📌 프레임워크는 특정 프로그래밍 작업을 수행하기 위한 기반 구조를 제공하는 도구입니다. 예를 들어, 웹 애플리케이션 개발을 위한 Spring이나 Django와 같은 프레임워크는 애플리케이션 아키텍처와 구조를 정의하고, 개발자가 해당 구조 내에서 작업할 수 있도록 도와줍니다.
프레임워크는 frame(틀) work(일하다)의 합성어로 일하기 위한 틀을 제공한다. 개발자는 해당 틀에서 일을 해야 한다.
라이브러리가 도화지라면 프레임워크는 채색북과 같다.둘다 그림을 완성시키는 도구이지만, 도화지는 완전히 자유로운 디자인을 할 수 있고 채색북은 자유롭지는 못하지만 편하게 그림을 완성시킬 수 있다.
[1] 프레임워크의 주요 특징:
구조 제공: 프레임워크는 애플리케이션 개발의 기본 뼈대를 제공합니다. 예를 들어, 어떤 파일을 어디에 두고, 어떻게 코드를 구성할지에 대한 규칙을 제시합니다.
규칙과 흐름: 프레임워크는 개발자가 따를 일정한 흐름을 정의합니다. 즉, 개발자가 애플리케이션을 어떻게 구조화할지에 대한 가이드라인을 제공합니다.
확장성: 프레임워크는 애플리케이션을 개발하는 데 있어 기능을 추가하거나 수정할 수 있는 방법을 제공합니다. 그러나 기본적으로는 프레임워크 내에서 정해진 규칙을 따라야 합니다.
재사용성: 프레임워크는 많은 기능을 미리 구현해두어, 개발자는 이러한 기능을 재사용할 수 있습니다. 예를 들어, 데이터베이스 연결, 보안 관리, 사용자 인증 등이 미리 구현되어 있는 경우가 많습니다.
[2] 프레임워크의 예시:
웹 개발 프레임워크:
Spring Framework (Java): 웹 애플리케이션을 만들 때 필요한 기본 구조와 규칙을 제공합니다. Spring은 의존성 주입, AOP, 보안, 데이터베이스 연동 등 여러 기능을 제공합니다.
Django (Python): Python으로 웹 애플리케이션을 개발할 때 사용하는 프레임워크로, 기본적인 웹 애플리케이션의 구조와 URL 처리, 데이터베이스 연동 등의 기능을 제공합니다.
Ruby on Rails (Ruby): Ruby 언어로 웹 애플리케이션을 빠르게 개발할 수 있도록 도와주는 프레임워크입니다. RESTful 방식의 API 설계와 모델-뷰-컨트롤러(MVC) 아키텍처를 따릅니다.
모바일 앱 개발 프레임워크:
React Native: JavaScript를 사용하여 iOS와 Android에서 실행되는 네이티브 앱을 개발할 수 있게 해주는 프레임워크입니다.
Flutter: Google에서 만든 프레임워크로, Dart 언어를 사용해 크로스 플랫폼 애플리케이션을 개발할 수 있습니다.
[3] 장점
개발 프로젝트에 일관된 구조를 제공하여 코드의 일관성과 가독성을 높여주며 팀 협업이 편해진다.
기본적으로 필요한 기능과 도구를 제공하여 개발자들이 핵심 비즈니스 로직에 집중할 수 있다.
보안 관련 기능을 기본적으로 제공하여, 보안 취약점을 방지하는 데 도움을 준다.
통합된 테스트 환경과 도구를 제공하여 테스트를 쉽게 작성하고 실행할 수 있다.
인기 있는 프레임워크는 방대한 커뮤니티 지원을 받으며, 다양한 문서를 활용할 수 있다.
[4] 단점
프레임워크는 굉장히 복잡한 구조를 가지기 때문에, 처음 익히는 데 시간이 많이 소요된다.
프레임워크의 새로운 버전이 기존 코드와 호환되지 않을 수 있다.
정해진 규칙과 구조를 따르게 강제하여 자유롭게 변경하기 어려울 수 있다.
Library
📌 특정 기능을 수행하는 코드의 모음으로, 개발자가 필요할 때 그 기능을 호출하여 사용할 수 있는 도구입니다. 라이브러리는 애플리케이션의 흐름을 제어하지 않으며, 개발자가 원하는 기능만 골라서 사용할 수 있습니다. 즉, 라이브러리는 필요한 도구를 제공하지만, 애플리케이션의 전체적인 흐름은 개발자가 주도합니다.
[1] 라이브러리의 주요 특징:
선택적 사용: 라이브러리는 개발자가 필요한 기능을 원할 때 호출해서 사용할 수 있습니다. 개발자가 전체적인 흐름을 제어하고, 필요한 기능만 사용할 수 있습니다.
재사용성: 특정 기능을 여러 번 사용할 수 있도록 기능을 모듈화하여 제공합니다. 예를 들어, 수학 계산, 문자열 처리, HTTP 요청 보내기 등의 기능을 쉽게 사용할 수 있습니다.
독립적: 라이브러리는 보통 독립적으로 동작하며, 다른 라이브러리나 애플리케이션에 종속되지 않습니다.
