이너를 백그라운드에서 실행.
- -p 80:80: 호스트의 80번 포트를 컨테이너의 80번 포트에 매핑.
- my-nginx:latest: 생성한 Docker 이미지를 기반으로 컨테이너 실행.
Docker 컨테이너 관리
- 컨테이너 종료:
- my-nginx: 실행 중인 컨테이너 이름 또는 ID.
- docker stop my-nginx
- 컨테이너 재시작:
- docker start my-nginx
- 실행 중인 컨테이너 확인:
- docker ps
- 중지된 컨테이너 포함 확인:
- docker ps -a
Docker 이미지 공유
- Docker 레지스트리:
- Docker 이미지를 공유하고 저장하는 서비스.
- 예: Docker Hub, AWS ECR, Google Container Registry 등.
- 이미지 업로드 명령:
- username/my-nginx:latest: Docker Hub에 업로드할 이미지 이름.
- Docker Hub에 업로드하려면 먼저 docker login으로 인증 필요.
- docker push username/my-nginx:latest
- 이미지 다운로드 명령:
- 공유된 이미지를 다른 사용자나 서버에서 다운로드하여 사용.
- docker pull username/my-nginx:latest
정리된 작업 흐름
- Dockerfile 작성:
- 애플리케이션과 설정을 정의.
- 이미지 생성:
- docker build 명령으로 이미지를 생성.
- 컨테이너 실행:
- docker run 명령으로 컨테이너 실행.
- 컨테이너 관리:
- 컨테이너를 start, stop, restart 명령으로 제어.
- 이미지 공유:
- Docker Hub 등 레지스트리에 이미지를 업로드하여 협업 또는 배포.

Dockerfile 명령어
| 명령어 | 설명 | 예제 |
| FROM | 베이스 이미지를 지정. Dockerfile은 항상 FROM으로 시작. | FROM ubuntu:22.04 |
| MAINTAINER | Dockerfile 작성자 정보 (이제는 LABEL 사용 권장). | MAINTAINER naebaecaem <nbcamp@spartacoding.co> |
| LABEL | 이미지에 메타데이터 추가. | LABEL purpose='nginx test' |
| RUN | 이미지를 생성하는 동안 실행할 명령어. root 권한으로 실행. | RUN apt update && apt upgrade -y |
| CMD | 컨테이너 생성 시 실행할 명령어. 컨테이너 시작 시 한 번만 실행. | CMD ["nginx", "-g", "daemon off;"] |
| ENTRYPOINT | 컨테이너 시작 시 무조건 실행할 명령어. 추가 명령어와 결합 가능. | ENTRYPOINT ["npm", "start"] |
| ENV | 환경 변수를 설정. | ENV STAGE stagingENV JAVA_HOME /usr/lib/jvm/java-8-oracle |
| WORKDIR | 작업 디렉토리를 설정. | WORKDIR /app |
| COPY | 호스트의 파일/디렉토리를 컨테이너에 복사. Docker Context 내의 파일만 가능. | COPY index.html /usr/share/nginx/html |
| USER | 컨테이너 내에서 사용할 기본 사용자를 설정. | USER userRUN ["useradd", "user"] |
| EXPOSE | 컨테이너에서 노출할 포트를 설정. | EXPOSE 80 |
| ARG | 빌드 시점에 전달할 변수를 설정. ENV와 달리 빌드 후에는 사라짐. | ARG STAGERUN sh -c 'echo "STAGE=$STAGE" > .env' |
Dockerfile 예제 1: FastAPI 앱 실행
# Python 3.11 베이스 이미지 사용
FROM python:3.11
# pipenv 설치
RUN pip install pipenv
# 작업 디렉토리 설정
WORKDIR /app
# 로컬 파일을 컨테이너로 복사
ADD . /app/
# pipenv 환경 설정
RUN pipenv --python 3.11
RUN pipenv run pip install poetry
RUN pipenv sync
RUN pipenv run pip install certifi
# 빌드 시 입력 가능한 변수 설정
ARG STAGE
RUN sh -c 'echo "STAGE=$STAGE" > .env'
RUN sh -c 'echo "PYTHONPATH=." >> .env'
# 실행 스크립트에 실행 권한 부여
RUN chmod +x ./scripts/run.sh
RUN chmod +x ./scripts/run-worker.sh
# 컨테이너 시작 시 실행할 명령어 설정
CMD ["./scripts/run.sh"]
Dockerfile 예제 2: Nginx 웹 서버
Dockerfile
# Ubuntu 22.04 베이스 이미지 사용
FROM ubuntu:22.04
# 작성자 정보
MAINTAINER your-name <your-email@example.com>
# 이미지 메타데이터 추가
LABEL purpose=Web Server
# Nginx 설치
RUN apt-get update && apt-get install -y nginx
# Nginx 설정 파일 복사
COPY nginx.conf /etc/nginx/nginx.conf
# 컨테이너 실행 시 Nginx 시작
CMD ["nginx", "-g", "daemon off;"]
Nginx 설정 파일 (nginx.conf):
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
gzip on;
gzip_disable "msie6";
include /etc/nginx/conf.d/*.conf;
}
'Docker > Docker' 카테고리의 다른 글
| [Docker] Docker 모니터링&로깅 (0) | 2025.02.04 |
|---|---|
| [Docker] Docker Compose (0) | 2025.02.03 |
| [CI/CD] Github Actions CI (0) | 2025.01.31 |
| [Docker] Docker+CI/CD (0) | 2025.01.30 |
| [Docker] Docker 기초 (0) | 2025.01.29 |