필드(Field): 클래스의 속성을 나타내며, 객체가 가져야 할 데이터나 상태를 저장합니다. 필드는 변수와 유사하지만 클래스 내에 정의되어 객체의 상태를 나타내는 데 사용됩니다.
메소드(Method): 클래스가 수행하는 행동이나 기능을 정의합니다. 객체가 수행할 수 있는 작업을 메소드로 정의하며, 필드를 조작하거나 특정 기능을 수행하는 역할을 합니다.
생성자(Constructor): 객체를 생성할 때 호출되는 특별한 메소드로, 클래스 이름과 동일한 이름을 가집니다. 생성자를 통해 객체의 초기 상태를 설정할 수 있습니다.
접근 제어자(Access Modifier): 클래스, 필드, 메소드에 접근할 수 있는 범위를 제한하는 키워드입니다. 주로 public, private, protected 등이 있으며, 접근 범위를 명시하여 데이터 보호와 캡슐화를 구현할 수 있습니다.
클래스 생성
메소드와 함수의 차이
메소드(Method):
객체 지향 프로그래밍(OOP)에서 객체의 행위를 정의하는 코드 블록입니다.
클래스 내부에 정의되며, 특정 객체의 상태(필드)에 접근하고 이를 조작하는 데 사용됩니다.
메소드는 클래스에 종속적이기 때문에 객체를 통해 호출됩니다.
Java에서는 모든 함수가 클래스 안에 있어야 하므로, Java에서는 함수 대신 "메소드"라는 용어를 사용합니다.
함수(Function):
함수는 독립적인 코드 블록으로, 특정 작업을 수행하기 위해 사용됩니다.
객체 지향 언어가 아닌 프로그래밍 언어(예: C, JavaScript(ES6 이전))에서는 함수가 클래스에 소속되지 않고, 단독으로 존재할 수 있습니다.
함수는 클래스나 객체에 종속되지 않고, 필요에 따라 어디서든 호출할 수 있는 독립적인 개념입니다.
즉,모든 메소드는 함수이지만,모든 함수가 메소드인 것은 아닙니다.메소드는 객체에 속한 함수로 볼 수 있습니다.
public class Calculator {
public int add(int a, int b) { // add는 Calculator 클래스의 메소드
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
System.out.println(calculator.add(5, 3)); // 8
}
}
자동차 클래스 생성
public class Car {
String company; // 자동차 회사
String model; // 자동차 모델
String color; // 자동차 색상
double price; // 자동차 가격
double speed; // 자동차 속도, km/h 단위
char gear; // 기어 상태, P (주차), R (후진), N (중립), D (주행)
boolean lights; // 자동차 조명 상태, 켜짐(true) 또는 꺼짐(false)
// 기본 생성자: 매개변수 없이 Car 객체를 생성
public Car() {}
// gasPedal 메서드: 속도를 설정하는 메서드로 kmh 값을 speed 필드에 저장하고 반환
double gasPedal(double kmh) {
speed = kmh; // 자동차의 현재 속도를 kmh 값으로 설정
return speed; // 설정된 속도 반환
}
// brakePedal 메서드: 속도를 0으로 설정하는 메서드로, speed 필드를 0으로 설정하고 반환
double brakePedal() {
speed = 0; // 속도를 0으로 설정하여 정지 상태로 만듦
return speed; // 속도 0을 반환
}
// changeGear 메서드: 기어 상태를 변경하는 메서드로, type 값을 gear 필드에 저장하고 반환
char changeGear(char type) {
gear = type; // 기어를 매개변수 type의 값으로 설정
return gear; // 설정된 기어 상태 반환
}
// onOffLights 메서드: 조명 상태를 반전시키는 메서드로, 현재 lights 값을 반전시키고 반환
boolean onOffLights() {
lights = !lights; // 현재 조명 상태를 반전(true -> false, false -> true)
return lights; // 변경된 조명 상태 반환
}
// horn 메서드: 경적을 울리는 메서드로, 호출 시 "빵빵" 소리를 콘솔에 출력
void horn() {
System.out.println("빵빵"); // 경적 소리 출력
}
}
public class Main {
public static void main(String[] args) {
// Car 객체 생성
Car car = new Car();
// gasPedal 호출하여 속도 설정 및 출력
System.out.println("Current Speed: " + car.gasPedal(80)); // 속도 80 km/h 설정
// brakePedal 호출하여 속도 정지 상태로 변경 및 출력
System.out.println("Current Speed after braking: " + car.brakePedal()); // 속도 0 km/h 설정
// changeGear 호출하여 기어 상태 변경 및 출력
System.out.println("Current Gear: " + car.changeGear('D')); // 기어를 D로 변경
// onOffLights 호출하여 조명 상태 반전 및 출력
System.out.println("Lights On/Off: " + car.onOffLights()); // 조명 상태 변경
// horn 호출하여 경적 소리 출력
car.horn(); // "빵빵" 출력
}
}
객체 생성
new Car(); // Car클래스 객체 생성
객체 생성 연산자인 ‘new’를 사용하면 클래스로부터 객체를 생성할 수 있습니다.
new 연산자 뒤에는 해당 클래스의 생성자 호출 코드를 작성합니다.
형태가 Car();즉, 기본 생성자의 형태와 같기 때문에 new 연산자에 의해 객체가 생성되면서 기본 생성자가 호출됩니다.
참조형 변수
Car car1 = new Car(); // Car클래스의 객체인 car1 인스턴스 생성
Car car2 = new Car(); // Car클래스의 객체인 car2 인스턴스 생성
new 연산자를 통해서 객체가 생성되면 해당 인스턴스의 주소가 반환되기 때문에 해당 클래스의 참조형 변수를 사용하여 받아줄 수 있다.
객체 배열
객체는 참조형 변수와 동일하게 취급되기 때문에 배열 또는 컬렉션에도 저장하여 관리할 수 있다.
public class Main {
public static void main(String[] args) {
Car[] carArray = new Car[3];
Car car1 = new Car();
car1.changeGear('P');
carArray[0] = car1;
Car car2 = new Car();
car2.changeGear('N');
carArray[1] = car2;
Car car3 = new Car();
car3.changeGear('D');
carArray[2] = car3;
for (Car car : carArray) {
System.out.println("car.gear = " + car.gear);
}
}
}
// 출력
//car.gear = P
//car.gear = N
//car.gear = D
다형성은 "하나의 인터페이스(또는 메서드)가 여러 가지 형태를 가질 수 있다"는 의미입니다. 이를 통해 코드를 더 유연하고 확장 가능하게 만들어 줍니다.
위의 예시처럼 자동차는 K3, 아반떼, 테슬라등 여러가지 형태를 가질 수 있다. 차라는 역활이 테슬라라는 구체적인 대상으로 구현된 것이다.
이렇게 역활과 구현으로 구분하면 세상이 단순해지고, 유연해지며 변경이 편리해진다.
1. 실세계 비유
운전자 - 자동차: 운전자는 자동차의 내부 구조를 알 필요 없이 운전대, 브레이크, 가속기라는 역할(인터페이스)만 이용하면 된다. 자동차 내부를 바꿔도 운전자는 영향을 받지 않는다.
공연 무대: 무대에서 배우(역할)가 어떤 사람으로 바뀌어도, 대본(인터페이스)에 따라 공연이 진행된다. 배우가 바뀌더라도 공연은 유지된다.
키보드, 마우스, USB 등 표준 인터페이스: 다양한 키보드나 마우스가 연결되더라도 표준 인터페이스(USB)를 통해 동작한다. 하드웨어의 내부 구현은 다를 수 있지만, 인터페이스는 일정하다.
정렬 알고리즘: 정렬을 수행하는 인터페이스를 두고, QuickSort, MergeSort, BubbleSort 등의 구현을 상황에 따라 바꿀 수 있다.
할인 정책 로직: 다양한 할인 정책(예: 정률 할인, 정액 할인)을 인터페이스로 정의하고 구현을 바꿔도 로직은 변경되지 않는다.
2. 역할과 구현 분리
역할과 구현을 분리하면 다음과 같은 장점이 있다:
클라이언트는 대상의 역할(인터페이스)만 알면 된다.
구현 대상의 내부 구조를 몰라도 된다.
내부 구조가 변경되어도 클라이언트에 영향을 주지 않는다.
구현 대상을 아예 바꿔도 클라이언트가 영향을 받지 않는다.
객체 설계 원칙:
객체를 설계할 때 역할(인터페이스)을 먼저 정의하고, 이를 수행하는 구현 객체를 만든다.
클라이언트와 서버는 서로 협력 관계를 가지며, 서로 역할에만 의존한다.
3. 자바 언어에서 다형성
역할 = 인터페이스
예: MemberRepository라는 인터페이스.
구현 = 인터페이스를 구현한 클래스
예: MemoryMemberRepository, JdbcMemberRepository.
실행 시점에 객체 변경 가능:
public class MemberService { private MemberRepository memberRepository = new MemoryMemberRepository(); } // 구현 객체를 유연하게 변경 가능 public class MemberService { private MemberRepository memberRepository = new JdbcMemberRepository(); }
다형성의 본질:
실행 시점에 인터페이스를 구현한 객체를 유연하게 변경할 수 있다.
클라이언트를 변경하지 않고 서버의 구현 기능을 변경할 수 있다.
4. 스프링과 객체지향
스프링에서 다형성의 활용:
제어의 역전(IoC): 객체의 생성과 생명주기를 스프링이 관리.
의존관계 주입(DI): 필요한 객체를 주입받아 유연한 설계를 가능하게 함.
역할과 구현을 분리하여, 객체를 마치 레고 블록처럼 조립 가능.
공연 무대에서 배우를 교체하듯, 구현을 간단히 변경 가능.
5. 다형성의 장점
유연한 설계 가능.
변경에 대한 영향 최소화.
확장성 향상.
코드 재사용성 증가.
구현의 내부 구조를 은닉하여 클라이언트를 단순화.
6. 다형성의 한계
역할(인터페이스) 자체가 변하면, 클라이언트와 서버 모두 큰 변경이 필요:
예: 자동차 인터페이스를 비행기로 변경.
USB 인터페이스의 규격 변경.
해결 방안:
인터페이스를 안정적으로 설계하는 것이 중요.
7. 요약
다형성은 객체 간 협력을 기반으로 역할과 구현을 분리해 유연하고 확장 가능한 설계를 가능하게 한다.
스프링 프레임워크는 다형성을 극대화하여 객체 지향 설계를 돕는 강력한 도구를 제공한다.
IoC와 DI를 활용해 구현체를 쉽게 교체하거나 확장할 수 있다.
인터페이스 설계의 안정성이 다형성 설계의 핵심이다.
객체 간의 협력
객체간의 상호작용을 말한다.
사람이 자동차의 가속 페달을 밟으면 자동차는 이에 반응하여 속도를 올리며 앞으로 이동합니다.
사람이 자동차의 브레이크 페달을 밟으면 자동차는 이에 반응하여 속도를 줄이며 정지합니다.
자바에서 객체는 메서드를 통해서 서로 상호작용하면서 데이터를 주고 받을 수 있다.
예를 들어 사람이 자동차 객체가 가지고 있는 가속페달 메서드gasPedal(50);을 호출하면 자동차는 이 메서드에 반응하여 속도 속성의 값을 50으로 수정시킨다. 그러면 사람 객체는 자동차 객체의 브레이크 페달 brakePedal();을 호출한다.
+ 여기서 50은 매개값, 파라미터 라고 불리며 메서드 호출시 데이터를 포함해 호출하게 해준다
또한 자동차 객체는 gasPedal(50); 메서드에서 속도를 바꾸는 작업을 수행한 후 사람 객체에게 실행 결과인 속도의 값을 반환할 수 있습니다. 이때 반환되는 값을 ‘리턴값’이라 표현한다.
객체 간의 관계
객체간의 협력에도 종류가 있는데, 크게 사용관계, 포함관계, 상속관계가 존재한다.
사용 관계
사람 객체는 자동차 객체를 사용한다.
포함 관계
타이어 객체, 차 문 객체, 핸들 객체는 자동차 객체에 포함되어 있다.
상속 관계
만약 공장에 자동차만 생산하는 게 아니라 기차도 생산한다고 가정해 보자.
자동차와 기차 객체는 하나의 공통된 기계 시스템 객체를 토대로 만들어진다.
그렇다면 자동차 객체와 기차 객체는 기계 시스템 객체를 상속받는 상속 관계가 된다.
자바는 효율성을 강조한 언어이다. 위의 blueprint를 Car, Train 객체에서 각각 1번씩 정의하는 방식보다는, 그 상위 객체인 MachineSystem에서 한번만 정의하고 하위 객체에게 주소를 넘겨주는게 메모리 효율성이 높다.
// 부모 클래스
class Animal {
// 공통 메소드
public void eat() {
System.out.println("This animal eats food.");
}
}
// 자식 클래스
class Dog extends Animal {
// 자식 클래스에만 있는 메소드
public void bark() {
System.out.println("The dog barks.");
}
// 부모 클래스의 메소드 오버라이딩
@Override
public void eat() {
System.out.println("The dog eats dog food.");
}
}
public class Main {
public static void main(String[] args) {
Dog dog = new Dog();
// 상속받은 메소드 사용
dog.eat(); // The dog eats dog food.
dog.bark(); // The dog barks.