[2] 라이브러리의 예시:
JavaScript 라이브러리:
jQuery: HTML 문서를 다루고, 이벤트를 처리하며, AJAX 요청을 보내는 등의 기능을 쉽게 사용할 수 있도록 도와주는 JavaScript 라이브러리입니다. jQuery를 사용하면 DOM 조작을 더 간단히 할 수 있습니다.
Lodash: 배열, 객체, 함수 등의 데이터를 쉽게 다룰 수 있는 JavaScript 유틸리티 라이브러리입니다. 반복적인 코드 작성을 줄여주고, 다양한 유틸리티 함수들을 제공합니다.
Python 라이브러리:
NumPy: 수치 계산을 위한 Python 라이브러리로, 다차원 배열 및 행렬 연산을 지원하여 과학적 계산을 손쉽게 할 수 있습니다.
Pandas: 데이터를 다루고 분석하는 데 유용한 라이브러리로, 데이터 프레임(DataFrame) 구조를 사용하여 데이터 처리 및 분석을 쉽게 합니다.
Java 라이브러리:
Apache Commons: 다양한 유틸리티 기능을 제공하는 Java 라이브러리로, 문자열 처리, 파일 입출력 등 여러 가지 기능을 간편하게 사용할 수 있습니다.
Google Guava: Java에서 컬렉션, 캐시, 문자열 처리 등을 편리하게 처리할 수 있도록 돕는 라이브러리입니다.
[3] 라이브러리 사용의 장점:
빠른 개발: 이미 구현된 기능을 가져다 쓸 수 있어 개발 속도가 빨라집니다.
모듈화: 필요한 기능만 가져다 쓰므로 코드가 깔끔하고 모듈화가 잘 됩니다.
다양한 기능: 특정 작업을 처리하는 다양한 라이브러리가 존재하여, 원하는 기능을 쉽게 찾아 사용할 수 있습니다.
[4] 라이브러리 사용의 단점:
라이브러리가 업데이트 되거나 지원이 중단될 경우 문제가 발생할 수 있다.
버전 호환성 문제로 인해 다른 라이브러리나 기존 코드와 충돌이 발생할 수 있습니다.
생각보다 빈번하게 발생하는 문제
불필요한 기능을 포함한 라이브러리를 사용하면 비효율적이다.
라이브러리의 내부 구현을 직접 수정하기 어려워, 특정 요구 사항에 맞게 조정하기 힘들 수 있다.
라이브러리와 프레임워크의 차이점을 표로 정리하면 다음과 같습니다:
라이브러리
프레임워크
제어의 흐름
개발자가 흐름을 제어하고, 필요한 기능을 호출
프레임워크가 흐름을 제어하고, 개발자는 그 안에서 작업
사용 방식
필요한 기능을 선택하여 사용
전체적인 구조를 따르고, 규칙에 맞춰 작업
의존성
독립적이며, 필요할 때마다 호출하여 사용
애플리케이션 구조에 강하게 의존
구조 제공 여부
특정 기능을 제공하지만, 전체 구조는 제공하지 않음
전체적인 애플리케이션 구조를 제공
사용 예
특정 기능만 필요할 때 (예: jQuery, Lodash)
애플리케이션 개발 시 기본적인 구조가 필요한 경우 (예: Spring, Django)
개발자 역할
개발자가 원하는 기능을 필요에 맞게 선택하고 적용
개발자는 프레임워크의 규칙에 따라 작업
예시
jQuery, NumPy, Google Maps API
Spring, Django, Ruby on Rails
요약:
라이브러리는 개발자가 필요한 기능을 선택하여 사용하는 도구이고, 흐름 제어는 개발자에게 있습니다.
프레임워크는 애플리케이션의 구조와 흐름을 제공하며 라이브러리를 이미 포함하고 있습니다. 흐름 제어는 프레임워크가 담당합니다.
📌 웹 애플리케이션에서 클라이언트(브라우저)가 웹 페이지를 렌더링하는 방식입니다. 서버는 최소한의 HTML을 클라이언트에 전달하고, 이후 JavaScript가 클라이언트 측에서 실행되어 콘텐츠를 동적으로 렌더링하는 방식입니다.
HTML을 요청한다. 비어있는 HTML을 응답받는다. JS가 존재하는 주소 링크를 응답한다.
자바스크립트(클라이언트 로직, 렌더링 포함)를 요청한다.
HTTP API 요청을 하고 화면에 필요한 데이터를 JSON 형태(JSON이 아니어도됨)로 응답받는다.
응답받은 JSON 데이터로 HTML을 동적으로 그린다.
[1] CSR의 작동 원리
클라이언트 요청:
사용자가 웹 브라우저에서 특정 URL을 요청하면, 서버는 최소한의 HTML 파일을 클라이언트에 전달합니다. 이 HTML은 보통 페이지의 뼈대(구조)만 포함하고 있으며, 실제 콘텐츠는 포함되지 않습니다.
JavaScript 로드:
클라이언트가 받은 HTML은 주로 JavaScript 파일을 불러오는 역할을 합니다. JavaScript는 페이지를 동적으로 렌더링하는 데 필요한 데이터와 로직을 처리합니다.
