@Repository
public interface ExampleRepository extends JpaRepository<ExampleEntity, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT e FROM ExampleEntity e WHERE e.id = :id")
ExampleEntity findByIdWithLock(@Param("id") Long id);
}
동시에 여러 노드(서버)가 공유 자원에 접근하려는 상황에서 데이터의 무결성과 일관성을 보장.
2. 특징
멀티 노드 환경:
여러 노드가 동일한 자원에 접근 가능.
분산 락을 통해 자원을 독점적으로 사용할 노드를 제어.
데이터 일관성 보장:
데이터의 충돌 방지 및 무결성 유지.
중앙 관리:
락 상태를 중앙에서 관리하거나 분산 환경에서 합의 프로토콜을 사용.
3. 동작 원리
락 생성:
특정 자원에 대해 락 생성 요청.
락이 성공하면 해당 노드는 자원을 독점적으로 사용 가능.
락 유지:
락을 일정 시간 동안 유지.
필요 시 갱신(Renewal) 가능.
락 해제:
자원 사용이 끝나면 락을 해제.
타임아웃으로 자동 해제될 수도 있음.
4. 분산 락 구현 방식
4.1 데이터베이스 기반
방법: 데이터베이스 테이블에 락 상태를 저장.
SQL 예제:
-- 락 생성
INSERT INTO distributed_lock (resource, lock_time) VALUES ('RESOURCE_ID', NOW());
-- 락 확인
SELECT * FROM distributed_lock WHERE resource = 'RESOURCE_ID';
-- 락 해제
DELETE FROM distributed_lock WHERE resource = 'RESOURCE_ID';
장점:
별도 도구 없이 쉽게 구현 가능.
트랜잭션과 연동하여 락 관리.
단점:
성능 저하(데이터베이스 부하 증가).
대규모 시스템에서는 비효율적.
4.2 Redis 기반
방법: Redis의 SETNX 명령어를 사용하여 락 생성.
예제:
# 락 생성
SET resource:lock "LOCKED" NX PX 10000
# 락 확인
GET resource:lock
# 락 해제
DEL resource:lock
장점:
빠른 속도.
TTL(Time-To-Live) 설정으로 자동 해제 가능.
단점:
단일 노드 Redis 사용 시 SPOF(Single Point of Failure) 발생 가능.
클러스터 환경에서는 Redlock 알고리즘 필요.
4.3 ZooKeeper 기반
방법: 분산 락의 상태를 ZNode에 저장하여 관리.
예제:
# ZNode 생성 (락 획득)
create /locks/resource
# 락 해제
delete /locks/resource
장점:
강력한 일관성 보장.
분산 환경에 최적화.
단점:
설정 및 관리 복잡.
ZooKeeper 설치 필요.
5. Redlock 알고리즘 (Redis 기반 분산 락)
Redis 클러스터 환경에서 락의 일관성을 보장하는 알고리즘.
여러 Redis 노드에 동일한 키로 락 생성 요청.
과반수 이상의 노드에서 락 성공 시 락 획득.
TTL을 설정하여 자동으로 락이 해제되도록 설정.
락 해제 시 모든 노드에서 락 해제.
6. 장단점
장점
단점
데이터 충돌 및 중복 작업 방지.
락 구현 및 관리 복잡도 증가.
고성능 분산 환경에서 데이터 무결성 보장.
락 생성/해제 시 네트워크 지연으로 인한 성능 저하 가능.
다양한 도구를 활용한 구현 가능(데이터베이스, Redis, ZooKeeper 등).
잘못된 락 설정 시 데드락 발생 가능.
7. 분산 락 사용 사례
동시에 한 번만 실행해야 하는 작업:
예: 배치 처리, 데이터 마이그레이션.
중복 실행 방지:
예: 주문 처리, 결제 처리.
리소스 공유:
예: 파일 업로드/다운로드, 재고 관리.
8. 학습하면 좋은 추가 주제
락 컨텐츠 관리 전략:
TTL 설정, 자동 해제 로직 구현.
ZooKeeper와 Redis의 비교:
각 기술의 장단점 및 사용 사례 분석.
분산 시스템에서의 일관성 모델:
강한 일관성, 최종적 일관성(Final Consistency) 개념 이해.
Redlock 알고리즘 심화:
클러스터 환경에서의 락 일관성 보장 방법.
격리 수준
트랜잭션 격리 수준 (Transaction Isolation Levels)
1. 트랜잭션 격리 수준이란?
트랜잭션 간의 상호작용에서 발생할 수 있는 데이터 충돌 문제를 방지하기 위해 데이터베이스가 제공하는 동시성 제어 메커니즘.
각 격리 수준은 데이터 일관성과 동시성 성능 간의 트레이드오프를 제공.
2. 주요 격리 수준과 특징
격리 수준
Dirty Read
Non-Repeatable Read
Phantom Read
특징
READ UNCOMMITTED
허용
허용
허용
- 커밋되지 않은 데이터를 읽을 수 있음(Dirty Read). - 가장 낮은 격리 수준으로 동시성 성능은 높지만 데이터 일관성이 낮음.
READ COMMITTED
방지
허용
허용
- 커밋된 데이터만 읽을 수 있음. - Oracle, SQL Server의 기본 격리 수준. - Non-Repeatable Read 가능.
REPEATABLE READ
방지
방지
허용
- 동일 트랜잭션 내에서 항상 같은 데이터 읽기 보장. - MySQL(InnoDB)의 기본 격리 수준.
SERIALIZABLE
방지
방지
방지
- 모든 트랜잭션을 순차적으로 실행하는 것처럼 동작. - 가장 높은 격리 수준으로, 동시성 성능이 낮지만 데이터 일관성 보장.
3. 주요 개념
Dirty Read:
다른 트랜잭션이 아직 커밋되지 않은 변경 사항을 읽는 것.
예시: A 트랜잭션이 데이터를 수정하고 커밋하지 않은 상태에서 B 트랜잭션이 수정된 데이터를 읽음.
Non-Repeatable Read:
한 트랜잭션에서 같은 데이터를 두 번 읽었을 때, 값이 달라지는 현상.
원인: 다른 트랜잭션에서 데이터를 수정하고 커밋한 경우.
Phantom Read:
한 트랜잭션에서 동일한 조건으로 데이터를 조회했을 때, 새로운 데이터가 추가되거나 삭제되는 현상.
원인: 다른 트랜잭션에서 데이터를 추가/삭제한 경우.
4. 격리 수준별 예제
4.1 READ UNCOMMITTED
-- A 트랜잭션
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- B 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- Dirty Read 발생
4.2 READ COMMITTED
-- A 트랜잭션
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- B 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- 커밋되지 않았으므로 읽을 수 없음
4.3 REPEATABLE READ
-- A 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- 1000
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- B 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- A 트랜잭션의 변경 사항 보이지 않음
4.4 SERIALIZABLE
-- A 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1;
-- B 트랜잭션
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- 대기 상태 (A 트랜잭션 종료 후 실행)
Java Persistence API: 자바 애플리케이션과 데이터베이스 간 매핑 및 상호작용을 위한 표준 인터페이스.
주요 역할:
자바 객체와 데이터베이스 테이블 간 자동 매핑.
SQL 작성 없이 객체 중심으로 데이터 처리.
2. JPA를 사용하는 이유
이유 설명
SQL 대신 자바 코드로 작업
복잡한 SQL 대신 간단한 자바 코드로 데이터 저장 및 조회 가능.
객체 지향적 데이터 처리
데이터베이스 테이블을 객체로 변환하여 컬렉션처럼 다룰 수 있음.
유지보수성 향상
데이터베이스 구조 변경 시 엔티티 수정만으로 코드 유지보수 가능.
데이터베이스 독립성
특정 데이터베이스(MySQL, Oracle 등)에 종속되지 않음.
비즈니스 로직에 집중 가능
CRUD 작업 자동화로 반복적인 SQL 작업 제거.
3. JPA에서의 연관관계
연관관계 설명 예제
1 : 1
한 테이블의 행이 다른 테이블의 하나의 행과만 연결됨.
사용자(User) ↔ 사용자 상세(UserDetail)
1 : N
한 테이블의 행이 다른 테이블의 여러 행과 연결됨.
회원(Member) ↔ 주문(Order)
N : M
한 테이블의 여러 행이 다른 테이블의 여러 행과 연결됨.
학생(Student) ↔ 강의(Course) (중간 테이블 필요)
4. Fetch Type (로딩 전략)
Fetch Type 특징 기본값
Lazy
연관 데이터를 실제로 사용하는 시점에 조회.
@OneToMany, @ManyToMany
Eager
엔티티 조회 시 연관 데이터를 즉시 조회.
@ManyToOne, @OneToOne
5. JPA 코드 예제
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY) // Lazy 로딩
private List<Order> orders = new ArrayList<>();
}
@Entity
@Getter
@Setter
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String product;
@ManyToOne(fetch = FetchType.EAGER) // Eager 로딩
@JoinColumn(name = "member_id")
private Member member;
}
요약
JPA의 정의
자바 애플리케이션과 데이터베이스 간 매핑 및 상호작용을 위한 표준 인터페이스.
사용 이유
SQL 없이 자바 코드로 데이터 처리, 유지보수 용이, 데이터베이스 독립성 보장.
연관관계
1:1, 1:N, N:M 관계를 객체로 매핑 가능.
Fetch Type
연관 데이터 로딩 시점을 제어하는 전략. Lazy(지연 로딩), Eager(즉시 로딩).
장점
코드 간결화: 객체 중심 개발로 SQL 관리 부담 감소.
생산성 향상: 반복 작업 제거로 개발 속도 증가.
데이터베이스 독립성: 특정 DBMS에 종속되지 않음.
N + 1 문제란 무엇인가
1. N + 1 문제란?
정의:
데이터베이스에서 부모-자식 관계 데이터를 가져올 때, 비효율적으로 많은 쿼리가 실행되는 문제.
주로 지연 로딩(FetchType.LAZY)을 사용하는 상황에서 발생.
N + 1의 의미:
1: 부모 데이터를 조회하는 1개의 쿼리.
N: 부모마다 자식 데이터를 조회하기 위한 N개의 쿼리.
2. N + 1 문제 예시
상황 설명
데이터베이스에 부모 테이블(Parent)과 자식 테이블(Child)이 있고, 한 부모는 여러 자식을 가질 수 있음.
목표: 모든 부모와 관련된 자식 데이터를 조회.
테이블 구조
Parent 테이블
id
name
1
엄마
2
아빠
Child 테이블
id
parent_id
name
1
1
딸
2
1
아들
3
2
막내딸
1. 기본 쿼리 흐름
-- 부모 데이터를 조회 (1번 실행)
SELECT * FROM parent;
-- 부모 각각에 대해 자식 데이터를 조회 (N번 실행)
SELECT * FROM child WHERE parent_id = 1;
SELECT * FROM child WHERE parent_id = 2;
2. 실행 결과
부모가 100명이라면:
1번 부모 조회 쿼리 실행.
100번 자식 조회 쿼리 실행.
총 101번의 쿼리 실행.
3. N + 1 문제 확인 방법
Spring Boot에서 SQL 로그 활성화
spring:
jpa:
properties:
hibernate:
show_sql: true # 실행 쿼리 표시
format_sql: true # 쿼리 포맷팅
SQL 로그 예시
-- 부모 조회
SELECT * FROM parent;
-- 부모별 자식 데이터 조회
SELECT * FROM child WHERE parent_id = 1;
SELECT * FROM child WHERE parent_id = 2;
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent", fetch = FetchType.EAGER) // 즉시 로딩 설정
private List<Child> children;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
// 실행
List<Parent> parents = parentRepository.findAll(); // 부모와 자식을 함께 로드
실행 쿼리
SELECT p.*, c.*
FROM parent p
LEFT JOIN child c
ON p.id = c.parent_id; -- 부모와 자식 데이터를 한 번의 쿼리로 로드
2. 지연 로딩 (Lazy Loading)
정의:
엔티티를 조회할 때 연관된 엔티티를 필요한 시점에 조회하는 로딩 방식.