}
}
Dog 클래스: Animal 클래스를 상속받아 bark() 메소드를 추가했고, eat() 메소드를 오버라이딩하여 개에 맞는 동작을 정의했습니다.
오버라이딩: eat() 메소드를 자식 클래스에서 재정의하여 다형성을 구현했습니다.
캡슐화
캡슐화란 속성(필드)와 행위(메서드)를 하나로 묶어 객체로 만든 후 실제 내부 구현 내용은 외부에서 알 수 없게 감추는 것을 의미합니다. (안전성 확보)
외부 객체에서는 캡슐화된 객체의 내부 구조를 알 수 없기 때문에 노출시켜 준 필드 혹은 메서드를 통해 접근할 수 있습니다.
필드와 메서드를 캡슐화하여 숨기는 이유는 외부 객체에서 해당 필드와 메서드를 잘못 사용하여 객체가 변화하지 않게 하는 데 있습니다.
Java에서는 캡슐화된 객체의 필드와 메서드를 노출시킬지 감출지 결정하기 위해 접근 제어자를 사용합니다.
캡슐화
단순히 설명하면, 알약 캡슐처럼 내용을 하나의 알약에 담는다. 다만 알약이 밖에서 볼때 어떤 성분이 있는지 확인할 수 없듯 기본적으로 캡슐화가 된 클래스의 내용은 확인할 수 없다. 하지만 프로그래머가 예외로 설정한 데이터, 메소드에는 접근할 수 있다.
public class User {
// private 접근 제어자를 사용하여 필드를 외부에서 직접 접근하지 못하게 함
private String name;
private int age;
// 생성자를 통해 객체 초기화
public User(String name, int age) {
this.name = name;
this.age = age;
}
// getter 메소드: 필드에 대한 접근을 제공
public String getName() {
return name;
}
public int getAge() {
return age;
}
// setter 메소드: 필드를 수정할 수 있게 제공
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
if(age > 0) { // 유효성 검사를 통해 데이터 보호
this.age = age;
} else {
System.out.println("Age must be greater than 0.");
}
}
}
위의 private는 '개인적으로' 라는 의미로 캡슐만이 알 수 있고 외부에서 접근할 수 없는 데이터나 메소드를 만들어준다.
반대로 public은 '공공적으로' 라는 의미로 외부에서 접근이 가능하고 수정까지도 할 수 있게 해준다.
상속
객체지향 프로그래밍에는 부모 객체와 자식 객체가 존재합니다.
부모 객체는 가지고 있는 필드와 메서드를 자식 객체에 물려주어 자식 객체가 이를 사용할 수 있도록 만들 수 있습니다.
상속
위에서 설명했던 대로, 효율성을 추구하는 자바라는 언어 특성상 굳이 곂치는 내용을 여러번 정의하는 것을 꺼린다. MachineSystem의 자식인 Car, Train에서 bluePrint를 정의하지 않고 부모인 MachineSystem에서 데이터를 상속받아 사용한다.
상속의 특징
코드 재사용성: 기존에 작성한 클래스의 코드와 기능을 자식 클래스에서 재사용할 수 있습니다. 이는 중복 코드를 줄이고 코드 유지보수를 쉽게 해줍니다.
계층 구조 생성: 부모-자식 관계의 계층 구조를 만들어 시스템을 구조적으로 관리할 수 있습니다. 이를 통해 클래스 간의 관계를 명확히 할 수 있습니다.
확장성: 새로운 기능이 필요할 때 기존 클래스에 추가하기보다 자식 클래스를 만들어 확장할 수 있습니다. 이렇게 하면 기존 클래스는 변경하지 않고 기능을 확장할 수 있어 코드의 안정성이 높아집니다.
다형성(Polymorphism): 상속을 통해 생성된 자식 클래스는 부모 클래스의 메소드를 자신의 방식대로 재정의(오버라이딩)할 수 있습니다. 이를 통해 부모 클래스를 참조하는 변수로 여러 자식 클래스의 인스턴스를 다룰 수 있습니다.
상속의 장점
코드 중복 감소: 자식 클래스가 부모 클래스의 속성과 메소드를 상속받아 사용할 수 있으므로 중복 코드를 줄일 수 있습니다.
유지보수 용이: 공통 기능을 부모 클래스에서 관리하기 때문에 수정 사항이 있을 때 모든 자식 클래스에 일관되게 반영할 수 있습니다. 예를 들어, 부모 클래스의 메소드를 수정하면 자식 클래스에서도 그 변화가 반영됩니다.
모듈화: 관련 있는 기능을 부모 클래스에 모아 두고, 세부적인 기능은 자식 클래스에 추가하여 코드가 모듈화되어 구조적인 프로그램을 작성할 수 있습니다.
다형성: 상속을 통해 다형성을 구현하여 코드의 유연성과 확장성을 높일 수 있습니다. 이를 통해 동일한 부모 클래스를 참조하는 변수가 다양한 형태로 동작할 수 있습니다.
추상화
객체에서 공통된 부분들을 모아 상위 개념으로 새롭게 선언하는 것을 추상화라고 합니다
자식들 중 공통된 특징(데이터, 메소드)이 있다면 부모에 선언하는 방식 https://velog.velcdn.com/images/dev-mage/post/55d11b06-01b6-42a6-b982-a97489ecbcc6/image.png
1-1이 자동차고, 그 하위가 페라리, 포터, 벤츠라고 하면 자식들은 바퀴가 4개인 특징이 있다. 이런 공통적인 특징이 있다면 1-1인 자동차에서 바퀴가 4개이다를 정의하고 아래 자식들에게 뿌려주면 된다. 이런 역전 방식을 추상화라한다.
추상화의 특징
중요한 정보만 노출: 추상화는 클래스나 객체의 중요한 속성과 동작을 중심으로 표현하여, 불필요한 세부 사항을 감춥니다. 사용자는 인터페이스나 메소드의 기본 동작 방식만 알면 되며, 내부 동작 원리를 몰라도 됩니다.
추상 클래스와 인터페이스 사용: 추상화는 주로 abstract 키워드로 선언된 추상 클래스나 인터페이스를 통해 구현됩니다. 추상 클래스는 공통 동작을 정의하고, 인터페이스는 반드시 구현해야 할 메소드를 선언함으로써 각기 다른 클래스가 공통된 동작을 갖도록 합니다.
구현의 강제성: 추상 클래스나 인터페이스를 사용하면, 상속받는 클래스가 특정 메소드를 반드시 구현하도록 강제할 수 있습니다. 이를 통해 코드의 일관성과 안정성을 높일 수 있습니다.
유연한 확장 가능성: 추상화를 사용하면 클래스 간의 결합도를 낮출 수 있어, 코드의 유연성과 확장 가능성이 높아집니다. 시스템이 확장되거나 변경되어도 기존 코드를 최소한으로 수정하면서 기능을 추가할 수 있습니다.
추상화의 장점
코드의 단순화: 불필요한 세부 사항을 숨기고 중요한 정보만 제공하여 코드의 복잡성을 줄이고 이해하기 쉽게 만듭니다. 사용자 입장에서 복잡한 내부 로직을 알 필요 없이 필요한 기능만 사용할 수 있습니다.
유지보수성 향상: 인터페이스나 추상 클래스는 공통된 작업 방식을 정의하고 구현체는 이를 따르기 때문에, 유지보수가 쉬워집니다. 새로운 기능을 추가하거나 수정할 때 전체 시스템에 미치는 영향을 줄일 수 있습니다.
모듈화 및 확장성: 추상화를 통해 각 클래스가 독립적으로 동작하면서도 동일한 인터페이스나 추상 클래스의 규칙을 따르기 때문에, 시스템의 모듈화가 용이해집니다. 이는 새로운 기능을 추가하거나 기존 코드를 수정할 때 유연성을 제공합니다.
다형성 지원: 추상 클래스와 인터페이스를 통해 다양한 객체들이 동일한 인터페이스를 따르도록 할 수 있어 다형성(Polymorphism)을 구현하기 쉽습니다. 예를 들어, 동일한 메소드를 다양한 방식으로 구현하여 객체마다 다른 동작을 수행하게 할 수 있습니다.
// 추상 클래스
abstract class Shape {
// 추상 메소드 - 구체적인 구현은 자식 클래스에서 정의
public abstract double calculateArea();
// 공통 메소드
public void display() {
System.out.println("This is a shape.");
}
}
// 구체 클래스 - Circle
class Circle extends Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
// 추상 메소드 구현
@Override
public double calculateArea() {
return Math.PI * radius * radius;
}
}
// 구체 클래스 - Rectangle
class Rectangle extends Shape {
private double width;
private double height;
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
// 추상 메소드 구현
@Override
public double calculateArea() {
return width * height;
}
}
public class Main {
public static void main(String[] args) {
Shape circle = new Circle(5);
Shape rectangle = new Rectangle(4, 6);
circle.display(); // This is a shape.
System.out.println("Circle Area: " + circle.calculateArea()); // Circle Area: 78.5398...
rectangle.display(); // This is a shape.
System.out.println("Rectangle Area: " + rectangle.calculateArea()); // Rectangle Area: 24.0
}
}
추상 클래스 Shape: Shape 클래스는 calculateArea()라는 추상 메소드를 선언했습니다. 이 메소드는 구체 클래스에서 정의되어야 합니다.
구체 클래스 Circle과 Rectangle: Shape 클래스를 상속받아 calculateArea() 메소드를 각각 원과 사각형에 맞게 구현했습니다.
추상화의 효과: Shape 클래스를 상속받은 모든 도형 클래스는 calculateArea() 메소드를 반드시 구현하도록 강제됩니다. 이를 통해 각 도형 클래스가 calculateArea() 메소드를 통해 면적을 계산할 수 있다는 점에서 일관된 사용법을 제공하게 됩니다.
객체와 클래스
우리는 객체를 생성하기 위해서 설계도가 필요합니다.
현실 세계에서는 자동차를 만들기 위해 자동차 설계도를 토대로 자동차를 생산합니다.
마찬가지로 소프트웨어에서도 객체를 만들기 위해서는 설계도에 해당하는 클래스가 필요합니다.
이때 클래스를 토대로 생성된 객체를 해당 클래스의 ‘인스턴스’라고 부르며 이 과정을 ‘인스턴스화’라고 부릅니다.
동일한 클래스로 여러 개의 인스턴스를 만들 수 있습니다.
이때 객체와 인스턴스는 거의 비슷한 표현이지만 자세하게 구분해 보자면 아래와 같습니다.
자동차 클래스를 통해 만들어진 하나의 자동차를 인스턴스라고 부르며 이러한 여러 개의 인스턴스들을 크게 통틀어서 자동차 객체라고 표현할 수 있다.
class Car {
String model;
String color;
// 기본 생성자
public Car(String model, String color) {
this.model = model;
this.color = color;
}
// gasPedal 메서드: 속도를 설정하는 메서드로 kmh 값을 speed 필드에 저장하고 반환
public double gasPedal(double kmh) {
speed = kmh; // 자동차의 현재 속도를 kmh 값으로 설정
return speed; // 설정된 속도 반환
}
}
public class Main {
public static void main(String[] args) {
// 인스턴스화 과정
Car car1 = new Car("Sedan", "Red"); // Car 클래스로부터 car1 객체 생성
Car car2 = new Car("SUV", "Blue"); // Car 클래스로부터 car2 객체 생성
System.out.println(car1.model); // Sedan 출력
System.out.println(car2.model); // SUV 출력
}
}
슬슬 헷갈릴 건데 간단히 하면
인스턴스(객체)
car1, car2
인스턴스화
new
메서드
public double gasPedal(double kmh)
클래스
class Car
생성자
public Car(String model, String color) / 생성자는 메서드와 다르게 클래스와 이름이 같다
Carcar1 = new Car("Sedan", "Red");는 Car 클래스를 사용하여 "Sedan"과 "Red"라는 속성값을 가지는 새로운 Car 객체를 생성하고, 그 객체를 car1이라는 참조형 변수에 참조하도록 하는 코드
변수 선언에서 보통 참조형 변수가 사람의 머리를 가장 잘 쪼개주는데, 그냥 상자에 물건을 담는게 아니라 물건을 HEAP이라는 상자에 담고 STACK에는 HEAP이라는 상자의 위치(주소)를 저장해 버린다..
참조형 변수(배열)
사실 생각해보면 이상하다. 그냥 값만 저장하면 1개만 저장하면 되는데, 뭐하러 주소와 값을 같이 저장해서 메모리 공간을 2배로 차지하는 것일까.. 하지만 여기에는 중요한 이유가 있다.
왜 이런 일이 발생했는지 간단히 설명해 보자면 '객체 지향 프로그래밍과 효율적인 메모리 관리를 위해서' 이다. 예를 들어보자
1. 효율적인 메모리 관리를 위해
String str = "Hello";
여기서 str 변수는 "Hello"라는 값을 직접 저장하는 것이 아니라, "Hello"라는 문자열이 메모리 어딘가에 저장된 주소를 저장한다. 만약 "Hello"라는 문자열을 직접 값으로 저장하려면, "Hello"라는 데이터를 여러 번 복사해야 하는 번거로움이 발생할 수 있는 반면, 참조형 변수는 이 주소만 저장하면 되므로 메모리 절약이 가능하다.