API 호출:
JavaScript는 서버와 API 요청을 통해 데이터를 받아옵니다. 이 데이터는 JSON 형식으로 전달되며, JavaScript는 이 데이터를 바탕으로 페이지를 동적으로 생성합니다.
동적 렌더링:
받은 데이터를 바탕으로 JavaScript가 HTML을 동적으로 생성하여 화면에 표시합니다. 클라이언트에서 페이지 렌더링이 이루어지므로, 서버는 추가적인 렌더링 작업을 수행하지 않습니다.
인터랙티브한 페이지:
JavaScript는 페이지에서 사용자의 상호작용을 처리하며, 페이지 내에서 동적 콘텐츠 갱신이나 애니메이션 등을 실시간으로 구현합니다.
[2] CSR의 장점
서버 부하 감소:
클라이언트 측에서 렌더링을 처리하므로 서버 부하가 감소합니다. 서버는 페이지의 최소한의 HTML만 보내면 되며, 클라이언트에서 나머지 작업을 처리합니다.
빠른 사용자 경험:
초기 페이지 로딩 후, 페이지 내의 다른 콘텐츠를 동적으로 로드할 수 있습니다. 이는 사용자가 페이지 간 이동을 할 때 빠른 응답 시간을 제공합니다.
인터랙티브한 경험:
CSR은 JavaScript를 사용하여 동적이고 인터랙티브한 사용자 경험을 제공합니다. 버튼 클릭, 폼 제출 등의 인터랙션에 즉각적으로 반응할 수 있습니다.
클라이언트 측 상태 관리:
CSR에서는 클라이언트 측에서 애플리케이션의 상태를 관리할 수 있어, 페이지를 새로고침하지 않고도 실시간으로 UI 업데이트가 가능합니다.
애플리케이션 로딩 후 빠른 탐색:
한 번 페이지가 로드되면, 후속 페이지들은 빠르게 로드되고 전환됩니다. 이는 **SPA(Single Page Application)**에서 더욱 두드러지며, 페이지를 새로고침하지 않고도 새로운 콘텐츠를 동적으로 로드합니다.
[3] CSR의 단점
초기 로딩 속도:
CSR은 클라이언트에서 페이지를 렌더링하므로, 초기 페이지 로딩 시에 JavaScript 파일과 데이터를 모두 로드해야 합니다. 이로 인해 초기 로딩 속도가 상대적으로 느릴 수 있습니다.
SEO (검색 엔진 최적화):
CSR에서는 JavaScript로 동적으로 콘텐츠를 렌더링하므로, 검색 엔진 크롤러가 자바스크립트로 렌더링된 콘텐츠를 제대로 인식하지 못할 수 있습니다. 이는 SEO에 불리할 수 있습니다. 최근에는 **서버 사이드 렌더링(SSR)**과 결합하거나 프리렌더링을 통해 이 문제를 해결하기도 합니다.
자바스크립트 의존성:
CSR 방식은 JavaScript가 제대로 실행되지 않으면 페이지가 제대로 표시되지 않거나, 애플리케이션이 기능을 제대로 수행하지 않을 수 있습니다. 사용자가 JavaScript를 비활성화한 경우 페이지가 정상적으로 동작하지 않을 수 있습니다.
클라이언트 성능 문제:
클라이언트(브라우저)가 많은 작업을 처리하므로, 저사양 기기에서는 성능 저하가 발생할 수 있습니다. 특히, 복잡한 애플리케이션에서는 클라이언트가 느려질 수 있습니다.
📌 Servlet은 자바(Java) 언어로 작성된 서버 측 프로그램으로, 주로 웹 애플리케이션에서 클라이언트의 요청을 처리하고 동적으로 응답을 생성하는 데 사용됩니다.
JAVA에서 Sevlet은 HttpServlet 클래스를 상속받아 구현되며, Java EE (Enterprise Edition)**의 중요한 구성 요소로, 웹 서버나 웹 애플리케이션 서버에서 실행되며, HTTP 요청을 처리하는 동적 웹 애플리케이션을 만들 수 있게 해줍니다.
Servlet은 HTTP 프로토콜 기반 요청(Request) 및 응답(Response)을 처리하는데 사용된다.
[1] Servlet의 주요 기능
HTTP 요청 처리
클라이언트의 요청(GET, POST 등)을 받아들이고, 이를 처리하여 적절한 응답을 생성합니다.
웹 애플리케이션에서 사용자 요청에 따라 동적인 콘텐츠를 반환할 때 사용됩니다.
동적 콘텐츠 생성
사용자의 요청에 따라 데이터를 생성하거나 변경하고, 이를 동적으로 웹 페이지로 전달합니다.
예를 들어, 사용자 인증, 데이터베이스 질의 결과, 파일 처리 등을 동적으로 수행합니다.
세션 관리
웹 애플리케이션에서 클라이언트의 상태를 관리하는 데 도움을 줍니다.
클라이언트가 여러 페이지를 요청할 때, 같은 사용자로 인식하도록 세션을 관리합니다.