데이터를 사용할 때 별도의 쿼리가 실행되어 로드됨.
특징:
FetchType.LAZY를 설정하면 지연 로딩이 적용됨.
부모 엔티티를 조회할 때 자식 엔티티는 바로 로드되지 않고, Proxy 객체로 대체.
자식 데이터가 실제로 필요할 때 데이터베이스 쿼리가 실행.
장점:
필요한 데이터만 로드하므로 메모리 사용량 감소.
연관 데이터가 많거나 사용 빈도가 낮은 경우 성능 최적화 가능.
단점:
데이터가 필요할 때마다 추가적인 쿼리 발생.
여러 연관 데이터가 필요한 경우 N+1 문제가 발생할 수 있음.
지연 로딩 예제
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY) // 지연 로딩 설정
private List<Child> children;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
// 실행
List<Parent> parents = parentRepository.findAll(); // 부모만 로드
for (Parent parent : parents) {
System.out.println(parent.getChildren()); // 자식 데이터를 사용할 때 쿼리 실행
}
실행 쿼리
부모 조회:
SELECT * FROM parent;
자식 조회 (사용 시):
SELECT * FROM child WHERE parent_id = 1;
SELECT * FROM child WHERE parent_id = 2;
3. 즉시 로딩 vs 지연 로딩 비교
즉시 로딩 (Eager Loading)
지연 로딩 (Lazy Loading)
데이터 로드 시점
부모 엔티티를 조회할 때, 연관 데이터도 함께 로드.
연관 데이터는 실제로 접근할 때 로드.
쿼리 실행 방식
부모와 자식을 JOIN 쿼리로 한 번에 조회.
부모를 조회 후, 연관 데이터는 개별 쿼리로 조회.
성능
적은 쿼리로 모든 데이터를 가져오지만, 불필요한 데이터까지 로드.
필요한 데이터만 가져오므로 메모리 사용량 감소.
N+1 문제 발생 여부
없음.
연관 데이터 사용 시 N+1 문제 발생 가능.
적합한 상황
- 자식 데이터가 항상 필요한 경우- 간단한 관계
- 자식 데이터가 드물게 필요- 대량 데이터 처리 시
설정 방식
fetch = FetchType.EAGER
fetch = FetchType.LAZY
4. 결론
즉시 로딩 (Eager):
연관 데이터를 항상 함께 로드해야 하는 경우 사용.
간단한 관계에 적합하지만, 관계가 복잡하거나 대량 데이터를 처리할 때는 성능 저하 가능.
지연 로딩 (Lazy):
연관 데이터를 사용할 일이 적거나, 데이터가 많아 메모리 효율성을 고려해야 하는 경우 적합.
N+1 문제가 발생할 수 있으므로 Fetch Join, Batch Size 등 최적화 방법을 함께 적용해야 함.
N + 1 문제 해결 방법
5.1 FetchType.EAGER로 변경
해결 원리
부모 데이터를 불러올 시에 자식 데이터도 한번에 다 '즉시' 전부 불러옴, 기존의 지연 로딩의 경우 필요한 경우에 불러오기 때문에 데이터를 다시 요청해야하지만, 즉시 로딩의 경우 이미 데이터를 다 불러왔기에 더이상 불러올 필요가 없다.
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY) // 기본 설정
private List<Child> children;
실행 쿼리 예시:
SELECT * FROM parent; -- 부모 데이터 조회 (1회)
SELECT * FROM child WHERE parent_id = 1; -- 부모 1번 자식 조회 (1회)
SELECT * FROM child WHERE parent_id = 2; -- 부모 2번 자식 조회 (1회)
-- 부모 N개일 경우 총 N+1번 쿼리 실행
2. FetchType.EAGER가 작동하는 방식
FetchType.EAGER (즉시 로딩):
부모 데이터를 조회할 때 연관된 자식 데이터를 함께 조회.
부모와 자식 데이터를 한 번의 JOIN 쿼리로 가져오므로 쿼리 실행 횟수가 줄어듦.
@OneToMany(mappedBy = "parent", fetch = FetchType.EAGER) // 즉시 로딩 설정
private List<Child> children;
실행 쿼리 예시:
SELECT p.*, c.* FROM parent p LEFT JOIN child c ON p.id = c.parent_id; -- 부모와 자식을 JOIN하여 한 번에 조회
결과:
부모와 자식 데이터를 한 번에 가져오기 때문에 N+1 문제가 발생하지 않음.
3. 해결 원리
Lazy vs Eager의 차이:
Lazy 로딩은 데이터를 필요로 하는 시점에 별도의 쿼리를 실행하여 자식 데이터를 가져옴 → N+1 문제 발생.
Eager 로딩은 부모 데이터를 조회하는 시점에 연관된 자식 데이터를 미리 가져옴 → 쿼리 실행 횟수 감소.
쿼리 실행 구조:
Lazy: 부모를 조회한 후, 자식 데이터를 부모 개수만큼 별도로 조회 → 여러 번의 쿼리 발생.
SELECT * FROM parent; -- 부모 데이터 조회
SELECT * FROM child WHERE parent_id = 1; -- 부모 1번의 자식 데이터 조회
SELECT * FROM child WHERE parent_id = 2; -- 부모 2번의 자식 데이터 조회
@Configuration public class JPAConfiguration { @PersistenceContext private EntityManager entityManager; @Bean public JPAQueryFactory jpaQueryFactory() { return new JPAQueryFactory(entityManager); } }
java<br>SELECT p FROM Post p JOIN FETCH p.comments WHERE p.id = :id;<br>
FetchType 옵션 비교
옵션
설명
장점
단점
EAGER
- 즉시 로딩.- 부모 엔티티 조회 시 자식 엔티티도 함께 조회.
- 편리함: 한 번의 조회로 연관 데이터 로드.- 항상 필요한 경우 적합.
- 불필요한 데이터 로드로 성능 저하.- N+1 문제 유발 가능.
LAZY
- 지연 로딩.- 부모 엔티티 조회 시 자식은 실제로 필요할 때 조회.
- 성능 최적화: 실제 필요한 경우에만 데이터 조회.- 불필요한 데이터 로드 방지.
- 필요 시 추가 쿼리 발생.- fetch join 필요 시 복잡성 증가.
추천 설정 및 사용 예제
기본 설정
대부분의 연관관계는 **LAZY**로 설정:
불필요한 데이터 로드를 방지.
필요 시 명시적으로 fetch join을 통해 데이터 조회.
항상 함께 쓰이는 관계
EAGER 설정:
예: @OneToOne에서 프로필과 사용자 관계처럼 항상 함께 조회되어야 하는 경우.
실제 사용 예제
1. FetchType 설정 예제
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@OneToOne(fetch = FetchType.EAGER)
private Profile profile; // 즉시 로딩
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Post> posts; // 지연 로딩
}
2. Fetch Join을 활용한 즉시 로딩
// 기본적으로 FetchType.LAZY 설정
@Entity
public class Post {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
}
// Fetch Join으로 LAZY 관계 즉시 로딩
String query = "SELECT p FROM Post p JOIN FETCH p.comments WHERE p.id = :id";
TypedQuery<Post> typedQuery = em.createQuery(query, Post.class);
typedQuery.setParameter("id", postId);
Post post = typedQuery.getSingleResult();
주의사항
N+1 문제:
EAGER 설정 시, 연관된 자식 엔티티를 매번 추가로 조회해 성능 문제가 발생할 수 있음.
해결책: fetch join 활용.
불필요한 로딩 방지:
필요하지 않은 데이터를 EAGER로 설정하지 않도록 주의.
실무 권장 사항:
대부분 LAZY 설정 후, 필요 시 명시적으로 fetch join 사용.
**EAGER**는 정말 항상 함께 조회되는 관계에만 설정.
테이블 객체로 자동 쿼리 생성하기
SprintData Common 의 CRUDRepository + PagingAndSortingRepository 이 쿼리기능을 제공
[1] JPA Repository 쿼리 기능
항목
설명
예시 코드
기본 정의
- Repository: Marker Interface, 자체 기능 없음.- JpaRepository: CRUD, 페이징, 정렬 기능 제공.
Spring Data JPA에 의해 구현체(SimpleJpaRepository)가 자동으로 생성 및 등록.
더 적은 코드로 복잡한 기능 구현 가능.
코드 비교: 기존 Repository vs JpaRepository
기존 Repository
@Repository
public class UserRepository {
@PersistenceContext
private EntityManager entityManager;
public User insertUser(User user) {
entityManager.persist(user);
return user;
}
public User selectUser(Long id) {
return entityManager.find(User.class, id);
}
}
JpaRepository로 변경
public interface UserRepository extends JpaRepository<User, Long> {
}
JpaRepository의 주요 제공 기능
CRUD 기능:
save(): 엔티티 저장/수정.
findById(): 기본 키로 엔티티 조회.
delete(): 엔티티 삭제.
페이징 및 정렬:
findAll(Pageable pageable): 페이징 조회.
findAll(Sort sort): 정렬된 목록 조회.
커스텀 쿼리 작성:
메서드 이름 기반 쿼리 생성 (findByName).
JPQL 또는 네이티브 쿼리 작성 가능 (@Query).
Spring Data JPA의 장점
자동 빈 등록:
@EnableJpaRepositories를 통해 자동으로 Repository 구현체 등록.
간결한 코드:
구현체 없이 인터페이스만으로 복잡한 기능 제공.
일관된 예외 처리:
데이터 접근 계층의 일관된 예외 체계.
결론
기존 @Repository 방식은 코드가 길고 직접 EntityManager를 사용해야 하지만,
JpaRepository를 사용하면 CRUD, 페이징, 정렬 등 다양한 기능을 더 간단하게 구현 가능.
Pageable firstPage = PageRequest.of(0, 3); // 첫 페이지, 페이지 크기 3
Pageable sortedByName = PageRequest.of(1, 5, Sort.by("name")); // 두 번째 페이지, 정렬 추가
Page<User> pageResult = userRepository.findByName("John", firstPage);
Repository는 데이터 접근 계층에 집중하고, 비즈니스 로직은 서비스 계층에서 처리하는 것이 일반적.
간단한 작업에 한해 Repository에서 처리.
예제 코드
1. Optional 제거
public interface UserRepository extends JpaRepository<User, Long> {
default User findUserById(Long id) {
return findById(id).orElseThrow(() ->
new DataNotFoundException("User not found with id: " + id));
}
}
2. 메서드명 간소화
public interface ProductRepository extends JpaRepository<Product, Long> {
// 긴 메서드 이름
List<Product> findAllByCategoryAndPriceGreaterThanEqualAndPriceLessThanEqualOrderByPriceAsc(String category, BigDecimal minPrice, BigDecimal maxPrice);
// 간단한 메서드 이름
default List<Product> findProductsByCategoryAndPriceRange(String category, BigDecimal minPrice, BigDecimal maxPrice) {
return findAllByCategoryAndPriceGreaterThanEqualAndPriceLessThanEqualOrderByPriceAsc(category, minPrice, maxPrice);
}
}
@Query("SELECT u.user_name AS userName FROM User u WHERE u.address = :address")
List<User> findByAddress(@Param("address") String address, Sort sort);
// 호출 시
List<User> users = userRepository.findByAddress("Korea", Sort.by("userName").ascending());
Mapping File 에서 쿼리를 조회해서 쿼리를 수행하고 응답을 받아올 수 있는 세션 객체
Mapper Interface (8), (9)
DB 에서 조회하는 객체와 Java 프로그램의 객체간에 인터페이스를 정의하는 객체
방법1. Dao 클래스 정의
SqlSession 를 직접적으로 사용하는 방법
SqlSession 멤버 변수로 사용하며 쿼리파일 수행 요청
// UserDao.java
import org.apache.ibatis.session.SqlSession;
import org.springframework.stereotype.Component;
import com.thesun4sky.querymapper.domain.User;
@Component
public class UserDao {
// SqlSession 멤버 변수로 사용하며 쿼리파일 수행 요청
private final SqlSession sqlSession;
public UserDao(SqlSession sqlSession) {
this.sqlSession = sqlSession;
}
public User selectUserById(long id) {
return this.sqlSession.selectOne("selectUserById", id);
}
}
장점
쿼리문 실행 전에 넣어줄 매개변수와 쿼리 결과값의 변형을 정의할 수 있다.