= 재활용이 가능하다. hello라는 변수를 5번 선언해 메모리 5칸 먹을 바엔, 5개의 변수에 주소 1개, 값 1개만 할당하면 메모리 2칸만 사용한다는 의미이다.
2. 객체 지향 프로그래밍(OOP)의 핵심
이게 무슨 말인지를 알기 위해서는 Java의 핵심인 객체 지향이 뭔지 알아야한다.
객체 지향에서 객체는 속성(데이터)과 행동(기능)을 가지고 있는 구분 가능한 세트를 말한다.
객체 지향
예를 들어, 강아지라는 객체는 이름, 나이라는 속성을 가지고, 짖기, 산책하기와 같은 행동을 할 수 있다. 이러한 특징의 세트를 가진 존재를 객체라고 정의한다.
Person person1 = new Person("Alice", 30);
Person person2 = person1; // person2는 person1의 주소를 가리킴
person2.setName("Bob"); // person1과 person2 모두 "Bob"을 가리키게 됨
위 코드에서 사람이라는 객체는 (앨리스, 30)이라는 속성을 가지고 있다. 그리고 그 중 이름을 bob으로 수정하는 코드이다.
만약에 위와 같이 객체의 내용을 바꿔야할 때 마다. 객체를 복사해야한다면 어떨까?
1. 객체를 복사한다
2. 복사된 객체의 정보를 저장한다
3. 원본 객체를 지운다.
이 과정을 거친다. 이 과정은 메모리 사용량을 늘리고, 복잡한 코드를 작성하게 만든다. 차라
1. 객체 중 이름의 변수 내용을 수정한다
2. 수정한 내용을 저장한다.
이게 더 편하고 유용하다는 것.
정말 간단하게 이해하자면
상황
a 아파트에 배달을 해야하는데, 아파트의 이름이 b로 바뀌어야한다.
객체 지향
배달원에게 아파트이름이 a->b로 바뀌었다고 알려준다
절차적 프로그래밍
아파트 b를 새로 만들고 아파트a를 부순다.
아무리 그래도 아파트를 부수고 다시 건축하는 방식보단 주소를 변경해주는 것이 여러 의미로 이로울 것이다;;
결론적으로 위와 같은 객체 지향적 프로그래밍과 효율적인 메모리 관리를 위해 참조형 변수를 사용하게 되었다는 것
Java의 Collection
데이터를 저장하고 다룰 수 있는 다양한 방법을 제공하는 인터페이스와 클래스들의 집합으로, 자바에서 Collection Framework는 데이터를 효율적으로 다룰 수 있도록 도와주는 핵심적인 역할을 하며, 여러 가지 자료구조와 알고리즘을 제공한다.
리스트( ArrayList )의 경우 타입, 저장량, 수정 모두 관계없이 동적으로 늘어나고 자유롭게 수정이 가능하다.(참조형 변수) 다만, 배열(Array)처럼 일렬로 데이터를 저장하고 조회하여 순번 값(인덱스)로 값을 하나씩 조회할 수 있다.
// ArrayList
// (사용하기 위해선 import java.util.ArrayList; 를 추가해야합니다.)
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<Integer> intList = new ArrayList<Integer>(); // 선언 및 생성
intList.add(1);
intList.add(2);
intList.add(3);
System.out.println(intList.get(0)); // 1 출력
System.out.println(intList.get(1)); // 2 출력
System.out.println(intList.get(2)); // 3 출력
System.out.println(intList.toString()); // [1,2,3] 출력
intList.set(1, 10); // 1번순번의 값을 10으로 수정합니다.
System.out.println(intList.get(1)); // 10 출력
intList.remove(1); // 1번순번의 값을 삭제합니다.
System.out.println(intList.toString()); // [1,3] 출력
intList.clear(); // 전체 값을 삭제합니다.
System.out.println(intList.toString()); // [] 출력
}
}
값 수정 : intList.set({수정할 순번}, {수정할 값}) 형태로 값을 수정합니다.
값 삭제 : intList.remove({삭제할 순번}) 형태로 값을 삭제합니다.
전체 출력 : intList.toString() 형태로 전체 값을 대괄호[]로 묶어서 출력합니다.
전체 제거 : intList.clear() 형태로 전체 값을 삭제합니다.
LinkedList
LinkedList
메모리에 남는 공간을 요청해서 여기저기 나누어서 실제 값을 담아 놓고, 실제 값이 있는 주소값으로 목록을 구성하고 저장합니다. (남는 공간 아무대나 저장하고 데이터 위치를 주소로 찾는다)
기본적인 기능은 ArrayList 와 동일하지만 LinkedList는 값을 나누어 담기 때문에 모든 값을 조회하는 속도가 느립니다. 대신에, 값을 중간에 추가하거나 삭제할 때는 속도가 빠릅니다.
중간에 값을 추가하는 기능이 있습니다. (여기선 속도 빠르다. 순서 지정 없이 아무대나 막 저장해서)
// LinkedList
// (사용하기 위해선 import java.util.LinkedList; 를 추가해야합니다.)
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList<>(); // 선언 및 생성
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println(linkedList.get(0)); // 1 출력
System.out.println(linkedList.get(1)); // 2 출력
System.out.println(linkedList.get(2)); // 3 출력
System.out.println(linkedList.toString()); // [1,2,3] 출력 (속도 느림)
linkedList.add(2, 4); // 2번 순번에 4 값을 추가합니다.
System.out.println(linkedList); // [1,2,4,3] 출력
linkedList.set(1, 10); // 1번순번의 값을 10으로 수정합니다.
System.out.println(linkedList.get(1)); // 10 출력
linkedList.remove(1); // 1번순번의 값을 삭제합니다.
System.out.println(linkedList); // [1,4,3] 출력
linkedList.clear(); // 전체 값을 삭제합니다.
System.out.println(linkedList); // [] 출력
}
}
값 중간에 추가 : linkedList.add({추가할 순번}, {추가할 값}) 형태로 값을 중간에 추가합니다.
값 수정 : linkedList.set({수정할 순번}, {수정할 값}) 형태로 값을 수정합니다.
값 삭제 : linkedList.remove({삭제할 순번}) 형태로 값을 삭제합니다.
전체 출력 : linkedList.toString() 형태로 전체 값을 대괄호[]로 묶어서 출력합니다.
전체 제거 : linkedList.clear() 형태로 전체 값을 삭제합니다.
stack
수직으로 쌓아놓고 넣었다가 빼서 조회하는 형식으로 데이터를 관리하는 방식
이걸 “나중에 들어간 것이 가장 먼저 나온다(Last-In-First-out)” 성질을 가졌다고 표현한다.
넣는 기능(push()) 과 조회(peek()), 꺼내는(pop()) 기능만 존재한다.
Stack
스택을 사용하는 이유:
간단한 메모리 관리 스택은 후입선출(LIFO) 구조로 동작하는데, 이는 함수 호출이나 작업을 관리하는 데 유용합니다. 프로그램에서 함수가 호출될 때마다 그 함수의 실행 정보를 스택에 저장하고, 함수가 끝나면 그 정보를 스택에서 꺼내는 방식으로 동작합니다. 이를 통해 함수의 호출 및 반환을 효율적으로 관리할 수 있습니다.
재귀 알고리즘 처리 재귀 함수는 자기 자신을 호출하는 방식으로 동작합니다. 재귀 함수 호출 시, 각 호출의 상태를 스택에 저장하며, 함수 호출이 끝나면 스택에서 해당 상태를 꺼내어 돌아가게 됩니다. 스택은 재귀 함수의 동작을 간단하게 처리할 수 있게 도와줍니다.
작업의 순서 보장 스택은 마지막에 추가된 데이터를 먼저 꺼내기 때문에, 작업의 순서를 보장하는 데 유용합니다. 예를 들어, 웹 브라우저의 뒤로 가기 버튼은 이전 페이지의 URL을 스택에 저장하고, 뒤로 가기 버튼을 클릭하면 스택에서 URL을 꺼내서 이전 페이지로 돌아갑니다.
Undo/Redo 기능 스택은 되돌리기(Undo)와 다시 하기(Redo) 기능을 구현하는 데 매우 유용합니다. 예를 들어, 문서 편집 프로그램에서 사용자가 어떤 작업을 실행할 때마다 그 작업을 스택에 저장하고, Undo 버튼을 클릭하면 마지막 작업을 꺼내서 이전 상태로 되돌릴 수 있습니다. 다시 하기 기능은 Undo 스택을 이용해 처리할 수 있습니다.
괄호 짝 맞추기 컴파일러나 코드 분석기에서 스택을 사용하여 괄호의 짝을 맞추는 작업을 처리합니다. 괄호가 열릴 때마다 스택에 저장하고, 괄호가 닫힐 때마다 스택에서 꺼내는 방식으로 짝을 맞출 수 있습니다.
위의 기능을 많이 이야기 하지만, 가장 중요한 점은 최근 저장된 데이터를 나열하고 싶거나 데이터의 중복 처리를 막고 싶을 때 사용한다.
// Stack
// (사용하기 위해선 import java.util.Stack; 를 추가해야합니다.)
import java.util.Stack;
public class Main {
public static void main(String[] args) {
Stack<Integer> intStack = new Stack<Integer>(); // 선언 및 생성
intStack.push(1);
intStack.push(2);
intStack.push(3);
while (!intStack.isEmpty()) { // 다 지워질때까지 출력
System.out.println(intStack.pop()); // 3,2,1 출력
}
// 다시 추가
intStack.push(1);
intStack.push(2);
intStack.push(3);
// peek()
System.out.println(intStack.peek()); // 3 출력
System.out.println(intStack.size()); // 3 출력 (peek() 할때 삭제 안됬음)
// pop()
System.out.println(intStack.pop()); // 3 출력
System.out.println(intStack.size()); // 2 출력 (pop() 할때 삭제 됬음)
System.out.println(intStack.pop()); // 2 출력
System.out.println(intStack.size()); // 1 출력 (pop() 할때 삭제 됬음)
while (!intStack.isEmpty()) { // 다 지워질때까지 출력
System.out.println(intStack.pop()); // 1 출력 (마지막 남은거 하나)
}
}
}
편의점 알바에서 많이 듣게 되는 선입선출(Fist In First Out)을 성질로 갖고 있는 Collection
넣는 기능(add()) 과 조회(peek()), 꺼내는(poll()) 기능만 존재한다.
Queue는 생성자가 없는 껍데기라서 바로 생성할 수는 없습니다. (껍데기 = 인터페이스)
생성자가 존재하는 클래스인 LinkedList를 사용하여 Queue를 생성해서 받을 수 있습니다.
// LinkedList 를 생성하면 Queue 기능을 할 수 있습니다. (Queue 가 부모/ LinkedList 가 자식이기 떄문)
Queue<Integer> intQueue = new LinkedList<Integer>();
이걸 이해하기 위해서는 인터페이스와 생성자, 오버로딩의 개념을 알 필요가 있다.
인터페이스 (Interface) = 설계도
자바에서 클래스가 구현해야 하는 계약을 정의하는 구조로 쉽게 말해, 인터페이스는 "어떤 메서드들이 있어야 한다"고 약속만 정의하고, 그 구현 내용은 다른 클래스에서 작성합니다.
말 그대로 클래스의 설계도로, 아래의 Animal 처럼 Animal 인터페이스에 포함될 클래스는 반드시 sound라는 메서드를 포함 시켜 주세요라는 설계도를 말한다.
// Animal 인터페이스
interface Animal {
void sound(); // sound 메서드만 선언, 구현은 강제
}
// Dog 클래스는 Animal 인터페이스를 구현해야 하므로 sound 메서드를 반드시 구현해야 한다.
class Dog implements Animal {
@Override
public void sound() {
System.out.println("Bark");
}
}
// Cat 클래스도 Animal 인터페이스를 구현해야 하므로 sound 메서드를 반드시 구현해야 한다.
class Cat implements Animal {
@Override
public void sound() {
System.out.println("Meow");
}
}
public class Main {
public static void main(String[] args) {
Animal dog = new Dog();
Animal cat = new Cat();
dog.sound(); // Bark
cat.sound(); // Meow
}
}
생성자 (Constructor)
객체가 생성될 때 초기화 작업을 담당하는 특별한 메서드입니다. 자바에서 생성자는 클래스 이름과 동일하고, 반환 값이 없습니다(즉, void도 사용하지 않습니다). 생성자는 객체가 생성될 때 자동으로 호출되며, 클래스의 속성(멤버 변수)을 초기화하는 데 사용됩니다.
말이 어려운데, 객체의 기본 초기값을 설정하여 객체를 추가로 생성해도 값이 미리 지정해 둔 값으로 초기화 될 수 있도록 한 메소드
생성자의 특징:
클래스 이름과 동일한 이름을 가집니다.
반환 타입이 없습니다 (반환 타입으로 void도 사용하지 않습니다 = 반환이 필요 없다).