비즈니스 로직 처리
데이터베이스와의 상호작용이나 복잡한 계산을 수행하는 비즈니스 로직을 구현할 수 있습니다.
응답 처리
클라이언트에게 전달할 HTML, JSON, XML 등의 형식으로 응답을 생성합니다.
[2] Servlet의 작동 방식
클라이언트의 요청 클라이언트(보통 웹 브라우저)가 특정 URL을 요청합니다. 이 URL은 서버에 있는 Servlet을 호출합니다.
Servlet 컨테이너 처리 웹 서버 또는 애플리케이션 서버에서 Servlet 컨테이너가 요청을 받아 Servlet 클래스를 실행합니다. 이때, Servlet 컨테이너는 요청 정보를 HttpServletRequest 객체에 담아 Servlet으로 전달합니다.
비즈니스 로직 실행 Servlet은 요청을 처리하기 위해 필요한 비즈니스 로직을 실행합니다. 이 과정에서 데이터베이스와 연동하거나 데이터를 가공할 수 있습니다.
응답 생성 Servlet은 응답을 생성하여 클라이언트에게 반환합니다. 이는 HTML, JSON, XML 등 다양한 형식일 수 있습니다.
클라이언트에 응답 반환 생성된 응답은 HttpServletResponse 객체를 통해 클라이언트에게 전달됩니다.
@WebServlet("/hello")// 해당 URL에 매핑되는 ServletpublicclassHelloServletextendsHttpServlet{
protectedvoiddoGet(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {
// 응답 콘텐츠 타입 설정
response.setContentType("text/html");
// 클라이언트에 응답 전송
PrintWriter out = response.getWriter();
out.println("<h1>Hello, Servlet!</h1>");
}
}
위의 코드에서 HelloServlet은 /hello URL로 들어오는 GET 요청을 처리하며, 간단한 HTML 메시지를 반환하는 Servlet입니다
[5] Servlet과 JSP의 차이
구분
Servlet
JSP (Java Server Pages)
구성
Java 코드로 작성된 클래스
HTML 코드 내에 Java 코드를 삽입하는 형식
주요 용도
비즈니스 로직 처리, HTTP 요청/응답 관리
사용자 인터페이스(HTML) 작성 및 동적 콘텐츠 생성
장점
강력한 제어 흐름과 비즈니스 로직 구현 가능
HTML 기반으로 작성이 쉬우며, 동적 콘텐츠 생성에 유리
단점
HTML 생성 시 복잡한 Java 코드 필요
비즈니스 로직과 UI가 혼합되어 있어 코드 관리가 어려울 수 있음
[6] Servlet의 배달 비유
웹 서버는 배달원이 단순히 포장을 해서 전달하는 역할이라면,
Servlet은배달원이 주문에 맞게 음식을 준비하고 포장하여 고객에게 전달하는 역할입니다.
정적 콘텐츠를 제공하는 웹 서버와 달리, Servlet은 고객이 주문한 대로 동적으로 음식을 만들고 제공하는 역할을 합니다.
엄연히 WAS와는 다르다. 오히려 WAS에서 클라이언트 요청을 처리하고 응답을 생성하는 역활을 하는 자바 클래스이다. = WAS에서 사용되는 클래스이다
Servlet 동작 순서
1. WAS의 Servlet Container가 servlet 객체를 생성
2. 클라이언트가 해당 servlet을 사용하는 http 요청을 하면, Servlet Container에서 request,response 객체 생성
5. 응답 결과를 response 객체에 담은 후, Servlet Container에 전달
6. Servlet Container가 http 응답 메시지 생성 후 클라이언트에게 전달
서블릿은 로딩 시점에 생성될 수도 있고, 최초 요청 시점에서 생성될 수도 있다고 합니다. 그래서 요청시 서블릿 인스턴스가 메모리에 존재하지 않는다면 서블릿 컨테이너는 해당 서블릿을 로드하고init()메서드를 통해 초기화한 후, 적재한다고 합니다.
개발자가 하는 일
Request 객체에 담겨져있는 HTTP 요청 정보를 꺼내서 사용한다.
요청 정보(URL, Method, Message Body)를 통해 필요한 기능(비지니스 로직)을 수행한다.
생선된 Response 객체에 HTTP 응답 정보를 입력한다.
Servlet Container
📌 Servlet을 지원하는 WAS 내부에는서블릿 컨테이너가 있다. 서블릿 컨테이너는 서블릿을 초기화, 생성, 관리, 호출, 종료하는 역할을 수행한다.
Servlet 관리하고 jsp파일을 실행할 수 있게 해주는 것이 Servlet Container입니다.
Servlet의 생명주기
Servlet은 서블릿 컨테이너가 생성 및 관리한다.
WAS(서블릿 컨테이너 포함)가 종료될 때 Servlet도 함께 종료된다.
Servlet 객체 생성시점
개발자가 직접 인스턴스화 하여 사용하는것이 아닌, 코드만 작성하면 서블릿 컨테이너가 생성한다.