Namespace를 내 마음대로 둘 수 있다.
.xml 파일의 쿼리문 id와 mapper 메소드명을 일치시킬 필요가 없다.
단점
Sqlsession 객체를 주입받아야 하며, 쿼리문 실행 시 항상 호출해야 한다.
쿼리문 호출 시 sqlsession에 .xml 파일의 namespce와 쿼리문 id를 매개변수로 넘겨야한다.
방법2. Mapper Interface 정의
SqlSession 를 간접적으로 사용하는 방법
ibatis 에서 구현해주는 org.apache.ibatis.annotations.Mapper 어노테이션을 사용하면 sqlSession 를 사용하여 자동으로 호출해줌
// UserMapper.java
@Mapper
public interface UserMapper {
User selectUserById(@Param("id") Long id);
}
장점
메소드의 내부 구현이 불필요하다.
Sqlsession 객체 주입이 불펼요하다.
.xml 파일의 쿼리문 id와 mapper 메소드 명이 일치한다.
단점
.xml의 Namespace가 실제 Mapper.java 위치를 가르켜야 한다.
메소드 내부 정의가 불가능하다.
Mapping File (10)
SqlSession 가 실행하는 쿼리가 담긴 파일
정의된 인터페이스에 기반해서 수행할 쿼리를 담아두고
쿼리 수행결과를 어떤 인터페이스 매핑할지 정의해놓은 파일
<!-- UserMapper.xml -->
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thesun4sky.querymapper.mapper.UserMapper">
<select id="selectUserById" resultType="User">
select id, name from users where id = #{id}
</select>
</mapper>
쿼리 코드 만들기 (JpaRepository)
QueryMapper 의 DB의존성 및 중복 쿼리 문제로 ORM 이 탄생했다.
ORM 은 DB의 주도권을 뺏어왔다고 표현해도 과언이 아닙니다.
ORM 은 DAO 또는 Mapper 를 통해서 조작하는것이 아니라 테이블을 아예 하나의 객체(Object)와 대응시켜 버립니다.
말이 쉽지…. 객체지향(Object) 을 관계형 데이터베이스(Relation) 에 매핑(Mapping) 한다는건 정말 많은 난관이 있습니다.
- flush() 호출 전까지 SQL 쿼리를 영속성 컨텍스트에 모아두었다가, 한 번에 DB로 전송하는 최적화 메커니즘.
쓰기 지연 발생 시점
- 트랜잭션 중 객체 생성, 수정, 삭제 시. - flush() 호출 전까지 쿼리를 최적화하여 보관.
쓰기 지연 효과
- 여러 동작을 모아 쿼리를 한번에 전송하여 최소화. - 생성/수정/삭제 작업의 중간 상태가 발생하더라도 실제 DB에는 최적화된 쿼리만 전송. - 불필요한 쿼리 전송 방지.
주의점
- GenerationType.IDENTITY 사용 시, 쓰기 지연이 적용되지 않음. - 이유: IDENTITY 전략은 키 생성 시점에 단일 쿼리가 필요하며, 외부 트랜잭션 간의 키 중복을 방지하기 위해 즉시 DB에 반영됨.
예제 코드의 흐름
단계
동작 설명
1. 객체 생성
새로운 객체 생성 (new 상태).
2. 엔티티 매니저 생성
영속성 컨텍스트를 관리할 엔티티 매니저 생성.
3. 트랜잭션 시작
데이터의 무결성을 보장하기 위해 트랜잭션 시작.
4. 객체 저장
persist() 호출로 객체를 영속성 컨텍스트에 저장.
5. flush() 호출
영속성 컨텍스트의 SQL 쿼리를 DB로 전송 (commit 시 자동 수행).
6. commit() 호출
DB에 쿼리를 최종 반영.
7. 자원 해제
엔티티 매니저 및 팩토리 자원 반환 (close()).
ORM 을 사용하는 가장 쉬운 방법 : JpaRepository
💁♂️ Repository vs JpaRepository
기존 Repository
@Repository 을 클래스에 붙인다.
@Component 어노테이션을 포함하고 있어서 앱 실행시 생성 후 Bean으로 등록된다.
앞서배운 Repository 기본 기능만 가진 구현체가 생성된다. (DB별 예외처리 등)
새로운 JpaRepository
JpaRepository<Entity,ID> 인터페이스를 인터페이스에 extends 붙인다.
@NoRepositoryBean 된 ****상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다. (@NoRepositoryBean = 빈생성 막음 →상속받으면 생성돼서 사용가능)
JpaRepository (마스터 셰프): 데이터 액세스를 위한 핵심 기능의 종합적인 요리책(기능) 을 제공합니다.
@NoRepositoryBean 인터페이스 (셰프): 각 인터페이스는 특정 데이터 액세스 방법을 제공하는 전문적인 기술 또는 레시피를 나타냅니다.
JpaRepository 상속: 마스터 셰프의 요리책과 셰프의 전문성을 얻습니다.
SpringDataJpa 에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다. (상위 인터페이스들의 기능)
Repository 와 JpaRepository 를 통해 얼마나 간단하게 구현하게 될지 미리 확인해볼까요?
Repository 샘플
EntityManager 멤버변수를 직접적으로 사용
// UserRepository.java
@Repository
public class UserRepository {
@PersistenceContext
EntityManager entityManager;
public User insertUser(User user) {
entityManager.persist(user);
return user;
}
public User selectUser(Long id) {
return entityManager.find(User.class, id);
}
}
JpaRepository 샘플
EntityManager 멤버변수를 간접적으로 사용
// UserRepository.java
public interface UserRepository extends JpaRepository<User, Long> {
// 기본 메서드는 자동으로 만들어짐
}
CREATE TABLE MEMBER (
MEMBER_ID BIGINT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
home_city VARCHAR(255) NOT NULL,
home_street VARCHAR(255) NOT NULL,
company_city VARCHAR(255) NOT NULL,
company_street VARCHAR(255) NOT NULL,
PRIMARY KEY (MEMBER_ID)
);
3. Collection Value 타입 매핑
@Entity
public class Product {
@Id
@GeneratedValue
private Long id;
@ElementCollection
@CollectionTable(name = "product_tags", joinColumns = @JoinColumn(name = "product_id"))
@Column(name = "tag")
private List<String> tags = new ArrayList<>();
}
생성되는 테이블:
CREATE TABLE product_tags (
product_id BIGINT NOT NULL,
tag VARCHAR(255),
PRIMARY KEY (product_id, tag)
);
특징 및 활용 요약
기본 타입: 일반적인 데이터 저장에 사용되며, 설정 옵션으로 제약조건 지정.
Composite Value 타입: 코드의 응집도를 높이고 복합 데이터를 쉽게 관리.
Collection Value 타입: 여러 값 관리에 유용하지만, 대규모 데이터에서는 다대일 연관관계를 선호.
테이블 객체 만들기
User Entity 만들어보기
id, username, password 를 가지는 User Entity 를 만들어 봅니다.
// User.java
// lombok
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString
// jpa
@Entity
@Table(name = "users")
public class User {
/**
* 컬럼 - 연관관계 컬럼을 제외한 컬럼을 정의합니다.
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
private String username;
private String password;
/**
* 생성자 - 약속된 형태로만 생성가능하도록 합니다.
*/
@Builder
public User(String username, String password) {
this.username = username;
this.password = password;
}
/**
* 연관관계 - Foreign Key 값을 따로 컬럼으로 정의하지 않고 연관 관계로 정의합니다.
*/
@OneToMany
@Exclude
private Set<UserChannel> userChannel;
/**
* 연관관계 편의 메소드 - 반대쪽에는 연관관계 편의 메소드가 없도록 주의합니다.
*/
/**
* 서비스 메소드 - 외부에서 엔티티를 수정할 메소드를 정의합니다. (단일 책임을 가지도록 주의합니다.)
*/
public void updateUserName(String username) {
this.username = username;
}
public void updatePassword(String password) {
this.password = password;
}
}
기타 추천 플러그인
Key PromoterX
단축키 알림
Presentation Assistant
알림 이쁘게 보여주기
테이블 객체끼리 관계만들기
Raw JPA 연관관계 매핑 기능 요약 표
애노테이션
설명
주요 속성
예시 코드
@OneToOne
- 1:1 관계를 매핑. - 단방향 및 양방향 매핑 가능.- 테이블 분리 여부를 신중히 검토.
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@OneToOne
@JoinColumn(name = "locker_id")
private Locker locker;
}
@Entity
public class Locker {
@Id
@GeneratedValue
private Long id;
}
2. @OneToMany와 @ManyToOne 양방향 매핑
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "parent")
private List<Child> childList;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
3. @ManyToMany 매핑
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
@ManyToMany(mappedBy = "parents")
private List<Child> childs;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
@ManyToMany
@JoinTable(
name = "parent_child",
joinColumns = @JoinColumn(name = "parent_id"),
inverseJoinColumns = @JoinColumn(name = "child_id")
)
private List<Parent> parents;
}
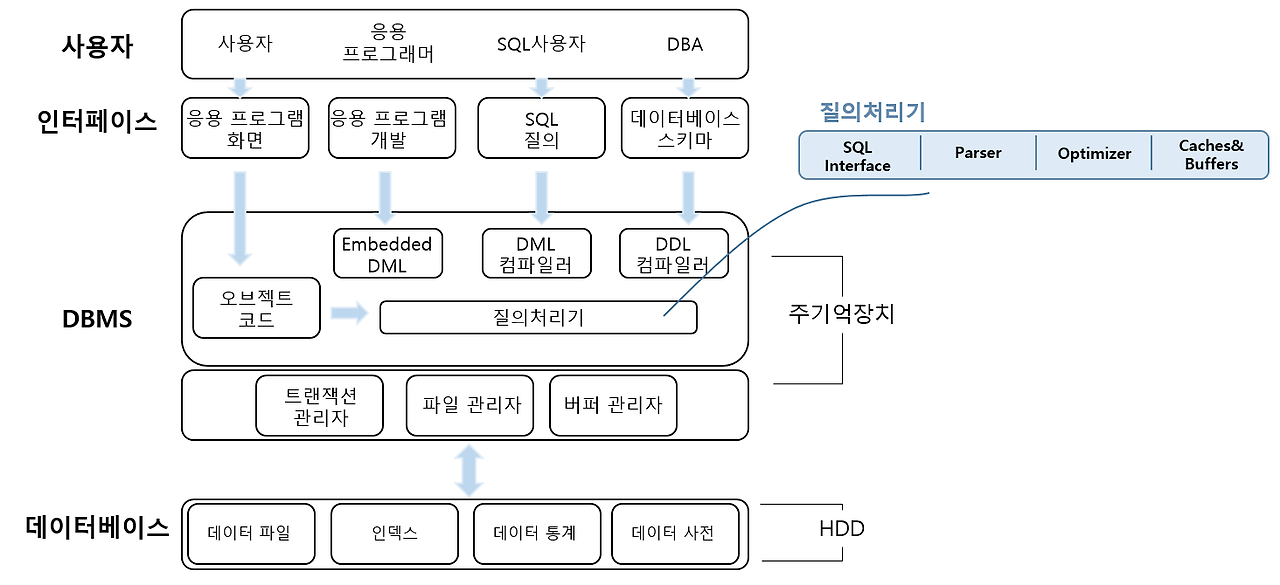
위 이미지는 데이터베이스 시스템(DBMS)의 전체적인 구조를 나타낸 것입니다. 데이터베이스 시스템은 사용자 인터페이스, DBMS(데이터베이스 관리 시스템), 데이터베이스라는 3개의 주요 계층으로 구성됩니다. 각각의 구성 요소와 동작 방식은 다음과 같습니다.
1. 사용자 계층 (Interface Layer)
사용자: 데이터베이스를 직접 사용하거나, 애플리케이션을 통해 간접적으로 접근하는 주체입니다.
응용 프로그램 화면: 일반 사용자들이 데이터베이스와 상호작용하기 위해 사용하는 UI.