자동 호출됩니다: 객체가 생성될 때마다 생성자가 자동으로 실행됩니다. (미리 지정해 두었으니..)
생성자는 오버로딩할 수 있습니다: 같은 클래스 내에서 여러 개의 생성자를 정의할 수 있습니다. 이때, 매개변수의 개수나 타입을 달리하여 구별합니다.
기본 생성자 (Default Constructor)
생성자를 명시적으로 정의하지 않으면, 자바 컴파일러가 기본 생성자(default constructor)를 자동으로 제공합니다.
기본 생성자는 매개변수가 없고, 객체를 생성할 때 기본적인 초기화 작업을 합니다.
class Person {
String name;
int age;
// 기본 생성자
public Person() {
name = "Unknown";
age = 0;
}
// 매개변수가 있는 생성자 (이름만 받는 생성자)
public Person(String name) {
this.name = name;
this.age = 0; // 나이는 기본값 0
}
// 매개변수가 있는 생성자 (이름과 나이 받는 생성자)
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 메서드
public void introduce() {
System.out.println("이름: " + name + ", 나이: " + age);
}
}
public class Main {
public static void main(String[] args) {
// 기본 생성자 사용
Person person1 = new Person();
person1.introduce(); // 이름: Unknown, 나이: 0
// 이름만 받는 생성자 사용
Person person2 = new Person("Alice");
person2.introduce(); // 이름: Alice, 나이: 0
// 이름과 나이를 받는 생성자 사용
Person person3 = new Person("Bob", 25);
person3.introduce(); // 이름: Bob, 나이: 25
}
}
오버로딩
같은 이름의 메서드나 생성자를매개변수의 개수나 타입이 달라지도록 여러 번 정의하는 기법입니다. 오버로딩을 사용하면같은 이름으로 다양한 작업을 처리할 수 있습니다.
오버로딩의 특징
같은 이름의 메서드나 생성자지만매개변수의 개수나 타입이 달라야 합니다.
반환 타입은 오버로딩을 구별하는 기준이 되지 않습니다.
컴파일 시점에 메서드 호출을 구분하기 때문에, 실행 시간에 결정되는 것이 아니라호출 시점에서적절한 메서드가 선택됩니다.
오버로딩의 장점
코드의 가독성 향상: 비슷한 작업을 수행하는 메서드를 같은 이름으로 처리할 수 있어 코드가 깔끔하고 이해하기 쉬워집니다.
유지보수 용이성: 같은 이름의 메서드를 사용하여 여러 매개변수에 대한 처리 로직을 관리할 수 있어 유지보수가 용이합니다.
오버로딩 규칙
매개변수의 타입이 달라야 오버로딩으로 인식됩니다.
매개변수의 개수가 달라야 오버로딩으로 인식됩니다.
매개변수의 순서가 달라야 오버로딩으로 인식됩니다.
class Person {
String name;
int age;
// 기본 생성자
public Person() {
name = "Unknown";
age = 0;
}
// 매개변수가 있는 생성자 (이름만 받는 생성자)
public Person(String name) {
this.name = name;
this.age = 0; // 나이는 기본값 0
}
// 매개변수가 있는 생성자 (이름과 나이 받는 생성자)
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 메서드
public void introduce() {
System.out.println("이름: " + name + ", 나이: " + age);
}
}
public class Main {
public static void main(String[] args) {
// 기본 생성자 사용
Person person1 = new Person();
person1.introduce(); // 이름: Unknown, 나이: 0
// 이름만 받는 생성자 사용
Person person2 = new Person("Alice");
person2.introduce(); // 이름: Alice, 나이: 0
// 이름과 나이를 받는 생성자 사용
Person person3 = new Person("Bob", 25);
person3.introduce(); // 이름: Bob, 나이: 25
}
}
< 출력 결과 >
이름: Unknown, 나이: 0 이름: Alice, 나이: 0 이름: Bob, 나이: 25
이해를 위한 오버로딩의 어원 **오버로딩(Overloading)**이라는 용어는 **'과잉(Over)'**과 **'적재(Loading)'**의 결합으로, 프로그래밍에서 특정 작업이나 기능이 여러 방식으로 "과잉"으로 제공된다는 개념을 나타냅니다.
즉, **오버로딩(Overloading)**은하나의 메소드나 생성자가 여러 형태로 존재한다는 개념입니다. 메소드 이름은 같지만, 매개변수의 수나 타입에 따라 서로 다른 구현이 가능하다는 뜻입니다. 이 개념은하나의 이름으로 여러 기능을 제공하는 것으로, "과잉 적재"의 개념을 표현하고 있습니다.
2. **이름만 받는 생성자** (`Person(String name)`): - 하나의 매개변수(`String name`)만 받는 생성자입니다. - `name`을 매개변수로 받아 초기화하고, `age`는 기본값인 `0`으로 초기화합니다.
3. **이름과 나이를 받는 생성자** (`Person(String name, int age)`): - 두 개의 매개변수(`String name`, `int age`)를 받는 생성자입니다. - `name`과 `age`를 매개변수로 받아 초기화합니다.
오버로딩 설명 **생성자 오버로딩**은 **같은 이름**의 생성자를 **매개변수의 개수나 타입이 다르게 정의**하여, 객체를 생성할 때 다양한 방법으로 초기화를 할 수 있게 해주는 기능입니다. 위 코드에서 `Person` 클래스의 생성자는 **세 가지 형태로 오버로딩**되어 있으며, 각기 다른 방식으로 객체를 초기화할 수 있습니다.
어떻게 오버로딩이 이루어졌는지
1. **기본 생성자** (`Person()`): - `Person person1 = new Person();` 이 코드에서는 매개변수가 없는 기본 생성자가 호출됩니다. 그래서 `name`은 `"Unknown"`, `age`는 `0`으로 초기화됩니다.
2. **이름만 받는 생성자** (`Person(String name)`): - `Person person2 = new Person("Alice");` 이 코드에서는 이름만 받는 생성자가 호출됩니다. `name`은 `"Alice"`, `age`는 기본값인 `0`으로 초기화됩니다.
3. **이름과 나이를 받는 생성자** (`Person(String name, int age)`): - `Person person3 = new Person("Bob", 25);` 이 코드에서는 이름과 나이를 받는 생성자가 호출됩니다. `name`은 `"Bob"`, `age`는 `25`로 초기화됩니다.
생성자 오버로딩의 장점: - **유연성**: 같은 클래스의 객체를 다양한 방법으로 생성할 수 있습니다. 예를 들어, `Person` 클래스의 객체를 `name`만 받거나, `name`과 `age`를 함께 받거나, 기본값을 사용하여 객체를 생성할 수 있습니다. - **코드의 가독성 향상**: 사용자가 원하는 방식으로 객체를 생성할 수 있기 때문에, 코드가 더 직관적이고 가독성이 좋습니다.
생성자가 존재하는 클래스인 LinkedList를 사용하여 Queue를 생성해서 받을 수 있습니다.
= 설계도를 생성하고 그 안에 값을 지정해 주는 생성자가 포함된 클래스를 통해 Queue를 생성
= Queue<String> queue = newLinkedList<>();
= Queue라는 설계도(인터페이스)를 바탕으로 LinkedList 메소드를 사용하여큐를 초기화하여 String 타입을 처리하는 queue큐를 생성해라
=Queue라는 설계도(건설업장의 규칙 = 먼저 온 사람이 먼저 일한다 fist in first out )를 바탕으로LinkedList 메소드(도구 = 곡괭이를 쓸지 드릴을 사용할지 [배열 기반의 Queue , 우선순위 Queue와 같은 방식들])를 사용하여큐를 초기화하여String 타입을 처리하는 queue큐를 생성해라
// Queue
// (사용하기 위해선 java.util.LinkedList; 와 import java.util.Queue; 를 추가해야합니다.)
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
// Queue 인터페이스를 구현한 LinkedList 클래스를 사용
Queue<String> queue = new LinkedList<>();
// 큐에 데이터 삽입 (enqueuing)
queue.offer("Apple");
queue.offer("Banana");
queue.offer("Cherry");
// 큐에서 데이터 꺼내기 (dequeuing)
System.out.println("First item: " + queue.poll()); // Apple
System.out.println("Second item: " + queue.poll()); // Banana
// 큐에 또 추가
queue.offer("Grapes");
// 큐에서 데이터 꺼내기
System.out.println("Third item: " + queue.poll()); // Cherry
System.out.println("Fourth item: " + queue.poll()); // Grapes
// 큐가 비었는지 확인
if (queue.isEmpty()) {
System.out.println("큐가 비었습니다.");
}
}
꺼내기 : intQueue.poll() 형태로 맨 아래 값을 꺼냅니다. (꺼내고 나면 삭제됨)
SET
순서가 없는 데이터의 집합 (데이터 중복 허용 안 함) - 순서 없고 중복 없는 배열
여기도 Queue와 같이 인터페이스로 생성자가 존재하는 클래스인 HashSet, Set, TreeSet등을 생성해서 만들 수 있다.
HashSet : 가장 빠르며 순서를 전혀 예측할 수 없음
TreeSet : 정렬된 순서대로 보관하며 정렬 방법을 지정할 수 있음
LinkedHashSet : 추가된 순서, 또는 가장 최근에 접근한 순서대로 접근 가능
즉, 보통 HashSet 을 쓰는데 순서 보장이 필요하면 LinkedHashSet 을 주로 사용한다.
// Set
// (사용하기 위해선 import java.util.Set; 와 java.util.HashSet; 를 추가해야합니다.)
import java.util.HashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<Integer> intSet = new HashSet<Integer>(); // 선언 및 생성
intSet.add(1);
intSet.add(2);
intSet.add(3);
intSet.add(3); // 중복된 값은 덮어씁니다.
intSet.add(3); // 중복된 값은 덮어씁니다.
for (Integer value : intSet) {
System.out.println(value); // 1,2,3 출력
}
// contains()
System.out.println(intSet.contains(2)); // true 출력
System.out.println(intSet.contains(4)); // false 출력
// remove()
intSet.remove(3); // 3 삭제
for (Integer value : intSet) {
System.out.println(value); // 1,2 출력
}
}
}
포함 확인 : intSet.contains({포함 확인 할 값}) 형태로 해당 값이 포함되어있는지 boolean 값으로 응답받습니다.
Map
key-value 구조로 구성된 데이터를 저장한다.
시간복잡도가 1/한번에 정보의 위치를 찾을 수 있는 자료구조형태
꼭 주소가 포함되어야 한다는건 아니다 / 근데 보통 구현하면 주소로 구현한다.
key는 사실 인덱스와 비슷한 역활을 한다. 즉 절대로 중복되서는 안된다. (주소가 중복되면??)
여기도 HashSet, TreeSet 등으로 응용하여 사용할 수 있다. 즉 여기도 인터페이스
HashMap : 중복을 허용하지 않고 순서를 보장하지 않음, 키와 값으로 null이 허용
TreeMap : key 값을 기준으로 정렬을 할 수 있습니다. 다만, 저장 시 정렬(오름차순)을 하기 때문에 저장시간이 다소 오래 걸림
// Map
// (사용하기 위해선 import java.util.Map; 를 추가해야합니다.)
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> intMap = new HashMap<>(); // 선언 및 생성
// 키 , 값
intMap.put("일", 11);
intMap.put("이", 12);
intMap.put("삼", 13);
intMap.put("삼", 14); // 중복 Key값은 덮어씁니다.
intMap.put("삼", 15); // 중복 Key값은 덮어씁니다.
// key 값 전체 출력
for (String key : intMap.keySet()) {
System.out.println(key); // 일,이,삼 출력
}
// value 값 전체 출력
for (Integer key : intMap.values()) {
System.out.println(key); // 11,12,15 출력
}
// get()
System.out.println(intMap.get("삼")); // 15 출력
}
}
ArrayList<String> list = new ArrayList<>();
list.add("apple");
list.add("banana");
list.add("cherry");
System.out.println("리스트의 크기: " + list.size()); // 출력: 리스트의 크기: 3
뭔가 많고 CS 지식을 추가로 확보해야하는 내용이었다. 추후 CS관련된 내용도 정리할 필요가 있어보인다....