@WebServlet(name="ExampleServlet", urlPatterns = "/example")publicclassExampleServletextendsHttpServlet{ // HttpServlet을 상속받아 구현한다.@Overrideprotectedvoidservice(
HttpServletRequest request, // HTTP 요청 정보를 쉽게 사용할 수 있게 만드는 Servlet
HttpServletResponse response // HTTP 응답 정보를 쉽게 제공할 수 있게 만드는 Servlet
){
// application logic
}
}
@WebServlet(name="Example2Servlet", urlPatterns = "/example2")// 위와 같은 코드@WebServlet(name="Example3Servlet", urlPatterns = "/example3")// 위와 같은 코드@WebServlet(name="Example4Servlet", urlPatterns = "/example4")// 위와 같은 코드
Servlet Container가 하는 일
서블릿을 초기화, 생성, 관리, 호출, 종료하는 역할을 수행한다.
Servlet 객체를 싱글톤으로 관리한다.
동시 요청에 대한 처리를 위해 Multi Thread를 지원한다.
싱글톤은 객체를 하나만 생성하여 생성된 인스턴스를 공유하여 사용하는것을 의미합니다. 특정 클래스의 인스턴스가 여러개 생성되지 않도록 하여 자원의 낭비를 방지하고, 인스턴스를 공유함으로써 상태를 일관되게 유지하기 위함입니다. 하지만, 공유 변수 사용을 주의해야 합니다.
Thread
📌프로세스내에서 실행되는가벼운 작업 단위입니다.프로세스는 프로그램이 실행되는 환경을 의미하고,쓰레드는 프로세스 내에서 독립적으로 실행되는 코드의 흐름입니다. 여러 쓰레드는 하나의 프로세스 내에서 공유된 자원(메모리, 파일 등)을 사용하면서 동시에 실행될 수 있습니다.
애플리케이션 코드를 하나하나 순차적으로 실행하는 것, Java에서 main method를 실행하면 main이라는 이름을 가진 Thread가 실행되며 하나의 Thread는 한번에 하나의 코드 라인만 수행한다.
만약 동시 처리가 필요하다면 Thread를 추가적으로 생성 해야한다.
Servlet 객체의 호출
클라이언트에서 Request가 전달되면 Thread가 Servlet 객체를 호출한다.
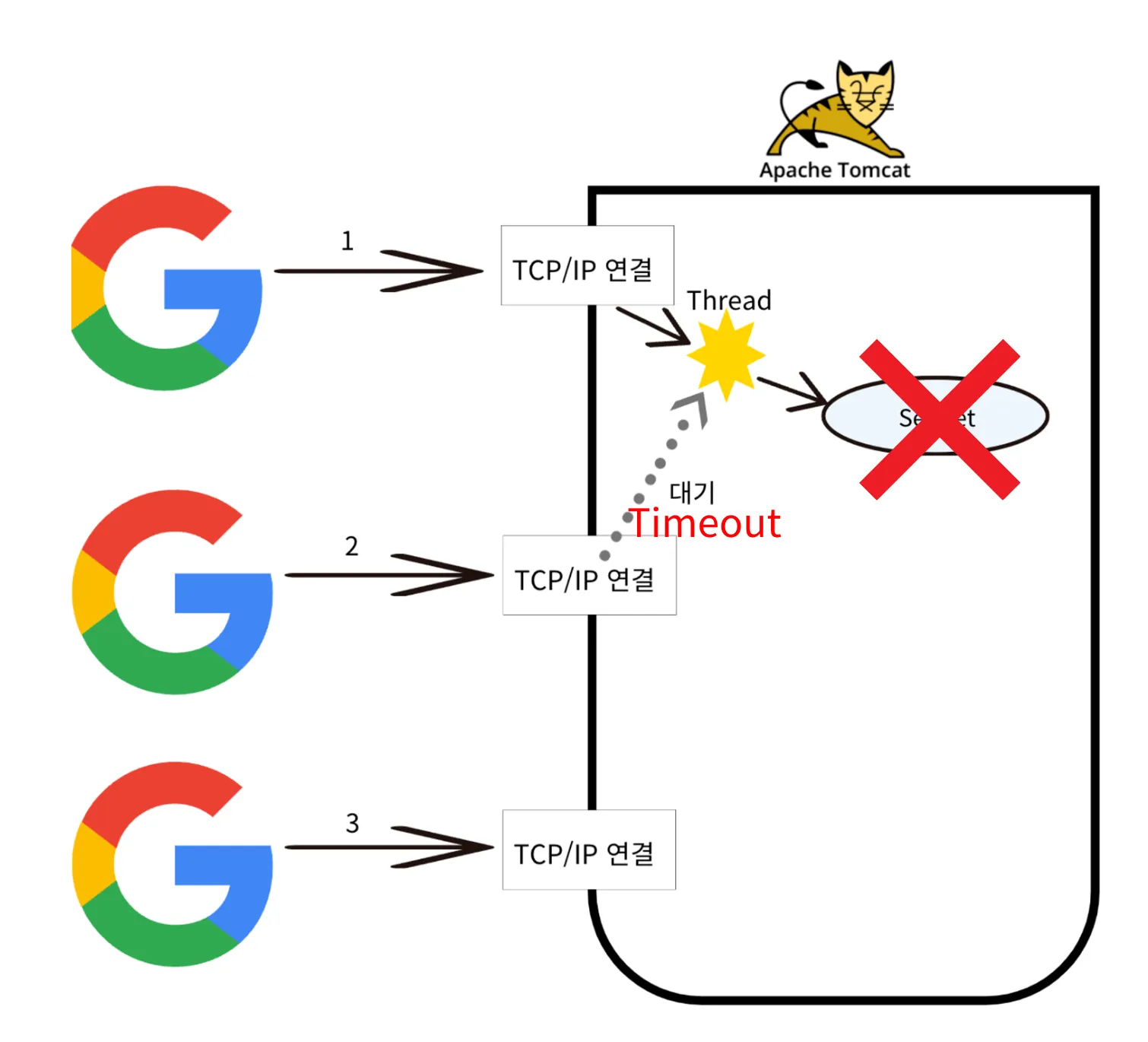
[1] 단일 요청 - Single Thread
클라이언트 요청 및 TCP/IP 연결
Thread 할당 후 Servlet 호출 ( Servlet도 쓰레드에 적재되어 실행하게 된다. 프로그램이 당연하지만)
멀티 쓰레드는 수행 속도가 빨라 동시에 처리하는 것 같지만 사실 엄청나게 짧은 시간 안에 수십, 수천 번 실행할 프로세스를 교체하고 있는 것이다.