응용 프로그램 개발: 응용 프로그램 개발자가 SQL이나 프로그래밍 언어를 사용해 데이터베이스와 연동하는 로직을 작성.
SQL 사용자: SQL을 통해 데이터를 직접 질의하거나 수정하는 사용자.
DBA (Database Administrator): 데이터베이스 관리자로, 데이터베이스의 설계, 최적화, 권한 부여 등을 담당.
2. DBMS 계층 (Database Management System Layer)
이 계층은 데이터베이스의 데이터를 저장, 질의, 관리, 최적화하는 모든 기능을 담당합니다. 주로 아래의 요소들로 구성됩니다:
1) 컴파일러
Embedded DML: 응용 프로그램 코드에 포함된 SQL 명령을 처리합니다.
DML 컴파일러: 데이터 조작 언어(Data Manipulation Language)를 컴파일하여 실행.
예: SELECT, INSERT, UPDATE, DELETE 명령어.
DDL 컴파일러: 데이터 정의 언어(Data Definition Language)를 해석하여 데이터베이스 구조를 생성 및 변경.
예: CREATE TABLE, ALTER TABLE.
2) 질의 처리기 (Query Processor)
SQL 질의를 실행하기 위한 주요 컴포넌트:
SQL Interface: SQL 명령어를 입력받는 인터페이스.
Parser: SQL 명령어를 해석하여 쿼리 트리(Query Tree)로 변환.
Optimizer: 최적의 실행 계획을 수립하여 쿼리를 효율적으로 처리.
Caches & Buffers: 자주 사용하는 데이터를 캐시와 버퍼에 저장하여 성능 향상.
3) 트랜잭션 관리자 (Transaction Manager)
데이터의 무결성과 일관성을 보장하기 위해 ACID 특성을 관리:
원자성, 일관성, 고립성, 지속성.
4) 파일 관리자 및 버퍼 관리자
파일 관리자: 데이터 파일과 데이터베이스 파일 시스템 간의 인터페이스.
버퍼 관리자: 디스크 I/O를 최소화하고 메모리를 효율적으로 사용.
3. 데이터 계층 (Database Layer)
데이터베이스 계층은 데이터를 물리적으로 저장하고 관리하는 부분입니다.
데이터 파일: 실제 데이터를 저장하는 파일.
인덱스: 데이터를 빠르게 검색할 수 있도록 도와주는 구조.
데이터 통계: 데이터 분포에 대한 정보를 저장, 쿼리 최적화에 사용.
데이터 사전: 데이터베이스 메타데이터를 저장. 테이블, 열, 데이터 유형 등에 대한 정보를 포함.
전체적인 동작 흐름
사용자 입력
사용자가 SQL 질의를 실행하거나, 응용 프로그램을 통해 데이터베이스와 상호작용합니다.
질의 처리
SQL 질의는 SQL Interface를 통해 입력되고, Parser와 Optimizer를 거쳐 실행 계획이 생성됩니다.
실행
실행 계획에 따라 트랜잭션 관리자와 파일 관리자가 협력하여 데이터를 검색, 수정, 저장합니다.
데이터 입출력
요청된 데이터는 데이터베이스 계층에서 검색되어 캐시/버퍼를 통해 사용자에게 반환됩니다.
특징 및 장점
모듈화
각 계층은 독립적으로 동작하면서도 서로 협력하여 효율적인 데이터 관리 가능.
효율적인 데이터 처리
쿼리 최적화, 캐싱, 트랜잭션 관리 등을 통해 성능을 극대화.
데이터 무결성 보장
트랜잭션 관리와 데이터 사전을 통해 데이터의 무결성과 일관성 유지.
확장성
다양한 사용자 요구를 충족하며, 대규모 데이터와 동시 사용자 환경에서도 안정적인 성능 제공.
쉽게 이해하기
이 구조는 사용자가 간단한 SQL 명령을 입력하면, DBMS 내부에서 이를 해석, 최적화, 실행하고, 실제 데이터베이스에서 결과를 반환하는 일련의 과정을 보여주는 설계입니다.
궁금한 점이 있거나 더 설명이 필요한 부분이 있다면 말씀해주세요! 😊
객체 지향 프로그래밍(OOP)과 관계형 데이터베이스(RDB)의 패러다임 불일치
JPA의 등장 이유
객체 지향 프로그래밍(OOP)과 관계형 데이터베이스(RDB)는 서로 다른 방식으로 데이터를 표현합니다. 이로 인해 개발자는 객체와 데이터베이스 간의 불일치를 해결하기 위해 많은 작업을 해야 하며, 이 문제를 해결하기 위해 JPA(Java Persistence API)가 등장했습니다. 다음은 주요 내용을 정리한 것입니다.
1. 객체와 관계형 데이터베이스의 구조적 차이
객체 지향 모델: 클래스(설계도)를 기반으로 객체를 생성하며, 속성(필드)과 동작(메서드)을 포함.
관계형 모델: 데이터를 테이블 형식으로 저장하며, 열(컬럼)과 행(로우)으로 구성.
이 두 모델의 표현 방식 차이로 인해, 데이터를 저장하거나 조회할 때 매핑 작업이 필수적입니다.
2. 반복되는 CRUD 작업
객체를 데이터베이스에 저장(Create), 조회(Read), 수정(Update), 삭제(Delete)하기 위해 개발자는 항상 SQL 쿼리를 직접 작성해야 합니다.
이로 인해 코드 중복이 발생하고, 유지보수가 어려워집니다.
3. 상속과 연관관계 매핑의 어려움
상속: 객체 지향 언어는 상속을 지원하지만, 관계형 데이터베이스는 이를 직접적으로 지원하지 않습니다. 따라서 별도의 매핑 작업이 필요합니다.
연관관계: 객체는 참조를 통해 관계를 표현하지만, 데이터베이스는 **외래 키(Foreign Key)**와 **조인(JOIN)**을 통해 관계를 나타냅니다.
이 차이로 인해 객체 간의 관계를 데이터베이스에 저장하거나 조회하는 과정이 복잡해질 수 있습니다.
4. 객체 비교의 문제
동일한 데이터를 조회하더라도 다른 객체 인스턴스로 다뤄질 수 있습니다.
이로 인해 객체를 비교할 때 의도한 결과를 얻지 못할 가능성이 있습니다.
JPA의 등장
이러한 패러다임 불일치 문제를 해결하기 위해 JPA가 도입되었습니다. JPA는 다음과 같은 방식으로 문제를 해소합니다:
객체를 자바 컬렉션(LIST, MAP등)처럼 다룰 수 있게 해줌.
객체와 데이터베이스 간의 매핑 작업을 자동화하여 개발자의 부담을 줄임.
JPA의 장점:
개발 생산성 향상
코드 중복 감소
유지보수성 강화
JDBC(Java Database Connectivity)
📌 JDBC(Java Database Connectivity*는 Java에서데이터베이스와 상호작용하기 위한 표준 API입니다. 이를 통해 SQL 명령을 실행하고 데이터베이스와 연결하여 데이터를 조회하거나 변경할 수 있습니다.
JDBC는 다양한 DBMS(MySQL, PostgreSQL, Oracle 등)와 연동하기 위한 기반 기술입니다.
JDBC의 주요 특징
표준화된 데이터베이스 액세스 API:
Java와 데이터베이스 간의 통신을 위한 표준 인터페이스를 제공합니다.
DBMS에 의존적이지 않으며, 다양한 데이터베이스 드라이버를 통해 활용 가능합니다.
SQL 실행:
데이터베이스에서CRUD 작업(Create, Read, Update, Delete)을 수행할 수 있습니다.
DB 드라이버 기반 동작:
각 DBMS에 맞는JDBC 드라이버를 통해 데이터베이스와 상호작용합니다.
저수준 API:
데이터베이스 연결, SQL 실행, 자원 관리 등 모든 과정을 개발자가 직접 제어해야 합니다.
광범위한 지원:
모든 주요 데이터베이스(MySQL, Oracle, PostgreSQL 등)와 연동 가능합니다.
JDBC의 주요 구성 요소
구성 요소
설명
DriverManager
데이터베이스 연결을 관리하고, 적절한 드라이버를 선택해주는 역할을 합니다.
Connection
데이터베이스와의 연결을 나타내는 객체로, SQL 실행을 위한 Statement 객체를 생성합니다.
Statement
SQL 쿼리를 실행하는 객체로, 정적 SQL 실행을 처리합니다.
PreparedStatement
파라미터화된 SQL 쿼리를 실행하는 객체로, 성능 향상과 보안(SQL Injection 방지)에 유리합니다.
Statement는 **JDBC(Java Database Connectivity)**에서 제공하는 인터페이스로,SQL 쿼리를 실행하고 결과를 처리하는 데 사용됩니다. 데이터베이스와 상호작용하기 위해SQL을 실행하는 기본 도구이며, JDBC API의 핵심 구성 요소 중 하나입니다.
Statement의 특징
SQL 실행:
정적 SQL 쿼리를 실행하는 데 사용됩니다.
SQL 문자열을 전달하면 데이터베이스에서 실행하고 결과를 반환받습니다.
직접적인 SQL 실행:
SQL 쿼리를 문자열로 작성하여 Statement 객체를 통해 실행합니다.
SQL 쿼리에 파라미터를 포함하지 않고, 동적 데이터 삽입 시 문자열 연결을 사용합니다.
자원 관리 필요:
Connection 객체를 통해 생성되고, 실행 후 반드시 닫아야 합니다.
Statement 사용 방법
1. Statement 객체 생성
Connection 객체를 사용하여 Statement 객체를 생성합니다.
Statement stmt = connection.createStatement();
2. SQL 실행
데이터 조회 (SELECT):
executeQuery() 메서드로 쿼리를 실행하고, 결과를 ResultSet 객체로 반환받습니다.
String sql = "SELECT * FROM users";
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println("ID: " + id + ", Name: " + name);
}
데이터 변경 (INSERT, UPDATE, DELETE):
executeUpdate() 메서드로 쿼리를 실행하고, 영향을 받은 행(row) 수를 반환합니다.
String sql = "INSERT INTO users (name, email) VALUES ('John', 'john@example.com')";
int rowsInserted = stmt.executeUpdate(sql);
System.out.println(rowsInserted + " row(s) inserted.");
기타 쿼리 실행:
execute() 메서드로 쿼리를 실행하며, 실행 결과가 여러 종류(SELECT, UPDATE 등)일 수 있을 때 사용됩니다.
특별한 규칙이나 라이브러리 의존 없이 작성된 순수한 자바 객체를 의미합니다. 즉, 자바의 기본 문법으로 작성된 간단한 객체로, 특정 프레임워크나 기술에 종속되지 않습니다.
POJO의 특징
순수한 자바 객체
자바 문법으로 작성된 일반적인 클래스.
상속받아야 하거나 특정 인터페이스를 구현해야 하는 제약이 없음.
독립적
특정 프레임워크나 라이브러리에 의존하지 않음.
예를 들어, EJB(Enterprise JavaBeans)와 같은 복잡한 환경과 반대되는 개념.
간결하고 직관적
클래스의 속성(필드)과 이를 조작하기 위한 메서드(getter, setter 등)만 포함.
POJO의 예시
POJO 클래스
public class User {
private String name;
private int age;
// 기본 생성자
public User() {}
// 매개변수 있는 생성자
public User(String name, int age) {
this.name = name;
this.age = age;
}
// Getter와 Setter
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
사용
public class Main {
public static void main(String[] args) {
User user = new User("Alice", 25);
System.out.println(user.getName()); // Alice
user.setAge(26);
System.out.println(user.getAge()); // 26
}
}
POJO가 중요한 이유
단순성
복잡한 규약 없이도 자바 기본 문법으로 개발 가능.
테스트 용이성
외부 의존성이 없으므로 단위 테스트(Unit Test)를 쉽게 작성할 수 있음.
프레임워크 독립성
특정 프레임워크에 종속되지 않기 때문에 코드가 재사용 가능하고 이식성이 높음.
JPA와의 연관성
JPA의 엔티티(Entity)는 POJO로 작성되므로, 객체 지향적인 코드를 유지할 수 있음.