오늘 요약...
import java.util.*;
public class DataStructureExample {
public static void main(String[] args) {
// 1. List 사용: 순서가 있는 데이터 저장, 중복 허용
List<String> fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Cherry");
fruits.add("Apple"); // 중복 허용
System.out.println("List (Fruits): " + fruits);
// 2. Stack 사용: LIFO 구조로 데이터 처리
Stack<String> bookStack = new Stack<>();
bookStack.push("Book 1");
bookStack.push("Book 2");
bookStack.push("Book 3");
System.out.println("Stack (Books - Last item): " + bookStack.peek());
System.out.println("Stack (Pop Book): " + bookStack.pop()); // 마지막으로 들어온 데이터 제거
System.out.println("Stack after pop: " + bookStack);
// 3. Queue 사용: FIFO 구조로 데이터 처리
Queue<String> lineQueue = new LinkedList<>();
lineQueue.offer("Person 1");
lineQueue.offer("Person 2");
lineQueue.offer("Person 3");
System.out.println("Queue (First in line): " + lineQueue.peek());
System.out.println("Queue (Remove from line): " + lineQueue.poll()); // 처음으로 들어온 데이터 제거
System.out.println("Queue after poll: " + lineQueue);
// 4. Set 사용: 중복 없는 데이터 저장
Set<String> uniqueNames = new HashSet<>();
uniqueNames.add("Alice");
uniqueNames.add("Bob");
uniqueNames.add("Alice"); // 중복 추가 시도 (저장되지 않음)
System.out.println("Set (Unique Names): " + uniqueNames);
// 5. Map 사용: 키-값 쌍으로 데이터 저장
Map<String, Integer> ageMap = new HashMap<>();
ageMap.put("Alice", 30);
ageMap.put("Bob", 25);
ageMap.put("Charlie", 35);
System.out.println("Map (Ages): " + ageMap);
System.out.println("Age of Alice: " + ageMap.get("Alice")); // 특정 키를 이용해 값 가져오기
}
}
가비지 컬렉터
자바 프로그램에서 더 이상 사용되지 않는 객체들을 자동으로 메모리에서 해제하는 기능을 담당합니다. 즉, 자바에서는 메모리 관리가 자동으로 이루어지며, 개발자가 명시적으로 메모리를 해제할 필요가 없습니다. 이는 자바의 중요한 특징 중 하나로, 메모리 누수를 방지하고 효율적인 메모리 관리를 가능하게 합니다.
1. 가비지 컬렉터의 역할
가비지 컬렉터는 메모리에서 더 이상 필요하지 않은 객체를 찾아서 자동으로 삭제합니다. 메모리에서 객체를 삭제하는 과정을 **"가비지 수집"**이라고 부릅니다.
2. 가비지 컬렉터가 작동하는 방식
가비지 컬렉터는 객체가 더 이상 참조되지 않거나 접근할 수 없는 상태일 때 그 객체를 가비지로 간주하여 수집합니다. 즉, 객체가 "reachable" 하지 않게 되면 가비지 컬렉터가 이를 회수하고 메모리를 확보합니다.
3. 참조와 가비지 컬렉터
참조(Reference): 객체를 가리키는 포인터나 주소입니다. 예를 들어, Object obj = new Object();에서 obj는 그 객체를 가리키는 참조입니다.
참조 끊김: 객체가 더 이상 참조되지 않으면, 이 객체는 가비지 컬렉터에 의해 수거될 수 있는 상태가 됩니다.
public class GarbageCollectorExample {
public static void main(String[] args) {
Object obj1 = new Object(); // obj1이 새 객체를 참조
Object obj2 = obj1; // obj2도 동일 객체를 참조
obj1 = null; // obj1 참조를 null로 설정, obj2는 여전히 객체를 참조
obj2 = null; // obj2도 null로 설정, 이제 객체는 참조되지 않음
// 이제 객체는 가비지 컬렉터가 회수할 수 있습니다.
}
}
위 코드에서 obj1과 obj2가 모두 null로 설정되면, 그 객체는 더 이상 참조되지 않으므로 가비지 컬렉터가 이를 회수합니다.
4. 가비지 컬렉션의 과정
가비지 컬렉션은 다음과 같은 주요 단계를 거칩니다:
마킹(Marking):
먼저, **활성 객체(참조되는 객체)**를 찾습니다. 이를 위해 **루트 객체(Root objects)**에서부터 시작해 모든 참조 가능한 객체를 추적합니다.
루트 객체는 스택, 레지스터, static 변수 등에서 참조되는 객체입니다.
스위핑(Sweeping):
마킹 과정에서 찾지 못한 객체들은 더 이상 사용되지 않으므로 삭제됩니다. 이 단계에서 가비지가 수집됩니다.
압축(Compaction) (일부 GC에서만 수행):
수거된 가비지 객체들이 있을 경우, 남은 객체들을 메모리의 앞쪽에 압축하여 빈 공간을 없앱니다.
이 과정은 메모리의 단편화(fragmentation) = 연속된 메모리 공간이 부족해져서 메모리를 효율적으로 활용할 수 없는 상태 문제를 해결하는 데 도움을 줍니다.
5. 자바에서의 가비지 컬렉션 종류
자바의 JVM(Java Virtual Machine)은 여러 가지 가비지 컬렉터를 지원합니다. 각 가비지 컬렉터는 서로 다른 방식으로 메모리를 관리하므로, 성능과 효율성에 차이가 있습니다.
대표적인 가비지 컬렉터 종류:
Serial GC:
단일 스레드로 작업을 처리하는 간단한 가비지 컬렉터입니다. 메모리 할당과 가비지 수집을 하나의 스레드에서 처리하므로, 멀티코어 환경에서는 효율성이 떨어질 수 있습니다.
JVM 옵션: -XX:+UseSerialGC
Parallel GC (Throughput Collector):
여러 스레드를 사용하여 가비지 수집을 병렬로 처리하는 방식입니다. 성능을 중시하며, 대용량 애플리케이션에서 유리합니다.
JVM 옵션: -XX:+UseParallelGC
CMS (Concurrent Mark-Sweep) GC:
병렬 및 동시 작업을 통해 짧은 가비지 수집 시간을 목표로 합니다. 특히, 애플리케이션의 일시적인 멈춤 시간을 최소화하려는 목적으로 사용됩니다.
JVM 옵션: -XX:+UseConcMarkSweepGC
G1 GC (Garbage First GC):
고급 가비지 컬렉터로, 애플리케이션의 예측 가능한 지연 시간을 보장하고자 설계되었습니다. 작은 단위로 메모리를 수집하고, 각 단위에 대해 우선순위를 두어 수집합니다.
JVM 옵션: -XX:+UseG1GC
ZGC (Z Garbage Collector):
Low-latency를 제공하는 새로운 가비지 컬렉터로, 애플리케이션의 일시적인 멈춤 시간을 매우 짧게 유지합니다. 큰 힙(heap) 메모리에서 높은 효율성을 보입니다.
JVM 옵션: -XX:+UseZGC
6. 가비지 컬렉터와 성능
가비지 컬렉션은 메모리 회수를 자동화하여 프로그램을 편리하게 만들지만, GC 작업이 실행 도중 애플리케이션을 멈추게 할 수 있기 때문에 성능에 영향을 미칠 수 있습니다. 이 현상을 Stop-the-world라고 합니다.
가비지 컬렉션이 자주 발생하거나 긴 시간이 걸리면, 애플리케이션의 응답성이 저하될 수 있습니다.
7. GC를 강제로 호출
자바에서는 System.gc() 메서드를 사용하여 가비지 컬렉션을 강제로 요청할 수 있습니다. 그러나 이 방법은 권장되지 않으며, JVM이 가비지 컬렉션을 최적화하여 자동으로 처리하는 것이 훨씬 효율적입니다.
System.gc(); // 가비지 컬렉션 강제 호출
8. 정리
가비지 컬렉터는 자바 프로그램의 메모리 관리를 자동으로 처리하여, 사용하지 않는 객체를 메모리에서 해제하는 역할을 합니다.
가비지 컬렉션이 어떻게 작동하는지, 그 종류와 성능에 대한 이해는 애플리케이션 성능 최적화 및 안정성 유지에 매우 중요합니다.
누가 이딴거 만들었어....
오늘의 문제...
import java.util.LinkedList;
import java.util.Queue;
class Customer {
public void purchaseTicket() {
System.out.println("Customer purchases ticket");
}
}
class RegularCustomer extends Customer {
@Override
public void purchaseTicket() {
System.out.println("Regular customer purchases ticket");
}
}
class VipCustomer extends Customer {
@Override
public void purchaseTicket() {
System.out.println("VIP customer purchases ticket with priority");
}
}
public class TicketQueue {
public static void main(String[] args) {
// Queue 생성
Queue<Customer> ticketQueue = new LinkedList<>();
// Queue에 고객 추가 (RegularCustomer와 VipCustomer)
ticketQueue.add(new RegularCustomer());
ticketQueue.add(new VipCustomer());
ticketQueue.add(new RegularCustomer());
ticketQueue.add(new VipCustomer());
// 각 고객이 차례로 티켓을 구매함
while (!ticketQueue.isEmpty()) {
Customer customer = ticketQueue.poll(); // Queue에서 다음 고객을 가져옴
customer.purchaseTicket(); // 오버라이딩된 메서드 호출
}
}
}
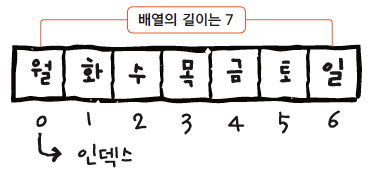
컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장 이라 정의되어 있다...
고정된 크기: 배열은 생성 시 크기가 고정되며, 데이터가 추가되거나 삭제되지 않는다.
인덱스를 통한 접근: 각 데이터는 고유한 인덱스 번호로 접근할 수 있어 효율적인 데이터 조회가 가능합니다. 자료구조
생성
위에서 설명을 했지만, 세부적인 내용은 아래와 같다.
자료구조 배열
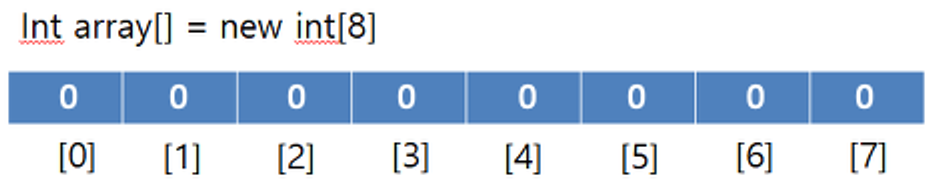
int 타입의 배열 array를 생성한다.
참조형 변수 처럼 new를 사용하여 int 정수 8개를 포함할 리스트를 생성한다.
int로 타입을 지정한 만큼, 모든 리스트 내의 변수는 0으로 초기화 되어 있다.
+ int는 0, boolean 은 false, String 은 null 값과 같은 초기값이 정해져 있다.
+ new를 쓰는 이유는, heap에 메모리를 할당하고 초기화 해달라는 명령이다.('들어갈거니 자리만들어 달라' 는 말)
// 배열 생성
//배열 생성후 초기화하면 배열의 주소가 할당된다.
int[] intArray = new int[3]; // 초기값 {0,0,0}
boolean[] boolArray = new boolean[3]; // 초기값 {false, false, false}
String[] stringArray = new String[3]; // 초기값 {"","",""}
//배열 선언만 해놓고 나중에 초기화를 시킬수도 있다.
int[] intArray2;
intArray2 = new int[3]; // 초기값 {0,0,0}
초기화
변수나 배열, 객체 등 메모리에 할당된 공간에 처음 값을 설정하는 과정을 말한다.
초기화는 변수나 데이터 구조의 값이 예측 가능한 상태에서 작업을 시작할 수 있으므로, 에러를 줄이고 코드의 안정성을 높일 수 있다는 장점이 있다.
명시적 초기화
사용자가 직접 값을 할당하여 초기화하는 방법
// 배열 초기화
import java.util.Arrays; // Arrays 클래스를 import 해주세요!
public class Main {
public static void main(String[] args) {
//1. 배열에 특정값 대입하며 선언
int[] intArray = {1, 2, 3, 4, 5};
String[] stringArray = {"a", "b", "c", "d"};
//2-1. for문을 통해 값을 대입
for (int i = 0; i < intArray.length; i++) {
intArray[i] = i;
}
//2-2. 향상된 for문을 통한 배열 출력
for (int i : intArray) {
System.out.print(i); // 01234
}
System.out.println(); // 줄바꿈
//3. 배열의 주소를 모두 같은값으로 초기화
Arrays.fill(intArray, 1);//배열의 모든 값을 1로 초기화
for (int i : intArray) {
System.out.print(i); // 11111
}
}
}
// 출력
01234
11111
묵시적 초기화
자바에서는 배열이나 객체의 멤버 변수는 자동으로 기본값으로 초기화된다. 위의 int의 0처럼 말이다.
int[] numbers = new int[5]; // int 배열의 모든 요소가 0으로 초기화됨
boolean[] flags = new boolean[3]; // boolean 배열의 모든 요소가 false로 초기화됨
생성자 초기화
객체를 생성할 때, **생성자(Constructor)**를 통해 객체의 필드를 초기화할 수 있다.
public class Person {
String name;
int age;
// 생성자를 이용한 초기화
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
Person person = new Person("홍길동", 25); // 객체 생성 시 생성자를 통한 초기화
순회
배열안에 담겨있는 변수들을 하나씩 꺼내서 사용하는 것을 순회라고 합니다.
이 순회도 정말 많은 방식이 존재한다 (부르트포스와 같은 완전탐색 부터 다양하다... 코테에서 자주 출몰한다...)
//길이가 8인 정수배열 선언
int[] intArray = new int[3];
// 배열이 초기화된 값을 출력해본다.
for(int i=0; i<intArray.length; i++) { // .length 는 배열의 길이
System.out.println(intArray[i]);
}
// 출력
0
0
0
// int[] intArray = new int[3];
// intArray = {1,2,3}
// System.out.println(intArray[1]);
// 결과 = 2
+ 추가로 .length()라는 메서드가 있는데 배열의 길이를 반환해준다. 위의 경우에 intArray.length()를 입력하면 배열 안에 변수가 3개이니 3이 입력된다.