장점
동시 요청을 처리할 수 있다.
하나의 Thread에 지연등의 문제가 발생하여도 나머지 Thread는 정상적으로 동작한다.
단점
Thread 생성에 제한이 없고 생성 비용이 높다.
수많은 동시 요청이 발생하면 리소스(Memory, CPU 등)부족으로 서버가 다운된다.
Thread를 사용하면 Context Switching 비용이 발생한다.
Context Switching
Task1에서 Task2로 Task2에서 Task1로 교체되는 시점마다 Task1이 Ready 상태로 돌아간다는 정보, 진행정보, Task2는 어디부터 작업을 시작하면 되는지에 대한 정보들을 로딩할 시간이 필요하게 된다. 이 순간의 시점이 바로 Context Switching이다.
적절한 패턴을 가지고 작성 되었지만 HTTP의 메소드 별로 서비스를 구분하여 사용하고 있지는 않다.
즉, 서비스 형태나 작업의 종류에 맞추어 적절한 HTTP 메소드를 지정하고 있지 않다.
사용자의 요청을 GET, POST로 대부분 처리하고 에러를 반환한다.
요청 예시(리소스에 대해 분리된 엔드포인트를 가진다)
POST /users
{
"name": "sparta",
"password": "codingclub"
}
Level2
우리가 제공하고자 하는 리소스를 적절하게 용도와 상태에 따라서 HTTP Methods에 맞게 설계하고 서비스하는 단계.
만약 리소스의 상태가 읽기 용도로 사용되는 데이터라고 한다면 GET Method를 사용한다.
새로운 리소스를 추가하는 경우는 POST Method
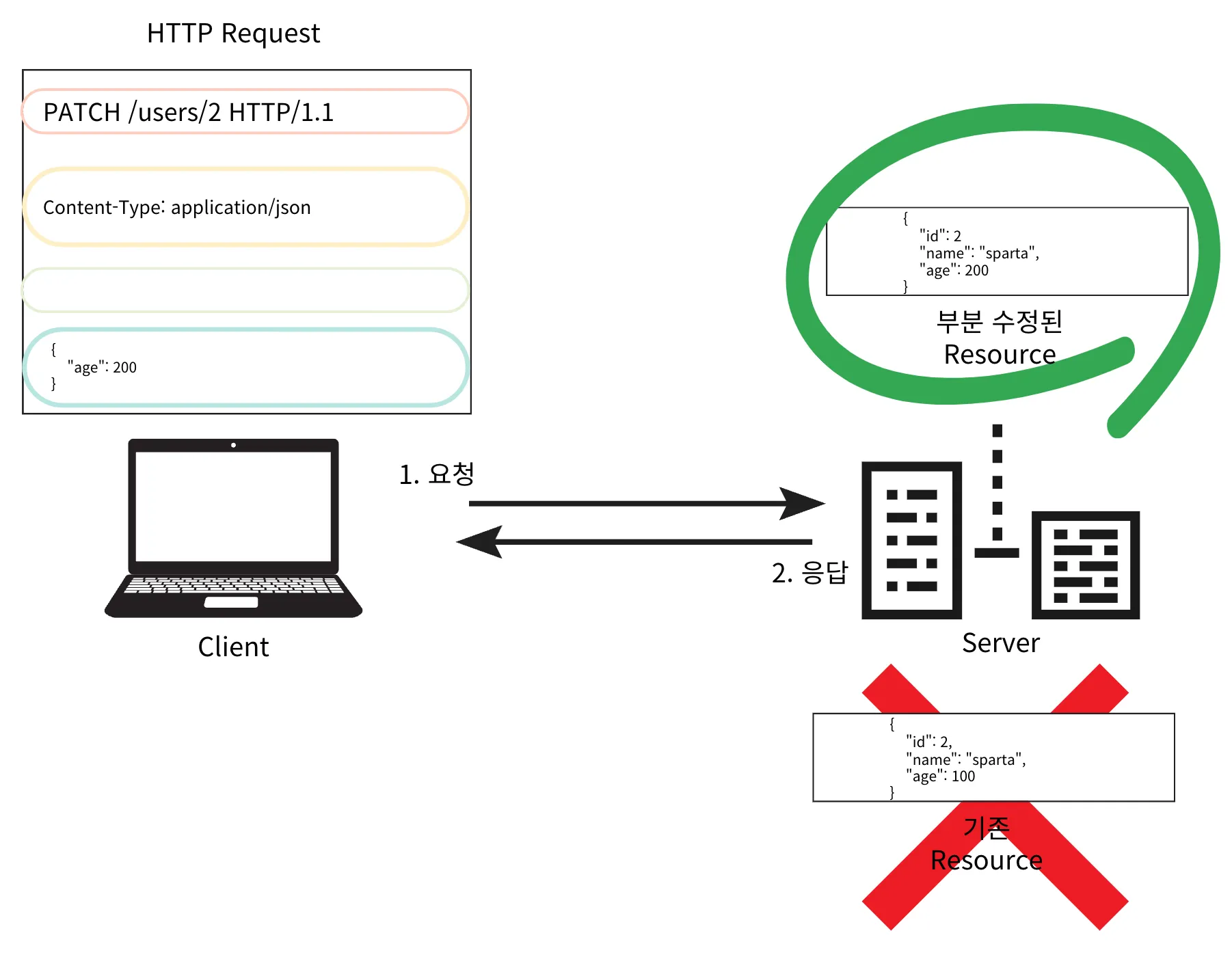