예: JPA의 @Entity 클래스는 POJO의 형태를 따름.
POJO와 다른 개념의 비교
POJO
JavaBean
단순한 자바 객체
POJO의 일종으로, 특정 규약을 따름
규칙 없음
기본 생성자, Getter/Setter 필수
특정 프레임워크 의존 없음
JavaBean 표준 스펙 준수
결론
POJO는 자바 프로그래밍의 기본적인 단순 객체로, 복잡한 제약 없이 작성되어 코드의 가독성과 유지보수성을 높여줍니다. JPA, 스프링과 같은 프레임워크에서 핵심적으로 사용되는 객체 형태입니다.
DBMS 독립성
JPA는 DBMS에 종속되지 않으며, 설정에 따라 MySQL, PostgreSQL, Oracle 등 다양한 데이터베이스에서 작동.
캐싱 지원
1차 캐시(영속성 컨텍스트)와 2차 캐시를 통해 성능을 최적화.
JPA의 동작 원리
엔티티(Entity)
데이터베이스 테이블에 매핑되는 자바 클래스.
예: @Entity 어노테이션을 사용하여 매핑.
영속성 컨텍스트(Persistence Context)
엔티티 객체를 관리하는 JPA의 내부 메커니즘.
데이터베이스와의 연결을 관리하며, 엔티티를 캐싱해 성능을 최적화.
EntityManager
엔티티의 생성, 조회, 수정, 삭제 작업을 담당하는 JPA의 핵심 인터페이스.
JPA를 통해 데이터베이스 작업을 처리하는 주요 도구.
JPA의 주요 동작
상태
설명
비영속(New)
엔티티가 영속성 컨텍스트에 저장되지 않은 상태.
영속(Managed)
엔티티가 영속성 컨텍스트에 저장되어 데이터베이스와 동기화되는 상태.
준영속(Detached)
영속성 컨텍스트에서 분리된 상태로, 데이터베이스와 동기화되지 않음.
삭제(Removed)
엔티티가 영속성 컨텍스트에서 제거되고 데이터베이스에서 삭제 대기 상태.
JPA를 사용하는 이유
객체 중심 개발
SQL 중심 개발에서 객체 중심 개발로 전환 가능.
데이터베이스 작업 시 객체 지향 패러다임을 유지.
생산성 향상
CRUD 작업에 필요한 SQL을 직접 작성하지 않아도 됨.
코드의 중복 제거, 유지보수 용이.
DBMS 독립성
데이터베이스 종류에 관계없이 동일한 코드로 동작 가능.
성능 최적화
1차 캐시, 지연 로딩(Lazy Loading), 벌크 작업 최적화 등 다양한 성능 향상 기법 제공.
트랜잭션 관리
JPA는 트랜잭션 경계 내에서 데이터 일관성과 무결성을 보장.
JPA 주요 어노테이션
어노테이션
설명
@Entity
클래스가 데이터베이스 테이블과 매핑됨을 나타냄.
@Table
엔티티가 매핑될 테이블 이름을 지정.
@Id
기본 키를 지정.
@GeneratedValue
기본 키의 자동 생성 전략을 지정.
@Column
엔티티의 필드를 테이블의 컬럼과 매핑.
@ManyToOne
다대일 관계를 매핑.
@OneToMany
일대다 관계를 매핑.
@JoinColumn
외래 키를 지정.
JPA vs Hibernate
JPA: 자바에서 ORM을 위한 표준 인터페이스.
Hibernate: JPA의 구현체 중 하나로, 추가적인 기능을 제공.
JPA 사용 예시
1. 엔티티 클래스
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
private int age;
// Getters and Setters
}
2. 데이터 저장
EntityManager em = entityManagerFactory.createEntityManager();
em.getTransaction().begin();
User user = new User();
user.setName("John");
user.setAge(30);
em.persist(user); // 데이터 저장
em.getTransaction().commit();
3. 데이터 조회
User user = em.find(User.class, 1L); // ID가 1인 사용자 조회
System.out.println(user.getName());
JPA의 장단점
장점
객체 지향 패러다임과 데이터베이스 간의 불일치 해결.
SQL 작성 없이 객체 중심으로 데이터 처리.
데이터베이스 변경 시 코드 변경 최소화.
트랜잭션, 캐싱, 성능 최적화 기능 내장.
단점
학습 곡선이 있음 (초기 학습 난이도).
복잡한 쿼리는 JPQL로 처리해야 하며, SQL보다 직관성이 떨어질 수 있음.
대규모 프로젝트에서는 잘못된 설정으로 성능 저하 가능.
결론
JPA는 자바 애플리케이션에서 관계형 데이터베이스를 효율적으로 다루기 위한 표준화된 솔루션입니다. 객체 중심 개발을 가능하게 하며, 생산성과 유지보수성을 크게 향상시킬 수 있습니다.
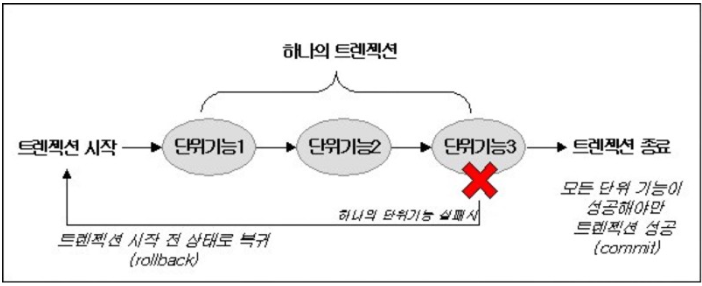
트랜잭션
🐳 데이터베이스에서 작업의논리적인 단위를 의미합니다. 트랜잭션은 하나의 작업 단위를 구성하며, 이 단위가 완전히 성공하거나 실패해야 데이터의 무결성을 보장합니다.
트랜잭션의 동작 예시
1) 은행 송금 시스템
계좌 A에서 100원을 인출하고, 계좌 B에 100원을 입금하는 작업:
BEGIN TRANSACTION
1. 계좌 A에서 100원 출금
2. 계좌 B에 100원 입금
IF 모든 작업 성공:
COMMIT
ELSE:
ROLLBACK
두 작업(출금과 입금)은 하나의트랜잭션으로 처리되며, 둘 중 하나라도 실패하면 롤백되어 데이터 무결성을 유지합니다.
트랜잭션의 특징 (ACID 속성)
원자성 (Atomicity):
트랜잭션 내의 모든 작업이모두 성공하거나 모두 실패해야 합니다.
일부 작업만 실행되고 나머지가 실패하면, 전체 작업을 취소(롤백)하여 데이터 일관성을 유지합니다.
일관성 (Consistency):
트랜잭션이 성공적으로 완료되면, 데이터베이스가 항상일관성 있는 상태로 유지됩니다.
예: 은행 송금 시, 한 계좌에서 돈을 빼면 다른 계좌에 같은 금액이 추가되어야 함.
고립성 (Isolation):
여러 트랜잭션이 동시에 실행될 경우, 각 트랜잭션은서로 독립적으로 실행되어야 합니다.
한 트랜잭션의 중간 결과가 다른 트랜잭션에 노출되지 않음.
지속성 (Durability):
트랜잭션이 커밋된 후에는영구적으로 데이터베이스에 반영되어야 합니다.
서버가 중단되거나 시스템 장애가 발생해도 데이터는 손실되지 않습니다.
트랜잭션의 상태
활성 (Active):
트랜잭션이 시작되고 작업이 진행 중인 상태.
부분 완료 (Partially Committed):
트랜잭션의 마지막 명령이 실행되었지만, 아직 커밋되지 않은 상태.
완료 (Committed):
트랜잭션이 성공적으로 완료되어 데이터베이스에 반영된 상태.
실패 (Failed):
트랜잭션이 오류로 인해 중단된 상태.
철회 (Aborted):
트랜잭션이 실패하거나 취소되어 롤백된 상태.
트랜잭션의 처리 과정
트랜잭션 시작:
트랜잭션을 시작하여 작업 단위를 정의.
작업 실행:
트랜잭션 내에서 여러 데이터베이스 작업(쿼리, 삽입, 업데이트, 삭제 등)을 실행.
커밋 또는 롤백:
모든 작업이 성공하면커밋하여 데이터베이스에 변경 사항을 반영.
작업 중 오류가 발생하면롤백하여 변경 사항을 취소.
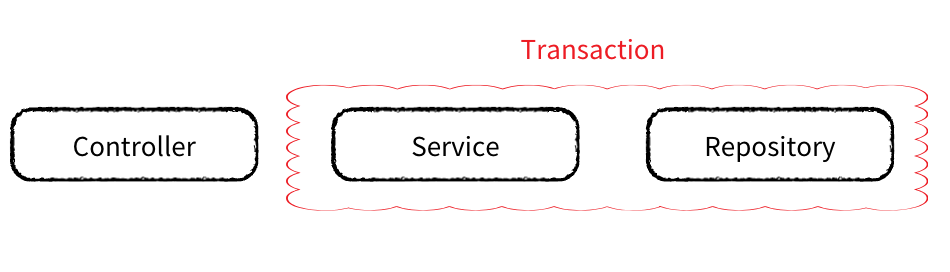
Spring에서의 트랜잭션 관리
Spring은프록시 기반 AOP를 사용하여 트랜잭션 관리를 제공합니다. Spring의 트랜잭션 관리 기능은 선언적 방식과 프로그래밍 방식으로 사용 가능합니다.
1. 선언적 트랜잭션 관리
Spring에서는 @Transactional 어노테이션을 사용하여 선언적으로 트랜잭션을 관리할 수 있습니다.
@Service
public class UserService {
@Transactional
public void createUser(User user) {
userRepository.save(user);
emailService.sendWelcomeEmail(user); // 예외 발생 시 전체 롤백
}
}
@Transactional이 붙은 메서드는 트랜잭션이 시작되고, 예외 발생 시 롤백됩니다.
커밋은 메서드 실행이 성공적으로 종료되면 수행됩니다.
2. 프로그래밍 방식 트랜잭션 관리
프로그래밍 방식으로 PlatformTransactionManager를 사용하여 트랜잭션을 직접 관리할 수 있습니다.
@Service
public class UserService {
@Autowired
private PlatformTransactionManager transactionManager;
public void createUser(User user) {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
userRepository.save(user);
emailService.sendWelcomeEmail(user);
transactionManager.commit(status); // 성공 시 커밋
} catch (Exception e) {
transactionManager.rollback(status); // 실패 시 롤백
}
}
}
트랜잭션 전파 수준 (Propagation)
트랜잭션 전파(Propagation)는 트랜잭션이 다른 메서드 호출 시 어떻게 동작할지 정의합니다.
전파속성
설명
REQUIRED
기본값. 기존 트랜잭션이 있으면 참여하고, 없으면 새 트랜잭션 생성.
REQUIRES_NEW
항상 새 트랜잭션을 생성. 기존 트랜잭션은 일시 중단.
NESTED
중첩 트랜잭션을 생성. 롤백은 부모 트랜잭션과 독립적.
MANDATORY
기존 트랜잭션이 없으면 예외 발생.
SUPPORTS
트랜잭션이 있으면 참여, 없으면 트랜잭션 없이 실행.
NOT_SUPPORTED
항상 트랜잭션 없이 실행. 기존 트랜잭션은 일시 중단.
NEVER
트랜잭션 없이 실행하며, 기존 트랜잭션이 있으면 예외 발생.
트랜잭션 격리 수준 (Isolation)
트랜잭션 격리 수준은 동시에 실행되는 트랜잭션 간의 상호작용을 제어합니다.
격리 수준
설명
DEFAULT
데이터베이스의 기본 격리 수준을 따름.
READ_UNCOMMITTED
다른 트랜잭션이 커밋하지 않은 데이터도 읽을 수 있음. (Dirty Read 가능)
READ_COMMITTED
다른 트랜잭션이 커밋한 데이터만 읽을 수 있음.
REPEATABLE_READ
같은 트랜잭션 내에서 동일 데이터를 반복적으로 읽어도 동일한 결과를 보장.