복사
얕은 복사
참조형 변수인 배열은 heap에 실제 값이 저장되고 stack에 주소가 저장된다
얕은 복사는 = 을 사용하는 복사로, 실제 값이 저장되는 것이 아닌 주소를 공유하게 된다
깊은 복사
여기는 반대로 주소를 하나 더 생성한다
즉, 자리를 1개 더 만든 것임으로 메모리를 더 차지한다.
분명 p, q라는 2개의 변수가 생성되었지만 실제 값은 100하나만 있고 p, q가 같은 100의 주소를 들고 있다. 다만 반대의 경우 100, 90이라는 값이 heap에 저장되었고 당연히 stack도 따로 생성된다.
// 얕은 복사
int[] a = { 1, 2, 3, 4 };
int[] b = a; // 얕은 복사
b[0] = 3; // b 배열의 0번째 순번값을 3으로 수정했습니다. (1 -> 3)
System.out.println(a[0]); // 출력 3 <- a 배열의 0번째 순번값도 3으로 조회됩니다.
// 깊은 복사 메서드
// 1. clone() 메서드
int[] a = { 1, 2, 3, 4 };
int[] b = a.clone(); // 가장 간단한 방법입니다.
// 하지만, clone() 메서드는 2차원이상 배열에서는 얕은 복사로 동작합니다!!
// 깊은 복사 메서드
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
// 2. Arrays.copyOf() 메서드
int[] a = { 1, 2, 3, 4 };
int[] b = Arrays.copyOf(a, a.length); // 배열과 함께 length값도 같이 넣어줍니다.
}
}
String 배열
// 선언 후 하나씩 초기화 할 수 있습니다.
String[] stringArray = new String[3];
stringArray[0] = "val1";
stringArray[1] = "val2";
stringArray[2] = "val3";
// 선언과 동시에 초기화 할 수 있습니다.
String[] stringArray1 = new String[]{"val1", "val2", "val3"};
String[] stringArray2 = {"val1", "val2", "val3"};
위의 int와 다르게 문자열의 배열이 선언되는 String은 위 처럼 프로그래머가 각 변수를 초기화할 수 있지만, 만약 초기화를 따로 하지 않으면 각 변수에 null 값이 저장된다.
+ 간혹 null이 0인줄 아는 사람들이 있던데, null은 엄밀히 말하면 완전히 비어있는 값을 말한다
String은 불변(immutable) 객체로 한 번 생성되면 수정할 수 없습니다. 대신 새로운 String 객체를 생성합니다.
char[]는 가변이어서 배열의 각 요소를 자유롭게 변경할 수 있습니다.
메서드:
String은 문자열을 다루기 위한 다양한 메서드들이 내장되어 있습니다 (예: length(), substring(), toUpperCase(), equals() 등).
char[]는 기본 배열로만 동작하며, 문자 배열을 처리하려면 수동으로 루프를 돌거나 메서드를 작성해야 합니다.
메모리:
String은 객체로 힙 메모리에서 관리되고, 문자열 리터럴을 사용하는 경우 String Pool에 저장될 수 있습니다.
char[]는 배열이므로 힙 메모리에 저장됩니다. 배열은 메모리에서 연속적으로 공간을 차지합니다.
실제 String에는 아래와 같은 다양한 기능이 추가적으로 존재한다.
메서드
응답값 타입
설명
length()
int
문자열의 길이를 반환한다.
charAt(int index)
char
문자열에서 해당 index의 문자를 반환한다.
substring(int from, int to)
String
문자열에서 해당 범위(from~to)에 있는 문자열을 반환한다. (to는 범위에 포함되지 않음)
equals(String str)
boolean
문자열의 내용이 같은지 확인한다. 같으면 결과는 true, 다르면 false가 된다.
toCharArray()
char[]
문자열을 문자배열(char[])로 변환해서 반환한다.
new String(char[] charArr)
String
문자배열(char[]) 을 받아서 String으로 복사해서 반환한다.
// String 기능 활용하기
String str = "ABCD";
// length()
int strLength = str.length();
System.out.println(strLength); // 4 출력
// charAt(int index)
char strChar = str.charAt(2); // 순번은 0부터 시작하니까 2순번은 3번째 문자를 가리킵니다.
System.out.println(strChar); // C 출력
// substring(int from, int to)
String strSub = str.substring(0, 3); // 0~2순번까지 자르기 합니다. (3순번은 제외)
System.out.println(strSub); // ABC 출력
// equals(String str)
String newStr = "ABCD"; // str 값과 같은 문자열 생성
boolean strEqual = newStr.equals(str);
System.out.println(strEqual); // true 출력
// toCharArray()
char[] strCharArray = str.toCharArray(); // String 을 char[] 로 변환
// 반대로 char[] 를 String로 변환하는 방법
char[] charArray = {'A', 'B', 'C'};
String charArrayString = new String(charArray); // char[] 를 String 으로 변환
다차원 배열
이름만 들어도 이게 뭔가 싶은 다차원 배열은 우리가 흔히 말하는 차원 개념과 동일하다다차원 배열
Rank 1의 경우 차원(axis)가 1개임으로 1차원 배열, Rank 3의 경우 차원(axis)가 3개임으로 3차원 배열이라 부른다. 어럽게 생각할 필요 없이
1 차원은 책 1개
2차원은 앨범 여러개를 담은 책장 1개
3차원은 책장 여러개를 담은 창고 1개
라고 보면 쉽다.
선언은 간단한데, 그냥 위와 같다.
// 반복문을 통한 초기화
int[][] array = new int[2][3]; // 최초 선언
for (int i = 0; i < array.length; i++) {
for (int j = 0; j < array[i].length; j++) {
arr[i][j] = 0; // i, j 는 위 노란색 네모박스 안에있는 숫자를 의미하며 인덱스 라고 부릅니다.
}
}
// 중괄호를 사용해 초기화
int[][] array = {
{1, 2, 3},
{4, 5, 6}
};
가변 배열
Java 프로그래밍에서는 2차원 배열을 생성할 때 열의 길이를 생략하여, 행마다 다른 길이의 배열을 요소로 저장할 수 있다.
이렇게 행마다 다른 길이의 배열을 저장할 수 있는 배열을 가변 배열이라고 한다.
// 가변 배열
// 선언 및 초기화
int[][] array = new int[4][];
// 배열 원소마다 각기다른 크기로 지정 가능합니다.
array[0] = new int[3];
array[1] = new int[4];
array[2] = new int[5];
array[3] = new int[2];
// 중괄호 초기화할때도 원소배열들의 크기를 각기 다르게 생성 가능합니다.
int[][] array2 = {
{10, 20},
{10, 20, 30},
{10, 20, 30, 40},
{10, 20, 30, 40, 50},
{10, 20}
};
이보다 위의 차원은 int[][][] MultiArray = {{{1, 2}, {3, 4}}, {{5, 6}, {7, 8}}} 이런식으로 늘리면 된다. 보통 3차원까지만 사용한다.
오늘 문제
public class FindElement3DArray {
public static void main(String[] args) {
int[][][] array = new int[3][3][3];
// 배열 초기화
int value = 1;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
for (int k = 0; k < 3; k++) {
array[i][j][k] = value++;
}
}
}
// 특정 값 찾기 (예: 15)
int target = 15;
boolean found = false;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
for (int k = 0; k < 3; k++) {
if (array[i][j][k] == target) {
System.out.println("Found " + target + " at position (" + i + ", " + j + ", " + k + ")");
found = true;
break;
}
}
if (found) break;
}
if (found) break;
}
if (!found) {
System.out.println(target + " not found in the array.");
}
}
}
// 결과 : Found 15 at position (1, 1, 2)
public class FindElement3DArray { // 클래스 선언: FindElement3DArray 클래스를 정의합니다. public static void main(String[] args) { // main 메서드: 프로그램이 실행될 시작 지점입니다. int[][][] array = new int[3][3][3]; // 3x3x3 크기의 3차원 배열을 선언합니다.
// 배열 초기화 int value = 1; // 배열에 채울 값의 초기값을 1로 설정합니다. // 3차원 배열의 모든 요소를 채우는 반복문입니다. for (int i = 0; i < 3; i++) { // 첫 번째 차원 (i) 반복: 3번 반복 for (int j = 0; j < 3; j++) { // 두 번째 차원 (j) 반복: 3번 반복 for (int k = 0; k < 3; k++) { // 세 번째 차원 (k) 반복: 3번 반복 array[i][j][k] = value++; // 현재 위치에 값(value)을 넣고, 값을 증가시킵니다. } } }
// 특정 값 찾기 (예: 15) int target = 15; // 찾고자 하는 값(target)을 15로 설정합니다. boolean found = false; // 값을 찾았는지 여부를 저장할 변수입니다. 초기값은 false입니다.
// 3차원 배열을 순차적으로 탐색하는 반복문입니다. for (int i = 0; i < 3; i++) { // 첫 번째 차원 (i) 반복 for (int j = 0; j < 3; j++) { // 두 번째 차원 (j) 반복 for (int k = 0; k < 3; k++) { // 세 번째 차원 (k) 반복 if (array[i][j][k] == target) { // 현재 위치의 값이 target과 같으면 System.out.println("Found " + target + " at position (" + i + ", " + j + ", " + k + ")"); // target 값을 찾았을 때 해당 위치를 출력합니다. found = true; // 값을 찾았으므로 found를 true로 설정합니다. break; // 내부 반복문을 종료합니다. (k 반복문) } } if (found) break; // target을 찾았으면 j 반복문을 종료합니다. } if (found) break; // target을 찾았으면 i 반복문을 종료합니다. }
// 값을 찾지 못한 경우 if (!found) { // found가 여전히 false라면, target을 찾지 못한 경우입니다. System.out.println(target + " not found in the array."); // 찾지 못했다고 출력합니다. } } }
int[] numbers = {3,6,9,12,15}; for(int i = 0; i < numbers.length; i++) { // 배열에 .length 를 붙이면 길이값이 응답됩니다. System.out.println(numbers[i]); }
// 출력 3 6 9 12 15
while 문, do-while 문
for 문과 동일하게 특정 조건에 따라 연산을 반복해서 수행하고 싶을 때 사용하는 문맥입니다.
다만, 초기값 없이 조건문만 명시하여 반복합니다.
while(조건문) { (연산) } 형태로 사용합니다. (while 문)
위처럼 while 문으로 사용하면 조건문을 만족해야지만 연산이 반복 수행됩니다.
한번 반복할 때마다 조건문을 체크해서 조건문이 불만족(false) 이면 반복을 중단합니다.
do { (연산) } while(조건문) 형태로도 사용합니다. (do-while 문)
위처럼 do-while 문으로 사용하면 최초 1회 연산 수행 후 조건문을 체크하여 더 반복할지 결정합니다.
반복하게 된다면 그 이후에는 한번 반복할 때마다 조건문을 체크해서 조건문이 불만족(false) 이면 반복을 중단합니다.
break 명령
break; 명령을 호출하면 가장 가까운 블럭의 for 문 또는 while 문을 중단합니다. (또는 switch)
반복문 안에서 break; 형태로 사용합니다.
continue 명령
for 문 또는 while 문에서 해당 순서를 패스하고 싶을 때 continue 명령을 사용합니다.
반복문 안에서 continue; 형태로 사용합니다.
public class LoopExample {
public static void main(String[] args) {
int num = 1;
// while 문을 사용하여 1부터 10까지의 숫자 출력
while (num <= 10) {
if (num % 2 == 0) {
// 짝수일 경우 continue로 건너뜁니다. (아래의 println~num++까지 전부 스킵)
num++;
continue;
}
System.out.println("while loop, num = " + num);
if (num == 7) {
// num이 7일 때 반복 종료
break;
}
num++;
}
System.out.println("End of while loop");
// do-while 문을 사용하여 최소 1회 실행 후 조건 확인
int doNum = 10;
do {
System.out.println("do-while loop, doNum = " + doNum);
doNum--;
} while (doNum > 5);
System.out.println("End of do-while loop");
}
}
// 결과
// while loop, num = 1
// while loop, num = 3
// while loop, num = 5
// while loop, num = 7
// End of while loop
// do-while loop, doNum = 10
// do-while loop, doNum = 9
// do-while loop, doNum = 8
// do-while loop, doNum = 7
// do-while loop, doNum = 6
// End of do-while loop
이해를 돕기 위해 설명하면,
while 루프 부분:
num이 1일 때 출력한 후 num++를 통해 num이 2가 됩니다.
num이 2일 때는 num++실행 후 (num=3) continue가 실행되어 건너뛰고 다음 반복으로 넘어갑니다.
num이 3이되고 println을 만나 'num = 3'이 입력됩니다.
위의 3과정이 반복됩니다.
이 과정이 반복되어 num이 7일 때 break로 인해 while 루프가 종료됩니다.
do-while 루프 부분:
doNum이 10일 때 최초 출력하고, 이후 doNum--를 통해 9, 8, 7, 6으로 감소하면서 반복됩니다.
doNum이 5보다 작아지면 조건에 따라 do-while 루프가 종료됩니다.