기존 리소스의 상태를 변경하기 위해서는 PUT, PATCH Method
리소스를 삭제하고자 할 때에는 Delete Method를 사용하여 서비스의 상태를 표현한다.
RESTful Service의 DB에 저장된 리소스를 확인하고 이러한 데이터를 조작하기 위해서 CRUD와 매칭되는 HTTP Methods를 이용하여 서비스 하는 것을 Level2 단계라고 한다.
HTTP의 메소드를 이용하여 리소스의 상태를 구분하여 서비스 하게 되면 비슷한 이름의 URI라 하더라도 HTTP Method에 따라서 다른 형태의 서비스를 제공할 수 있게 된다.
요청 예시(HTTP Method 활용)
GET /users/123// 특정 사용자 조회
POST /users // 사용자 생성
{
"name": "sparta",
"password": "codingclub"
}
PUT /users/123// 사용자 정보 수정
{
"name": "java",
"password": "spring"
}
DELETE /users/123// 사용자 삭제
Level3
데이터를 가지고 그 다음 작업에서 어떠한 작업을 할 수 있는지 상태 정보를 함께 넘겨준다.
클라이언트 측에서는 서버가 제공하는 서비스를 일일이 찾는 수고를 겪지 않아도 된다.
엔드포인트만 가지고 있으면 서버가 제공할 수 있는 다음, 그 다음 URI값을 알 수 있다.
요청 예시(응답 내에 링크를 포함한다)
💡HATEOAS(Hypermedia As The Engine Of Application State)회원 가입 후 회원 정보 수정은 어떻게 해야 하는지, 조회는 어떻게 해야 하는지 회원 조회를 하면서 그다음 단계로 진행할 수 있는 또 다른 리소스에 대한 정보는 어떠한 것이 있는지. 이러한 모든 정보를 같이 알려주는 기능을 HATEOAS라고 한다.