SERIALIZABLE
가장 높은 격리 수준. 트랜잭션을 순차적으로 실행하여 충돌 방지.
트랜잭션 롤백 조건
Spring의 @Transactional은 기본적으로런타임 예외가 발생할 때 롤백합니다.
롤백 예외 설정
@Transactional(rollbackFor = Exception.class)
public void process() {
// Exception 발생 시 롤백
}
롤백 제외 설정
@Transactional(noRollbackFor = CustomException.class)
public void process() {
// CustomException 발생 시 롤백하지 않음
}
트랜잭션의 장점
데이터 무결성 보장:
작업 도중 오류가 발생해도 데이터 손상 방지.
동시성 제어:
여러 사용자가 동시에 데이터베이스에 접근해도 데이터 충돌 방지.
복잡한 작업 관리:
여러 작업 단위를 하나의 트랜잭션으로 묶어 관리 가능.
자동화된 관리:
Spring의 트랜잭션 관리를 통해 선언적으로 간단하게 설정 가능.
정리
**트랜잭션(Transaction)**은하나의 논리적인 작업 단위를 정의하며, 데이터베이스의 무결성과 일관성을 보장합니다. Spring은 선언적 트랜잭션(@Transactional)을 제공하여 개발자가 쉽게 트랜잭션을 관리할 수 있도록 돕습니다.
핵심 개념:
ACID 속성: 원자성, 일관성, 고립성, 지속성.
Spring의 지원: 선언적(@Transactional), 프로그래밍 방식.
전파와 격리 수준: 트랜잭션의 실행 방식을 제어.
트랜잭션 전파
🐳하나의 트랜잭션이 다른 트랜잭션 내에서 어떻게 동작할지를 결정하는 규칙으로 여러 개의 트랜잭션이 포함된 시스템에서 특정 작업이 다른 작업에 어떻게 영향을 미칠지를 정의한다.
현재 클래스의 트랜잭션과 다른 클래스의 트랜잭션을 교통정리 한다.
트랜잭션이 여러 계층 또는 메서드에서 어떻게 처리될지 정의한다.(@Transactional)
propagation 속성을 통해 트랜잭션의 동작 방식을 제어할 수 있다.
다양한 비즈니스 요구 사항에 맞춰 복잡한 트랜잭션 흐름을 유연하게 설계할 수 있도록 돕는다.
데이터 무결성과 비지니스 로직의 안정성을 보장할 수 있다.
코드 예시
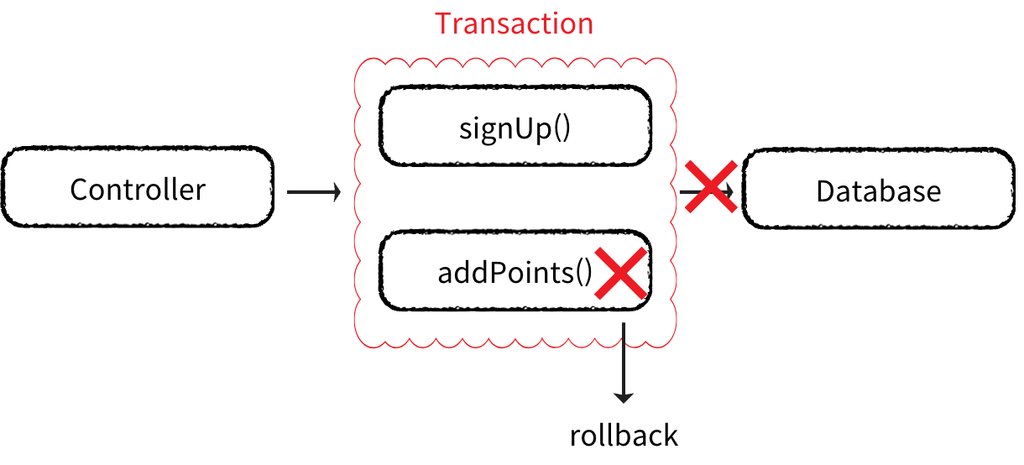
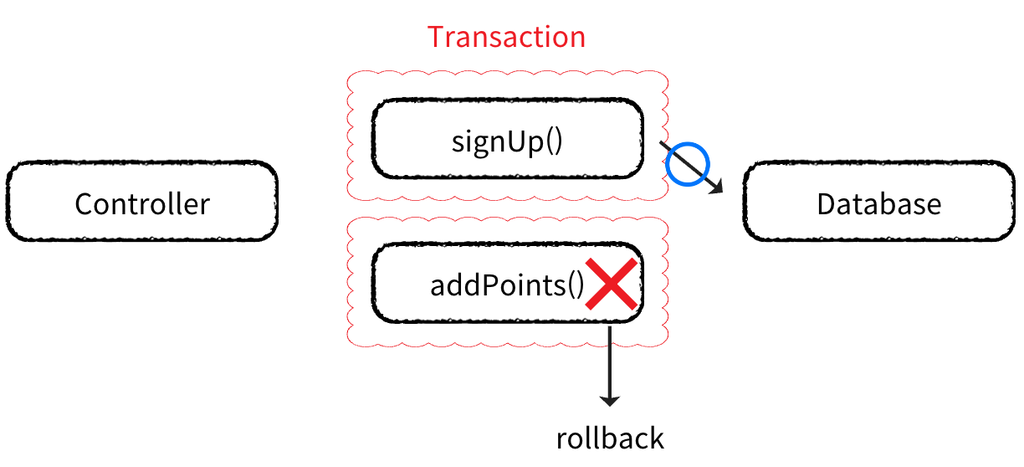
REQUIRED(Default) 사용
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
public void addPoints(Long memberId, int points) {
// 포인트 지급 로직
pointRepository.save(new Point(memberId, points));
}
}
signUp() 메서드에 @Transactional 을 통해 트랜잭션 설정
하위 addPoints() 메서드에 트랜잭션이 전파된다.
하위 메서드가 실패하면 롤백된다.
포인트 지급 로직에서 문제가 발생해도 회원 등록은 롤백된다.
트랜잭션 동작
트랜잭션 전파 종류
propagation 속성
REQUIRED(Default)
기존 트랜잭션이 있다면 기존 트랜잭션을 사용한다.
기존 트랜잭션이 없다면 트랜잭션을 새로 생성한다.
REQUIRES_NEW
항상 새로운 트랜잭션을 시작하고, 기존의 트랜잭션은 보류한다.
두 트랜잭션은 독립적으로 동작한다.
SUPPORTS
기존 트랜잭션이 있으면 해당 트랜잭션을 사용한다.
기존 트랜잭션이 없으면 트랜잭션 없이 실행한다.
NOT_SUPPORTED
기존 트랜잭션이 있어도 트랜잭션을 중단하고 트랜잭션 없이 실행된다.
MANDATORY
기존 트랜잭션이 반드시 있어야한다.
트랜잭션이 없으면 실행하지 않고 예외를 발생시킨다.
NEVER
트랜잭션 없이 실행되어야 한다.
트랜잭션이 있으면 예외를 발생시킨다.
NESTED
현재 트랜잭션 내에서 중첩 트랜잭션을 생성한다.
중첩 트랜잭션은 독립적으로 롤백할 수 있다.
기존 트랜잭션이 Commit되면 중첩 트랜잭션도 Commit 된다.
REQUIRES_NEW
회원 가입과 동시에 회원에게 포인트를 지급해야 하는 경우
@Service
@RequiredArgsConstructor
public class MemberService {
private final PointPolicy pointPolicy;
@Transactional
public void signUp(Member member) {
// 회원 등록
memberRepository.save(member);
// 포인트 지급
pointPolicy.addPoints(member.getId(), 100);
}
}
@Component
public class PointPolicy {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addPoints(Long memberId, int points) {
// 포인트 지급 로직
pointRepository.save(new Point(memberId, points));
}
}
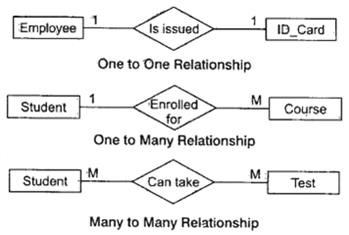
🐳 객체 간의 관계를 데이터베이스의 테이블 간의 외래 키 관계로 변환하는 과정을 의미합니다. 객체지향 언어에서는 객체 간 참조로 관계를 표현하지만, 관계형 데이터베이스에서는 외래 키를 사용하여 테이블 간 관계를 표현합니다.
1. 연관관계 매핑 종류
관계
데이터베이스 관계 설명
1:1
1:1
한 객체가 다른 객체와 1:1로 매핑됩니다.
N:1
N:1
여러 객체가 한 객체와 연결됩니다. (다수 엔티티가 하나의 엔티티를 참조)
1:N
1:N
한 객체가 여러 객체를 참조합니다. (하나의 엔티티가 다수 엔티티를 관리)
N:M
N:M
다수의 객체가 다수의 객체와 연결됩니다. (테이블에서는 중간 테이블을 사용하여 구현)
2. 연관관계 매핑 주요 어노테이션
어노테이션
설명
@OneToOne
1:1 관계를 매핑.
@OneToMany
1:N 관계를 매핑.
@ManyToOne
N:1 관계를 매핑.
@ManyToMany
N:M 관계를 매핑.
@JoinColumn
외래 키 컬럼을 명시적으로 매핑.
@JoinTable
N:M 관계에서 중간 테이블을 명시적으로 매핑.
mappedBy
연관 관계의 주인을 지정. 주인은 데이터베이스의 외래 키를 관리.
cascade
영속성 전이 전략 설정.
fetch
연관 엔티티 로딩 방식 설정 (즉시 로딩 EAGER vs 지연 로딩 LAZY).
3. 연관관계 매핑 상세
(1) @OneToOne (1:1 관계)
한 객체가 다른 객체와 1:1로 매핑.
외래 키를 어느 쪽에 설정할지 결정해야 함.
@JoinColumn으로 외래 키를 명시적으로 지정.
예제
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToOne
@JoinColumn(name = "profile_id") // 외래 키 설정
private Profile profile;
}
@Entity
public class Profile {
@Id
@GeneratedValue
private Long id;
private String bio;
}
(2) @ManyToOne (N:1 관계)
여러 객체가 하나의 객체를 참조.
관계형 데이터베이스에서 외래 키가 있는 테이블은 다(N) 쪽.
예제
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
private String product;
@ManyToOne
@JoinColumn(name = "user_id") // 외래 키 설정
private User user;
}
(3) @OneToMany (1:N 관계)
한 객체가 여러 객체를 관리.
관계형 데이터베이스에서는 다(N) 쪽이 외래 키를 관리하므로, mappedBy로 외래 키 주인을 설정해야 함.
예제
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "user") // 외래 키 관리 주인 설정
private List<Order> orders = new ArrayList<>();
}
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
private String product;
@ManyToOne
@JoinColumn(name = "user_id") // 외래 키 설정
private User user;
}
(4) @ManyToMany (N:M 관계)
다수의 객체가 다수의 객체와 연결.
관계형 데이터베이스에서는 중간 테이블을 통해 구현.
JPA에서는 @JoinTable을 사용해 중간 테이블을 정의.
예제
@Entity
public class Student {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses = new ArrayList<>();
}
@Entity
public class Course {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToMany(mappedBy = "courses") // 관계의 주인이 아님
private List<Student> students = new ArrayList<>();
}
4. mappedBy
mappedBy는 연관 관계의 주인을 설정하는 데 사용.
주인: 외래 키를 관리하는 쪽.
mappedBy 속성: 주인이 아닌 엔티티에서 주인을 지정.
예제
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "user") // Order 엔티티의 user 필드가 주인임을 지정
private List<Order> orders = new ArrayList<>();
}
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
private String product;
@ManyToOne
@JoinColumn(name = "user_id") // 외래 키 주인
private User user;
}
5. Fetch 전략
연관 관계 매핑에서 데이터 조회 시점을 설정.
FetchType.LAZY (지연 로딩):
연관된 엔티티를 실제로 사용할 때 데이터베이스에서 로드.
기본값: @OneToMany, @ManyToMany.