이를 실제로 응용하면 아래와 같이 돌아간다
// 선택적 구구단 생성기
Scanner sc = new Scanner(System.in);
int passNum = sc.nextInt(); // 출력제외할 구구단수 값
for (int i = 2; i <= 9; i++) {
if (i == passNum) {
continue;
}
for (int j = 2; j <= 9; j++) {
System.out.println(i + "곱하기" + j + "는" + (i * j) + "입니다.");
}
}
// 입력
2
// 출력 - 입력값인 2단은 건너띄고 구구단 출력
3곱하기2는6입니다.
3곱하기3는9입니다.
3곱하기4는12입니다.
... 중략 ...
9곱하기8는72입니다.
9곱하기9는81입니다.
간단히 프로그램은 인간이 하는 말을 단조로운 언어로 번역해 기기에게 설명해 주는 것이라 말할 수 있다. 즉 프로그램이란 현실이나 이상을 구현하는 작업임으로, 그 체계는 인간의 언어를 기반으로 한다.
흔히 일상 생활에서 '~하면 ~하지' 와 같은 만약의 의미를 담는 조건문을 사용하는 경우가 많다. 어찌 보면 하나의 템플릿 처럼 사용될 정도로 자주 사용하는 문장인 만큼 프로그램에도 이 조건문을 정의해 두었다.
if(조건)
특정 조건에 따라 다른 연산을 수행하고 싶을 때 사용하는 문맥입니다.
기본적인 조건에 따른 연산을 수행하기 위해 if(조건) { 연산 } 형태로 사용합니다.
if의 소괄호() 안의 조건이 boolean 값 true를 만족하면 중괄호 {} 안의 연산을 수행합니다.
if(조건)-else if(조건)
if문 조건이 거짓일 경우에 다시 한번 다른 조건으로 체크해서 참일 경우에 연산을 수행하기 위해 else if(조건) { 연산 } 형태로 사용합니다.
else if의 소괄호() 안의 조건이 boolean 값 true를 만족하면 else if의 중괄호 {} 안의 연산을 수행합니다.
if(조건)-else
if문 조건이 거짓일 경우에 따른 연산을 수행하기 위해 else { 연산 } 형태로 사용합니다.
if의 소괄호() 안의 조건이 boolean 값 false를 만족하면 else의 중괄호 {} 안의 연산을 수행합니다
// 조건문으로 가위바위보 만들기
import java.util.Objects;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("A 입력 : ");
String aHand = sc.nextLine(); // A 입력
System.out.print("B 입력 : ");
String bHand = sc.nextLine(); // B 입력
if (Objects.equals(aHand, "가위")) { // 값을 비교하는 Obects.equals() 메서드 사용
if (Objects.equals(bHand, "가위")) {
System.out.println("A 와 B 는 비겼습니다."); // A 와 B 의 입력값을 비교해서 결과 출력
} else if (Objects.equals(bHand, "바위")) {
System.out.println("B 가 이겼습니다.");
} else if (Objects.equals(bHand, "보")) {
System.out.println("A 가 이겼습니다.");
} else {
System.out.println(" B 유저 값을 잘못 입력하셨습니다.");
}
} else if (Objects.equals(aHand, "바위")) {
if (Objects.equals(bHand, "가위")) {
System.out.println("A 가 이겼습니다.");
} else if (Objects.equals(bHand, "바위")) {
System.out.println("A 와 B 는 비겼습니다.");
} else if (Objects.equals(bHand, "보")) {
System.out.println("B 가 이겼습니다.");
}
} else if (Objects.equals(aHand, "보")) {
if (Objects.equals(bHand, "가위")) {
System.out.println("B 가 이겼습니다.");
} else if (Objects.equals(bHand, "바위")) {
System.out.println("A 가 이겼습니다.");
} else if (Objects.equals(bHand, "보")) {
System.out.println("A 와 B 는 비겼습니다.");
}
}
}
}
// 입/출력 예시
// A 입력 : 가위
// B 입력 : 보
// A 가 이겼습니다.
if = ~하면 ~하지 = 조건문
else = 만약에 그게 아니면 ~하자 = 조건외
else = 만약에 ~가 아니면 ~이지 않을까? = 꼬리 물기 조건
그런데 이거 너무 긴거 아닐까? 라는 생각이 든다. 현실에서도 조건에 부차적인 조건이 붙는 경우는 많다. "꽃 10송이 사와, 10송이 없으면 5송이만 사와" 이런 것처럼 말이다. 이를 좀 더 간결하게 사용하기 위해 만들어진 메소드가 switch이다.
switch
여러 경우의 수 중 하나를 선택해야 할 때 사용하는 제어문입니다.
switch(피연산자) { case(조건): (연산) } 이러한 형태로 많이 쓰입니다.
switch 피연산자가 case 조건을 만족하면 case: 뒤에 명시되어 있는 연산을 수행합니다.
case(조건): (연산) 은 여러 개를 설정할 수 있습니다.
🔎 각 case의 연산문 마지막에는 break;를 꼭 넣어줘야 합니다!!
break; 문은 해당 case의 연산문이 끝났다는 것을 알려주어 switch 문을 종료시켜줍니다.
즉 break가 없으면, switch의 모든 조건을 다 한번씩 실행해본다.
switch문 중괄호 안의 제일 마지막에 default: (연산) 을 명시해 주어 case 조건들이 모두 만족하지 않을 때 수행할 연산을 정해주어야 합니다.
default: (연산) 은 아무것도 만족하지 않을 때 수행하는 것이라, 없다면 생략해도 됩니다.
// if vs switch
// switch 문 실습코드를 if 문으로 바꿔보겠습니다.
// switch
int month = 8;
String monthString = "";
switch (month) {
case 1: monthString = "1월";
break;
case 2: monthString = "2월";
break;
case 3: monthString = "3월";
break;
case 4: monthString = "4월";
break;
case 5: monthString = "5월";
break;
case 6: monthString = "6월";
break;
case 7: monthString = "7월";
break;
case 8: monthString = "8월";
break;
case 9: monthString = "9월";
break;
case 10: monthString = "10월";
break;
case 11: monthString = "11월";
break;
case 12: monthString = "12월";
break;
default: monthString = "알수 없음";
}
System.out.println(monthString); // 8월 출력
// if 로 변환
if (month == 1) {
monthString = "1월";
} else if (month == 2) {
monthString = "2월";
} else if (month == 3) {
monthString = "3월";
} else if (month == 4) {
monthString = "4월";
} else if (month == 5) {
monthString = "5월";
} else if (month == 6) {
monthString = "6월";
} else if (month == 7) {
monthString = "7월";
} else if (month == 8) {
monthString = "8월";
} else if (month == 9) {
monthString = "9월";
} else if (month == 10) {
monthString = "10월";
} else if (month == 11) {
monthString = "11월";
} else if (month == 12) {
monthString = "12월";
} else {
monthString = "알수 없음";
}
System.out.println(monthString); // 8월 출력
그렇다고 모든 상황에서 if보다 switch가 좋은 것은 아니다.
switch는 각 조건에 추가 꼬리 조건이 달릴 수 없지만 if는 가능하다.
if (Objects.equals(aHand, "가위")) { // 값을 비교하는 Obects.equals() 메서드 사용
if (Objects.equals(bHand, "가위")) {
System.out.println("A 와 B 는 비겼습니다."); // A 와 B 의 입력값을 비교해서 결과 출력
}
switch (month) {
case 1: monthString = "1월";
break;
case 2: monthString = "2월";
break;
case 3: monthString = "3월";
default: monthString = "알수 없음";
}
보면 if는 조건에 조건을 추가할 수 있지만, switch는 조건마다 1개의 조건만 추가할 수 있다.
&& (AND = 피연산자 모두 참), ||(OR = 피연산자 둘 중 하나라도 참), !(피연산자의 반대 boolean 값)
대입 연산자
변수를 바로 연산해서 그 자리에서 저장하는 연산자
// 대입 연산자
int number = 10;
number = number + 2;
System.out.println(number); // 12
+ 복합 대입 연산자 (+=, -=, *= …)
// 복합 대입 연산자
number = 10;
number += 2;
System.out.println(number); // 12
위 코드와 아래 코드는 실재로 같은 말이다. 다만 좀 더 짧게 코드를 짜기위해 아래와 같은 형태도 만들어졌다.
🔥 대입 연산자 중에 증감 연산자 쓸 때 주의할 점!
++ 또는 —-를 붙이면 피연산자가 1 더해지거나 1 빼기가 된다.
주의할 점은, 피연산자 뒤에 붙이냐, 앞에 붙이냐에 따라서 연산 순서가 달라진다.
연산자 연산자 위치 기능 연산 예 (num=1일 경우)
++ 변수
++{피연산자}
연산 전에 피연산자에 1 더해줍니다.
val = ++num;
num값+1 후에 val변수에 저장 = val =2
변수 ++
{피연산자}++
연산 후에 피연산자에 1 더해줍니다.
val = num++;
num값을 val변수에 저장 후 num+1 = val = 1
- - 변수
—{피연산자}
연산 전에 피연산자에 1 빼줍니다.
val = —num;
num값-1 후에 val변수에 저장 = val = 0
변수 - -
{피연산자}—
연산 후에 피연산자에 1 빼줍니다.
val = num—;
num값을 val변수에 저장 후 num-1 = val =1
이처럼 대입 연산할 때뿐만 아니라 연산을 직접 할 때도 마찬가지로 선/후 적용이 나뉜다.
연산자 우선순위 : 산술 > 비교 > 논리 > 대입
단, 괄호로 감싸주면 괄호 안의 연산이 최우선 순위로 계산
// 연산자 우선순위
int x = 2;
int y = 9;
int z = 10;
boolean result = x < y && y < z; // <,> 비교연산자 계산 후 && 논리 연산자 계산
System.out.println(result); // true
result = x + 10 < y && y < z; // +10 산술연산자 계산 후 <,> 비교연산자 계산 후 && 논리 연산자 계산
System.out.println(result); // false
result = x + 2 * 3 > y; // 산술연산자 곱센 > 덧셈 순으로 계산 후 > 비교연산자 계산
System.out.println(result); // false (8>9)
result = (x + 2) * 3 > y; // 괄호안 덧셈 연산 후 괄호 밖 곱셈 계산 후 > 비교연산자 계산
System.out.println(result); // true (12>9)
이전 글에 설명한 형변환에 관련된 내용이다. (간단한 설명으로 int는 정수만, double은 실수만을 반환할 수 있다.)
삼항 연산자
비교 연산의 결과값에 따라 응답할 값을 직접 지정할 수 있는 연산자입니다.
(조건)?(참 결과):(거짓 결과)
// 삼항 연산자
int x = 1;
int y = 9;
boolean b = (x == y) ? true : false;
System.out.println(b); // false
String s = (x != y) ? "정답" : "땡";
System.out.println(s); // 땡
int max = (x > y) ? x : y;
System.out.println(max); // 9
int min = (x < y) ? x : y;
System.out.println(min); // 1
instance of 연산자
피연산자가 조건에 명시된 클래스의 객체인지 비교하여 참/거짓을 응답해 주는 연산자
(객체명)instance of(클래스명)
class Car {}
public class TestInstanceof {
public static void main(String[] args) {
Car car = new Car();
String str = "Hello";
System.out.println(car instanceof Car); // true
System.out.println(str instanceof String); // true
System.out.println(car instanceof String); // false
}
}
car instanceof Car → true. car는 Car 클래스의 인스턴스( 객체 )이기 때문에.
피연산자의 타입이 float보다 작은 long, int, short 타입이면 float으로 변환
피연산자의 타입이 double 보다 작은 float, long, int, short 타입이면 double으로 변환
비트 연산
Byte를 8등분 한 게 Bit
Bit는 0,1 둘 중의 하나의 값만을 저장하는 컴퓨터가 저장(표현) 가능한 가장 작은 단위
컴퓨터의 가장 작은 단위인 Bit이기 때문에 연산중에서 Bit 연산이 제일 빠르다
물론 이전에 배운 대로 0,1 값으로 산술연산을 하거나, 비교 연산을 할 수 있지만 비트 연산을 통해 자릿수를 옮길 수도 있다.
이처럼 Bit의 자릿수를 옮기는 것을 비트 연산이라고 한다.
<<(왼쪽으로 자릿수옮기기), >>(오른쪽으로 자릿수옮기기)
0,1 은 2진수 값이기 때문에,
자릿수를 왼쪽으로 옮기는 횟수만큼 2의 배수로 곱셈이 연산되는 것과 동일하다.
자릿수를 오른쪽으로 옮기는 횟수만큼 2의 배수로 나눗셈이 연산되는 것과 동일하다.
// 비트 연산
// 참고, 3의 이진수값은 11(2) 입니다. 12의 이진수값은 1100(2) 입니다.
// (2) 표기는 이 숫자가 이진수값이라는 표식 입니다.
System.out.println(3 << 2);
// 3의 이진수값인 11(2) 에서 왼쪽으로 2번 옮겨져서 1100(2) 인 12값이 됩니다.
System.out.println(3 >> 1);
// 3의 이진수값인 11(2) 에서 오른쪽으로 1번 옮겨져서 1(2) 인 1 값이 됩니다.