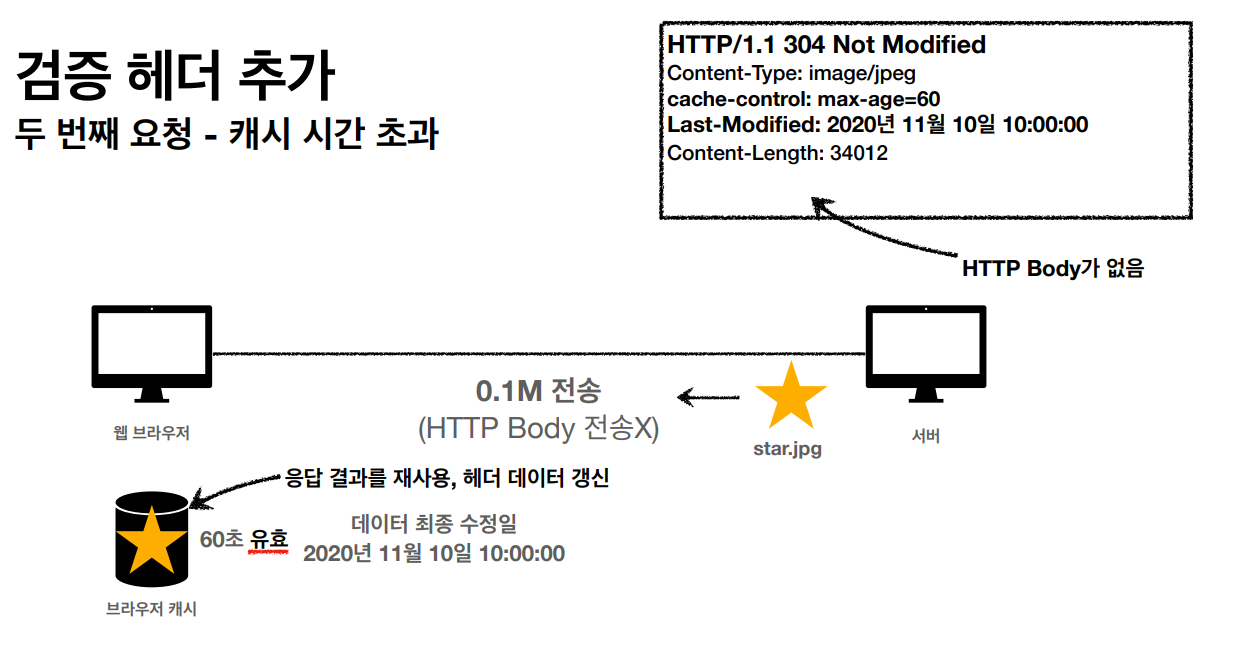
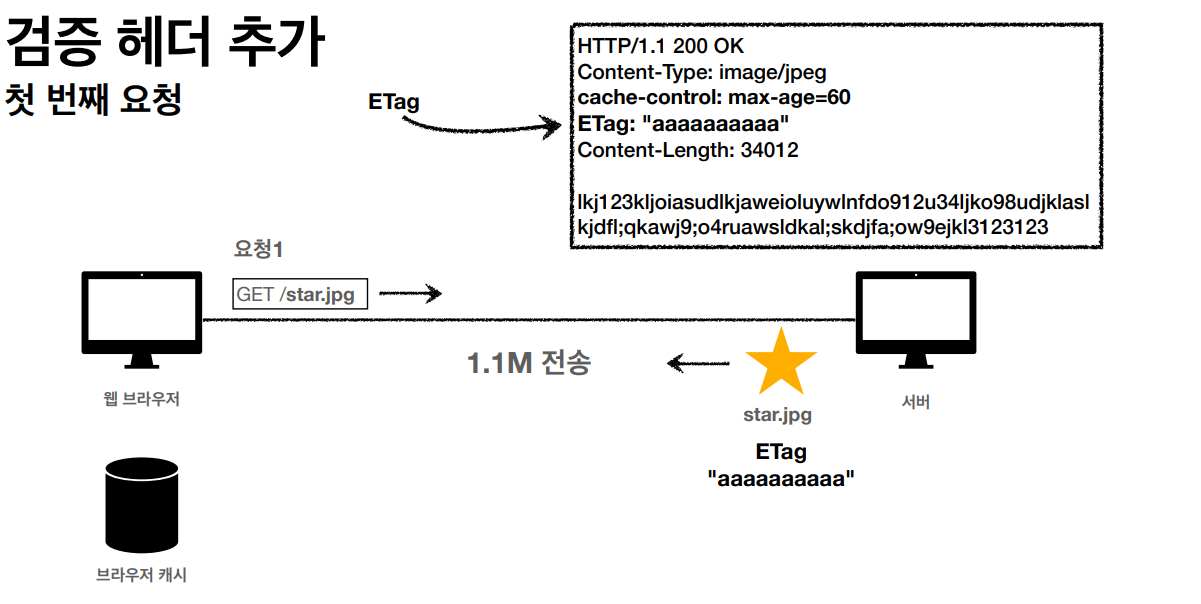
HTTP 캐싱은 서버 응답을 클라이언트(브라우저)나 중간 캐시 서버에 저장하여, 동일한 요청에 대해 다시 서버와 통신하지 않고도 응답을 재사용할 수 있게 하는 기능입니다.
캐시 가능성은 특정 HTTP 메서드가 반환하는 응답이 캐시에 저장될 수 있는지 여부를 나타냅니다.
HTTP 메서드와 캐싱
GET
캐시 가능하며, 주로 정적 자원(HTML, CSS, JS, 이미지 등)에 사용됩니다.
변경 가능성이 적은 데이터를 효율적으로 제공하기 위해 캐시가 널리 사용됩니다.
HEAD
캐시 가능하며, GET 메서드와 유사하게 작동하지만 응답 본문 없이 헤더만 반환합니다.
응답 본문이 없으므로 캐시를 검증하거나 메타데이터를 요청하는 데 적합합니다.
POST
일반적으로 캐싱하지 않음.
POST는 데이터 생성 또는 서버 상태 변경 요청에 사용되므로, 캐싱이 의미 없는 경우가 많습니다.
다만, 명시적으로 캐싱이 허용된 경우(예: 특정 API)에는 캐싱이 가능합니다.
GET은 서버로 데이터를 불러오기만 하지만 POST는 요청 내용이 항상 다른데, 전의 요청 내용 답변을 캐시에 저장해 둬도, 다음 대답에서 해당 캐시를 사용하게 될지는 미지수이기 때문 = 캐시 시 의도하지 않은 동작을 하는 경우가 있음 [의도하지 않은 동작은 아래 접은 글 참조]