FetchType.EAGER (즉시 로딩):
연관된 엔티티를 즉시 로드 (JOIN 사용).
기본값: @OneToOne, @ManyToOne.
6. 연관관계 매핑 시 주의사항
단방향과 양방향 관계
단방향 관계: 한 방향으로만 참조.
양방향 관계: 양쪽 엔티티에서 서로 참조.
mappedBy 설정
양방향 관계에서는 반드시 mappedBy를 통해 주인을 설정.
N+1 문제
지연 로딩 사용 시, 연관된 데이터가 많아지면 불필요한 쿼리가 다수 발생(N+1 문제).
해결 방법:
FETCH JOIN 사용.
배치 페치 크기 조정 (hibernate.default_batch_fetch_size).
Cascade 설정
부모 엔티티와 연관된 자식 엔티티를 함께 저장, 삭제 등 자동 관리.
7. 연관관계 매핑 요약
연관관계
설명 예제
어노테이션
1:1
한 객체가 다른 객체와 1:1로 매핑.
@OneToOne
N:1
여러 객체가 한 객체를 참조.
@ManyToOne
1:N
한 객체가 여러 객체를 관리.
@OneToMany(mappedBy = "parent")
N:M
다수의 객체가 다수의 객체와 연결.
@ManyToMany, @JoinTable
결론
JPA의 연관관계 매핑은 객체 지향적인 설계를 데이터베이스 관계형 모델에 반영할 수 있게 해줍니다. 매핑을 설정할 때는 **연관 관계의 방향성, 외래 키의 관리 주체, 성능 최적화(Fetch 전략)**를 고려하여 설계하는 것이 중요합니다.
추가적으로 궁금한 점이나 더 깊은 설명이 필요하면 언제든 말씀해주세요! 😊
상속관계 매핑
🐳 객체 지향 프로그래밍의 상속 구조를 관계형 데이터베이스 테이블에 매핑하는 방법입니다. 상속 구조를 데이터베이스에서 효율적으로 표현하기 위해 JPA는 3가지 상속 전략을 제공합니다.
1. 상속관계 매핑 전략
전략
설명
단일 테이블 전략 (SINGLE_TABLE)
부모 클래스와 자식 클래스를 하나의 테이블에 매핑.
조인 전략 (JOINED)
부모 클래스와 자식 클래스를 각각 테이블로 매핑하고 JOIN으로 조회.
테이블별 클래스 전략 (TABLE_PER_CLASS)
부모 클래스는 테이블 없이, 자식 클래스마다 개별 테이블 생성.
2. 주요 어노테이션
어노테이션
설명
@Inheritance
상속 전략을 정의. 사용 가능한 값: SINGLE_TABLE, JOINED, TABLE_PER_CLASS.
📌 JPA에서 상속관계 매핑 시 구분 컬럼(Discriminator Column)을 나타냅니다. 이는 부모 테이블이나 단일 테이블 전략에서 데이터가 어느 자식 엔티티에 해당하는지 구분하기 위해 사용됩니다. **단일 테이블 전략(SINGLE_TABLE)**과 **조인 전략(JOINED)**에서 사용됩니다.
1. dtype의 기본 동작
Discriminator Column (dtype)
부모 테이블에 추가되는 컬럼으로, 해당 데이터가 어느 자식 클래스에 해당하는지를 나타냄.
기본 이름은 **dtype**이며, 값을 통해 엔티티를 구분.
기본값:
컬럼 이름: dtype
컬럼 타입: VARCHAR
자식 클래스 이름이 값으로 설정됨.
Discriminator Value (@DiscriminatorValue)
특정 자식 엔티티가 구분 컬럼에서 가질 값을 지정.
기본값은 자식 클래스의 이름.
2. dtype 기본 설정
(1) 기본 설정 예제
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE) // 단일 테이블 전략
@DiscriminatorColumn(name = "dtype") // 구분 컬럼 이름 설정
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
}
@Entity
@DiscriminatorValue("B") // dtype 값 설정
public class Book extends Item {
private String author;
}
@Entity
@DiscriminatorValue("M") // dtype 값 설정
public class Movie extends Item {
private String director;
}
(2) 생성된 테이블 구조
Item (부모) 테이블ID NAME AUTHOR DIRECTOR DTYPE
1
Book 1
Author A
NULL
B
2
Movie 1
NULL
Director A
M
3. @DiscriminatorColumn
구분 컬럼 정의 어노테이션으로 부모 클래스에 설정.
속성:
name: 구분 컬럼의 이름을 지정 (기본값: dtype).
length: 구분 컬럼의 길이 (기본값: 31).
discriminatorType: 구분 컬럼의 데이터 타입을 설정 (기본값: DiscriminatorType.STRING).
DiscriminatorType.STRING: 문자열 값 (기본값).
DiscriminatorType.CHAR: 단일 문자 값.
DiscriminatorType.INTEGER: 정수 값.
사용 예시
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "item_type", discriminatorType = DiscriminatorType.STRING, length = 10)
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
}
4. @DiscriminatorValue
자식 클래스에서 구분 컬럼의 값을 명시적으로 설정.
설정하지 않으면 자식 클래스의 이름이 기본값으로 사용됨.
사용 예시
@Entity
@DiscriminatorValue("BookType") // dtype 값 설정
public class Book extends Item {
private String author;
}
@Entity
@DiscriminatorValue("MovieType") // dtype 값 설정
public class Movie extends Item {
private String director;
}
생성된 테이블
ID NAME AUTHOR DIRECTOR ITEM_TYPE
1
Book 1
Author A
NULL
BookType
2
Movie 1
NULL
Director A
MovieType
5. 기본값과 사용자 지정
기본값
사용자 지정
컬럼 이름
dtype
@DiscriminatorColumn(name = "column_name")
컬럼 타입
DiscriminatorType.STRING
DiscriminatorType.INTEGER 또는 DiscriminatorType.CHAR
구분 값
클래스 이름
@DiscriminatorValue("value")
6. Discriminator Column 전략별 동작
전략
구분 컬럼 사용 여부
구분 컬럼 위치
설명
SINGLE_TABLE (단일 테이블)
사용
부모 테이블
단일 테이블에서 dtype 컬럼으로 엔티티를 구분.
JOINED (조인 전략)
사용
부모 테이블
부모 테이블에 dtype 컬럼이 추가되어, 데이터가 어느 자식 테이블에 속하는지 구분.
TABLE_PER_CLASS
사용 안 함
없음
테이블별로 클래스가 나뉘므로 구분 컬럼이 필요 없음.
7. Discriminator 관련 주요 SQL
(1) 조회 쿼리
SELECT * FROM Item WHERE dtype = 'B';
(2) 데이터 삽입
JPA가 삽입 시 dtype 컬럼을 자동으로 설정.
8. 주의사항
구분 컬럼은 상속 전략에 따라 필수적일 수 있음:
단일 테이블(SINGLE_TABLE)과 조인 전략(JOINED)에서 필수.
데이터 타입 확인:
구분 컬럼의 데이터 타입을 명확히 지정해야 타입 불일치를 방지할 수 있음.
명시적 설정 권장:
@DiscriminatorValue를 통해 명시적으로 값을 설정하면 유지보수가 쉬워짐.
테이블별 클래스 전략에는 사용되지 않음:
각 클래스가 독립된 테이블로 매핑되므로 dtype 컬럼이 필요하지 않음.
9. 결론
dtype은 JPA 상속 매핑에서 부모와 자식 엔티티를 구분하기 위해 매우 중요한 역할을 합니다. 특히 단일 테이블(SINGLE_TABLE)이나 조인 전략(JOINED)에서 엔티티를 명확히 구분해야 할 때 필수적입니다. 구분 컬럼과 값의 설정은 프로젝트 요구 사항에 따라 적절히 정의하는 것이 중요합니다.
추가적으로 궁금한 사항이나 더 깊은 설명이 필요하면 말씀해주세요! 😊
3. 상속 매핑 전략 상세
(1) 단일 테이블 전략 (SINGLE_TABLE)
특징:
부모 클래스와 자식 클래스의 데이터를 하나의 테이블에 저장.
상속 구조에 대한 테이블이 하나뿐이므로 성능이 좋음.
테이블 구조가 단순하지만, 많은 컬럼이 생길 수 있음(불필요한 NULL 컬럼 발생 가능).
구현 예제:
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype") // 구분 컬럼
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
}
@Entity
@DiscriminatorValue("Book") // dtype 값
public class Book extends Item {
private String author;
}
@Entity
@DiscriminatorValue("Movie") // dtype 값
public class Movie extends Item {
private String director;
}
생성된 테이블 구조:
ID
NAME
AUTHOR
DIRECTOR
DTYPE
1
Book 1
Author A
NULL
Book
2
Movie 1
NULL
Director A
Movie
(2) 조인 전략 (JOINED)
특징:
부모 클래스와 자식 클래스 각각 별도의 테이블에 저장.
조회 시 부모 테이블과 자식 테이블을 JOIN하여 데이터를 조회.
데이터 정규화로 중복을 줄이고 구조가 깔끔, 하지만 조회 시 성능이 비교적 느릴 수 있음.
구현 예제:
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
}
@Entity
public class Book extends Item {
private String author;
}
@Entity
public class Movie extends Item {
private String director;
}
생성된 테이블 구조:
부모 테이블 (Item):ID NAME
1
Book 1
2
Movie 1
자식 테이블 (Book):ID AUTHOR
1
Author A
자식 테이블 (Movie):ID DIRECTOR
2
Director A
조회 SQL:
SELECT i.*, b.*
FROM Item i
LEFT JOIN Book b ON i.id = b.id
WHERE i.id = 1;
(3) 테이블별 클래스 전략 (TABLE_PER_CLASS)
특징:
부모 클래스는 테이블을 생성하지 않고, 자식 클래스마다 독립적인 테이블을 생성.
자식 클래스별로 테이블이 독립적이므로 JOIN이 필요 없음.
중복된 컬럼이 많아질 수 있으며, 쿼리 성능이 떨어질 가능성이 있음.
구현 예제:
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
}
@Entity
public class Book extends Item {
private String author;
}
@Entity
public class Movie extends Item {
private String director;
}
생성된 테이블 구조:
자식 테이블 (Book):ID NAME AUTHOR
1
Book 1
Author A
자식 테이블 (Movie):ID NAME DIRECTOR
2
Movie 1
Director A
4. 상속 매핑 전략 비교
장점
단점
적용 사례
단일 테이블 (SINGLE_TABLE)
성능이 좋음 (한 번의 SELECT로 모든 데이터를 조회).
NULL 컬럼이 많아질 수 있음.
테이블 수를 줄이고 싶을 때.
조인 전략 (JOINED)
데이터 정규화. 중복 데이터가 없음.
조회 시 JOIN으로 인해 성능 저하 가능.
데이터 정규화가 필요할 때.
테이블별 클래스 (TABLE_PER_CLASS)
JOIN 없이 독립적으로 쿼리 가능.
중복 데이터 증가, UNION을 사용하는 조회 쿼리로 인해 성능 저하 가능.
자식 클래스별 독립적 구조가 필요할 때.
5. 상속 매핑 선택 기준
단일 테이블 전략:
테이블 수를 줄이고 싶을 때.
엔티티의 종류가 많지 않거나, NULL 컬럼이 크게 문제가 되지 않을 때.
조인 전략:
정규화된 데이터 모델을 선호하거나, 데이터 중복을 최소화해야 할 때.
데이터베이스 성능이 JOIN 쿼리를 잘 처리할 수 있을 때.
테이블별 클래스 전략:
자식 엔티티 간에 완전히 독립적인 테이블이 필요할 때.
조회 쿼리 성능이 중요한 경우 피하는 것이 좋음.
6. 상속 매핑 주의사항
추상 클래스 사용:
상위 클래스는 보통 추상 클래스로 선언하여 직접 사용하지 않도록 설계.
@Entity
public abstract class Item { }
Discriminator 컬럼:
단일 테이블 전략과 조인 전략에서는 구분 컬럼을 통해 엔티티 구분.
복잡한 상속 구조 피하기:
지나치게 깊은 상속 구조는 설계와 유지보수를 어렵게 만듦.