프로그래밍에서 변수는 데이터를 저장하는 "이름이 있는 저장 공간"이다. 프로그램 실행 중에 특정 값을 저장하고, 필요할 때마다 그 값을 쉽게 불러오거나 변경할 수 있다.(상수는 변수와 비슷하지만 값이 변경이 안된다는 특징이 있다.)
int number; // number 라는 이름의 int(숫자)타입의 저장공간을 선언
String name; // name 이라는 이름의 String(문자열)타입의 저장공간을 선언
위의 상자 예시를 기준으로
int는 상자의 종류(골판지인지 플라스틱인지)
number는 상자 앞에있는 myNum처럼 닉네임
10은 상자에 저장할 값이다.
final int number = 10; // 1. 상수로 선언 (데이터 타입 앞에 final 을 붙이면 됩니다.)
+ 상수는 위와 같이 선언하면 된다.
변수는 크게 3가지의 형태가 존재한다.
기본형 변수
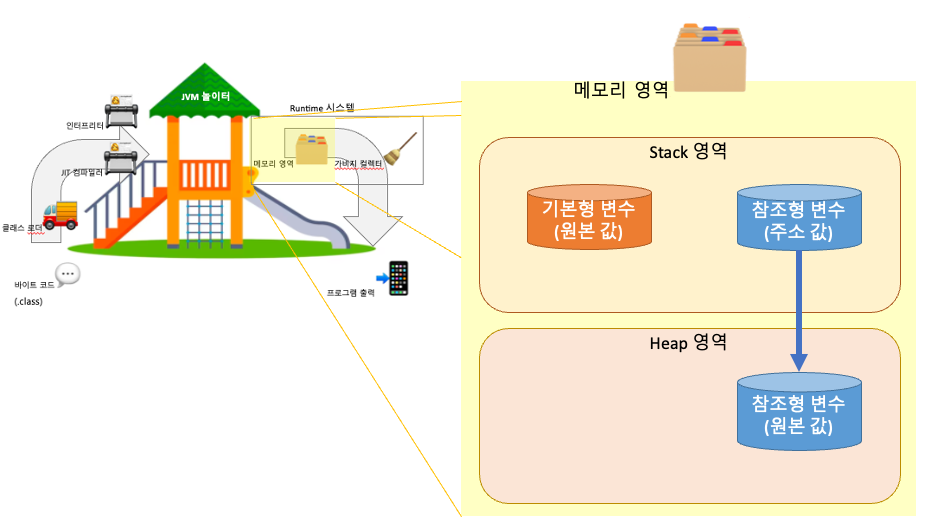
기본형 변수는 실제 데이터 값을 직접 저장하는 간단한 형태의 변수 (여긴 stack 자체에 값이 저장된다.) [ int, char, boolean ]
참조형 변수
참조형 변수는 데이터가 저장된 메모리 주소를 참조 (여긴 stack에 주소, heap에 값이 저장된다.) [ String, ArrayList, MyClass ]
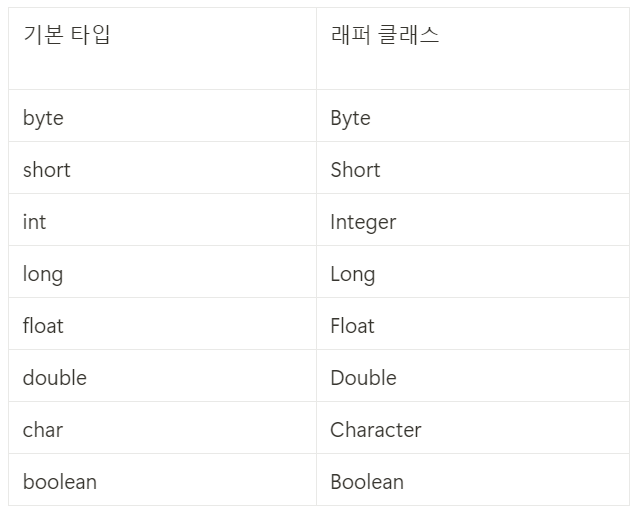
래퍼 클래스 변수
기본형 변수를 객체로 다룰 수 있도록 감싸주는 클래스
+ 알아두면 좋은 상식 : 기본형 변수는 소문자로 참조형은 대문자로 시작한다
1. 기본형 변수 (Primitive Type) 기본형 변수는 실제 데이터 값을 직접 저장하는 간단한 형태의 변수입니다. Java에서는 8가지 기본형이 있으며, 대표적인 예시는 아래와 같습니다.
#### 논리형 (boolean) - **`boolean`**: 참(true) 또는 거짓(false)만 저장할 수 있습니다.
boolean flag = true;
#### 문자형 (char) - **`char`**: 하나의 문자만 저장합니다. 작은 따옴표('')로 문자를 감싸서 사용합니다.
char alphabet = 'A';
문자 (char)
문자 뒤에 \0(널문자)가 없습니다. (1 byte만 쓰기 때문에 끝을 알아서 데이터만 저장하면 됩니다.)
문자열 (String)
문장의 끝에 \0(널문자=빈공간)가 함께 저장이 됩니다. (몇 개의 byte를 쓸지 모르기 때문에 끝을 표시해야 합니다.)
#### 정수형 (byte, short, int, long) - **정수형**은 정수를 저장하며, 사용할 범위에 따라 다양한 타입을 제공합니다. - **`byte`**: -128 ~ 127 - **`short`**: -32,768 ~ 32,767 - **`int`**: -2,147,483,648 ~ 2,147,483,647 - **`long`**: 매우 큰 수 범위, 숫자 뒤에 **`L`**을 붙여 표기
int number = 2147483647;
long largeNumber = 9223372036854775807L;
#### 실수형 (float, double) - **실수형**은 소수점을 가진 실숫값을 저장합니다. 사용 범위에 따라 `float`와 `double`로 나뉩니다. - **`float`**: 소수점 이하 약 7자리까지 저장 가능, 숫자 뒤에 **`f`**를 붙여 표기 - **`double`**: 소수점 이하 약 16자리까지 저장 가능
2. 참조형 변수 (Reference Type) 참조형 변수는 데이터가 저장된 메모리 주소를 참조합니다. 참조형 변수의 주요 종류는 다음과 같습니다.
= 기본형 변수와 다르게 상자에 물건을 직접 담는게 아니라 물건이 있는 주소를 상자에 넣는다는 것이다.
기본형 변수 : 원본 값이 Stack 영역에 있다.
참조형 변수 : 원본 값이 Heap 영역에 있다.
Stack 영역에는 따로 저장 해둔 원본 값의 Heap 영역 주소를 저장합니다.
주소값(객체 위치, 변수 위치)을 저장하는 변수
#### 문자열 (String) - **`String`**: 여러 문자를 조합한 문자열을 저장합니다. 큰 따옴표("")로 감싸서 사용합니다.
String message = "Hello World";
= String은 message라는 상자에 "Hello World"를 넣는 것이 아닌 Hello World가 저장된 주소를 저장한다.
"Hello World"라는 문자열이 메모리의 힙 영역에 저장됩니다.
변수 message는 스택 영역에 저장되고, 이 변수는 "Hello World"가 있는 메모리 위치를 참조(가리키는)합니다.
이렇게 message 변수를 사용하면 "Hello World"가 있는 위치로 접근할 수 있게 됩니다.
#### 객체, 배열, 리스트 (Object, Array, List 등) - 다양한 형태의 데이터나 객체들을 저장하는 변수 타입입니다.
int[] numbers = {1, 2, 3}; // 배열 예시
---
3. 래퍼 클래스 변수 (Wrapper Class) 기본형 변수를 객체로 다룰 수 있도록 감싸주는 클래스입니다. 예를 들어, `int` 기본형 변수는 `Integer` 래퍼 클래스로 사용할 수 있습니다. Java의 객체지향 기능을 활용할 때 유용합니다.
// 박싱 VS 언박싱
// 박싱
// Integer 래퍼 클래스 num 에 21 의 값을 저장
int number = 21;
Integer num = new Integet(number);
// 언박싱
int n = num.intValue(); // 래퍼 클래스들은 inValue() 같은 언박싱 메서드들을 제공해줍니다.
박싱 VS 언박싱
기본 타입에서 래퍼 클래스 변수로 변수를 감싸는 것을 “박싱”이라고 부르며
래퍼 클래스 변수를 기본 타입 변수로 가져오는 것을 “언박싱”이라고 부릅니다.
래퍼 클래스 변수
변수형 변환
형변환에 대한 이해
Java 프로그래밍을 하다 보면 문자열로 입력받은 변수를 숫자로 변환해서 계산을 하고 싶은 경우, 문자열에 숫자 값을 추가하고 싶은 경우 등… 어떤 변수형을 다른 형으로 변환이 필요한 경우가 많습니다.
형변환은 주로 기본형 변수인 정수 ↔ 실수 ↔ 문자 들 사이에서 일어나며 방법은 아래와 같습니다.
정수형, 실수형 간 발생하는 형변환
Double, Float to Int
(Int) 캐스팅 방식으로 실수를 정수로 치환하는 방법입니다.
이때 실수형의 소수점 아래 자리는 버려집니다.
double doubleNumber = 10.101010;
float floatNumber = 10.1010
int intNumber;
intNumber = (int)doubleNumber; // double -> int 형변환
intNumber = (int)floatNumber; // float -> int 형변환
Int to Double, Float
(Double, Float) 캐스팅으로 정수형을 실수형으로 변환하는 방법입니다.
int intNumber = 10;
double doubleNumber = (double)intNumber; // int -> double 형변환
float floatNumber = (float)intNumber; // int -> float 형변환
자동 형변환
Java 프로그래밍에서 형변환을 직접적으로 캐스팅하지 않아도 자동으로 형변환 되는 케이스가 있습니다.
프로그램 실행 도중에 값을 저장하거나 계산할 때 자동으로 타입 변환이 일어납니다.
1) 자동 타입 변환은 작은 크기의 타입에서 큰 크기의 타입으로 저장될 때 큰 크기로 형변환이 발생합니다.
IntelliJ는 JetBrains에서 개발한 강력한 통합 개발 환경(IDE)으로, 특히 **Java 개발**에 최적화되어 있지만, 다양한 프로그래밍 언어와 프레임워크를 지원한다. IntelliJ IDEA(이하 IntelliJ)는 코드 작성부터 디버깅, 테스트, 배포까지 개발 과정 전반에 걸쳐 다양한 기능을 제공하여, 개발 생산성을 높이는 데 큰 도움을 준다.
말이 어려워 보이지만, 프로그램이라는 그림을 그리기 위해 필요한 그림판이라고 보면된다. 다만 여러가지 유용한 기능이 있어 그림판 보다는 태블릿에 가깝다고 생각하면 좋다.
과거에는 이클립스라는 프로그램이 많이 사용되었지만 다양한 편의성과 기능으로 현재는 대부분의 웹 개발자가 IntelliJ를 사용하고 있다.
Java 프로그램(앱)의 시작점!
Java 앱은 실행되면 제일 먼저 클래스의 main 메서드를 실행시키는 게 JVM의 약속이다.
단순히 main이라는 박스를 만들어서 이제부터 이 박스안에 원하는 프로그램을 만들거다 라는 것
public class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
### 클래스 정의 - **`public class Main { }`** - `public`: 다른 곳에서도 사용할 수 있도록 클래스 접근을 허용하는 접근 제어자.
- 접근 제어자 : 클래스, 메서드, 변수 등 특정 코드 요소에 대한 접근 권한 - `class`: 객체(데이터와 기능의 묶음)를 만들기 위한 선언. - `Main`: 클래스 이름. Java에서는 파일명과 같아야 함. 컴파일 후 `.class` 파일을 생성할 때 이름을 맞춰주기 위해 필요.
### 메인 메서드 정의 - **`public static void main(String[] args)`** - `public`: 다른 곳에서 이 메서드를 실행할 수 있게 함. - `static`: 프로그램 시작 시 한 번만 실행되는 메서드. 다른 `static` 메서드나 변수만 호출 가능. - `void`: 메서드가 값을 반환하지 않음을 의미. - `main`: 프로그램 시작점이 되는 메서드. Java 프로그램은 항상 `main` 메서드부터 시작.
### 메서드 매개변수 - **`(String[] args)`** - `String[]`: 문자열들의 배열, 즉 여러 개의 문자열을 저장할 수 있는 데이터 타입. - `args`: 배열의 이름으로 사용자가 지정할 수 있음.
가장 많이 쓰는 메서드 System.out.print()
System.out.print("데이터1"); // "데이터1" 라는 문자를 출력
System.out.print("데이터2"); // 이어서 "데이터2" 라는 문자를 출력
// 실행 결과
데이터1데이터2
System.out.print()메서드를 사용하면 출력창에 괄호() 안으로 전달된 데이터를 출력해 준다.
줄바꿈 추가 메서드 System.out.println()
System.out.print(7);
System.out.println(3);
System.out.println(3.14);
System.out.println("JAVA");
// 실행 결과
7
3
3.14
JAVA
System.out.print() 메서드를 사용하면 출력창에 괄호() 안으로 전달된 데이터를 줄바꿈 하면서 출력해 준다.