7. 결론
JPA의 상속 매핑은 객체지향 설계와 관계형 데이터베이스 간의 불일치를 해결하는 데 매우 유용합니다. 프로젝트의 요구사항(성능, 데이터 중복, 정규화 등)에 따라 적절한 상속 전략을 선택해야 하며, 각 전략의 장단점을 고려하여 설계하는 것이 중요합니다.
궁금한 점이나 추가적인 설명이 필요하면 언제든 말씀해주세요! 😊
JPA에서 테이블과 객체 매핑
📌 **데이터베이스의 테이블(Table)**과 **Java 객체(Entity)**를 매핑하여 객체지향적으로 데이터베이스를 사용할 수 있도록 합니다. 이를 통해 SQL을 직접 작성하지 않아도, 엔티티 객체의 필드와 테이블 컬럼 간의 변환을 자동으로 처리할 수 있습니다.
1. 테이블과 객체 매핑 기본 개념
구성 요소
설명
Entity 클래스
데이터베이스 테이블과 매핑되는 Java 클래스.
Table 어노테이션
매핑할 데이터베이스 테이블의 이름과 속성을 설정.
Column 어노테이션
엔티티의 필드를 데이터베이스의 특정 컬럼에 매핑.
Primary Key
@Id를 사용하여 기본 키(Primary Key)를 설정.
연관 관계
테이블 간의 관계(외래 키)는 @OneToOne, @OneToMany 등으로 객체 간 관계로 표현.
2. 기본 매핑 어노테이션
(1) @Entity
클래스가 JPA 엔티티임을 선언.
데이터베이스 테이블과 매핑되는 클래스.
필수 조건:
기본 생성자 필요.
@Id로 기본 키를 설정.
import jakarta.persistence.*;
@Entity // 엔티티 선언
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 기본 키 자동 생성
private Long id;
private String name; // 매핑 컬럼
private String email; // 매핑 컬럼
}
(2) @Table
엔티티와 매핑되는 데이터베이스 테이블의 이름을 지정.
속성:
name: 매핑할 테이블 이름 (기본값은 클래스 이름).
schema: 테이블이 속한 스키마 이름.
catalog: 테이블이 속한 카탈로그 이름.
uniqueConstraints: 유니크 제약 조건 설정.
@Entity
@Table(name = "users", schema = "public")
public class User {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false)
private String name;
}
GenerationType.IDENTITY: 데이터베이스의 자동 증가(AUTO_INCREMENT) 사용.
GenerationType.SEQUENCE: 데이터베이스 시퀀스를 사용해 기본 키 생성.
GenerationType.TABLE: 키 생성용 별도 테이블을 사용.
GenerationType.AUTO: 데이터베이스에 맞게 자동 선택.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
3. 테이블과 객체 매핑 예시
(1) 단순 매핑
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "user_name", nullable = false, length = 50)
private String name;
@Column(name = "user_email", unique = true)
private String email;
// 기본 생성자
public User() {}
// Getters and Setters
}
(2) 연관 관계 매핑
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne // N:1 관계
@JoinColumn(name = "user_id") // 외래 키 매핑
private User user;
private String product;
private int quantity;
}
Cascade(영속성 전이)는 JPA에서 엔티티 간의 연관관계가 있을 때, 한 엔티티의 작업(저장, 삭제 등)을 관련된 다른 엔티티에도 자동으로 전파하는 기능입니다. 이를 통해 개발자는 연관된 엔티티를 명시적으로 관리하지 않아도 되어 코드의 간결성과 유지보수성을 높일 수 있습니다.
1. Cascade의 필요성
연관된 엔티티 처리: 부모 엔티티와 연관된 자식 엔티티를 함께 저장하거나 삭제할 때, 명시적으로 각 엔티티에 대해 저장 또는 삭제를 호출하지 않고, Cascade 설정을 통해 자동으로 처리.
코드 간소화: 연관된 엔티티가 많을 경우 Cascade를 사용하면 작업을 자동화하여 코드의 복잡성을 줄임.
2. Cascade의 주요 유형
Cascade Type
설명
ALL
모든 영속성 전이 동작을 적용 (PERSIST, MERGE, REMOVE, REFRESH, DETACH).
PERSIST
엔티티 저장 시 연관된 엔티티도 함께 저장.
MERGE
엔티티 병합(수정) 시 연관된 엔티티도 함께 병합.
REMOVE
엔티티 삭제 시 연관된 엔티티도 함께 삭제.
REFRESH
엔티티 갱신 시 연관된 엔티티도 갱신.
DETACH
엔티티를 준영속(detach) 상태로 전환할 때 연관된 엔티티도 함께 준영속 상태로 전환.
3. Cascade 사용 방법
(1) Cascade 설정
Cascade는 엔티티 간 연관 관계를 매핑할 때 설정합니다.
import jakarta.persistence.*;
@Entity
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL) // Cascade 설정
private List<Child> children = new ArrayList<>();
// Getter, Setter
}
(2) Cascade 적용된 연관 엔티티 저장
Parent parent = new Parent();
parent.setName("Parent");
Child child1 = new Child();
child1.setName("Child 1");
Child child2 = new Child();
child2.setName("Child 2");
// 부모와 자식 관계 설정
parent.getChildren().add(child1);
parent.getChildren().add(child2);
child1.setParent(parent);
child2.setParent(parent);
// 부모를 저장하면 자식 엔티티도 자동으로 저장
entityManager.persist(parent);
CascadeType.PERSIST로 인해 parent를 저장하면 child1과 child2도 자동으로 저장됩니다.
4. Cascade 유형별 동작 예시
(1) PERSIST
부모 엔티티 저장 시 자식 엔티티도 함께 저장.
@OneToMany(mappedBy = "parent", cascade = CascadeType.PERSIST)
private List<Child> children = new ArrayList<>();
(2) MERGE
부모 엔티티 병합 시 자식 엔티티도 병합.
@OneToMany(mappedBy = "parent", cascade = CascadeType.MERGE)
private List<Child> children = new ArrayList<>();
(3) REMOVE
부모 엔티티 삭제 시 자식 엔티티도 삭제.
@OneToMany(mappedBy = "parent", cascade = CascadeType.REMOVE)
private List<Child> children = new ArrayList<>();
(4) ALL
모든 Cascade 동작을 포함 (PERSIST, MERGE, REMOVE, REFRESH, DETACH).
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL)
private List<Child> children = new ArrayList<>();
5. Cascade의 장점
코드 간소화
연관된 엔티티에 대해 명시적으로 작업을 호출하지 않아도 자동으로 처리 가능.
연관 데이터 일관성 유지
부모 엔티티와 연관된 자식 엔티티 간의 데이터 동기화 보장.
효율적인 관리
대량의 연관 데이터를 효율적으로 처리 가능.
6. Cascade 사용 시 주의사항
CascadeType.REMOVE 주의
부모 엔티티 삭제 시 자식 엔티티도 함께 삭제되므로, 실제 데이터 손실이 발생할 수 있음.
예: 부모-자식 관계가 아닌 연관된 다른 테이블에서 참조되는 데이터가 있다면 데이터 무결성 문제가 생길 수 있음.
CascadeType.ALL 사용
모든 영속성 전이를 포함하므로, 반드시 필요한 경우에만 사용.
잘못 사용하면 의도하지 않은 상태 변화가 발생할 수 있음.
Lazy Loading과의 충돌
연관 관계가 Lazy 로딩일 경우, Cascade 작업 시 필요 이상의 데이터가 로드될 수 있음.
7. Cascade 적용 여부 판단 기준
적용 여부
권장 상황
CascadeType.PERSIST
부모 엔티티 저장 시 자식 엔티티도 항상 저장되어야 하는 경우.
CascadeType.REMOVE
부모 엔티티 삭제 시 자식 엔티티도 항상 함께 삭제되어야 하는 경우.
CascadeType.ALL
부모와 자식 간의 모든 작업(PERSIST, REMOVE, MERGE 등)이 항상 연동되어야 하는 경우.
CascadeType.MERGE
병합 작업에서 부모와 자식 간 변경 사항이 항상 함께 반영되어야 하는 경우.
CascadeType.REFRESH
부모 갱신 시 자식 엔티티의 상태도 항상 동기화가 필요할 경우.
CascadeType.DETACH
부모와 자식을 동시에 준영속 상태로 전환할 필요가 있는 경우.
8. Cascade 설정의 실용적 예제
부모-자식 관계 (부모와 자식 삭제 동작)
@Entity
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Child> children = new ArrayList<>();
}
@Entity
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
JPA의 Cascade는 엔티티 간의 연관 관계에서 작업을 전이시켜 개발 생산성을 높이고, 일관된 데이터 관리를 가능하게 합니다. 그러나 모든 작업에서 Cascade를 사용하는 것은 권장되지 않으며, 특정 상황에 적합한 Cascade 타입을 선택해 사용하는 것이 중요합니다. 😊
orphanRemoval (고아 객체 제거)
부모-자식 관계에서 **부모 엔티티와의 연관 관계가 제거된 자식 엔티티(고아 객체)**를 데이터베이스에서 자동으로 삭제해주는 설정입니다. 이를 통해 연관 관계가 없는 자식 데이터를 자동으로 정리할 수 있어 데이터 무결성을 유지하고 개발자의 부담을 줄여줍니다.
1. orphanRemoval의 기본 개념
고아 객체: 부모 엔티티와의 연관 관계가 끊어진 자식 엔티티.
기능: 부모 엔티티에서 자식 엔티티를 컬렉션에서 제거하거나 관계를 끊으면, JPA가 해당 자식 엔티티를 데이터베이스에서 삭제.
작동 방식: 부모-자식 관계의 컬렉션에서 자식 엔티티를 제거하거나, null로 설정했을 때 자동으로 DELETE SQL 실행.
2. 사용 방법
@OneToMany 또는 @OneToOne 관계에서 사용 가능.
orphanRemoval = true 속성을 지정하면 고아 객체를 자동으로 제거.
예제: 부모-자식 관계 설정
@Entity
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Child> children = new ArrayList<>();
// Helper method to manage bidirectional relationship
public void addChild(Child child) {
children.add(child);
child.setParent(this);
}
public void removeChild(Child child) {
children.remove(child);
child.setParent(null);
}
}
@Entity
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
orphanRemoval 동작 예시
// 부모 엔티티 생성
Parent parent = new Parent();
parent.setName("Parent");
// 자식 엔티티 생성 및 관계 설정
Child child1 = new Child();
child1.setName("Child 1");
Child child2 = new Child();
child2.setName("Child 2");
parent.addChild(child1);
parent.addChild(child2);
entityManager.persist(parent); // Parent와 Child가 모두 저장
// 부모 엔티티에서 자식 엔티티 제거
parent.removeChild(child1);
entityManager.flush(); // flush() 시점에 child1에 대한 DELETE SQL 실행
3. orphanRemoval 동작 방식
상황 동작
부모 컬렉션에서 자식 제거
자식 엔티티를 부모 컬렉션에서 삭제하면, 해당 자식은 데이터베이스에서도 삭제.
자식의 부모 관계 해제 (null)
자식 엔티티의 부모 관계를 null로 설정하면, 자식은 고아 객체로 간주되어 삭제.
예시: 관계 해제 후 삭제
child1.setParent(null); // 부모 관계 해제
entityManager.flush(); // flush 시점에 DELETE SQL 실행
부모-자식 관계에서 자식 엔티티가 많으면, 삭제 작업으로 인해 성능에 영향을 줄 수 있음.
N:1 관계에서는 사용 불가
orphanRemoval은 @OneToMany 또는 @OneToOne에서만 사용할 수 있으며, @ManyToOne에서는 지원하지 않음.
7. 결론
**orphanRemoval**은 JPA에서 부모-자식 관계를 다룰 때, 부모와의 연관이 끊어진 고아 객체를 자동으로 삭제해주는 강력한 기능입니다. 데이터 무결성을 유지하고 개발자의 작업을 줄이는 데 유용하지만, 관계와 삭제 조건을 명확히 이해하고 사용해야 예상치 못한 데이터 삭제를 방지할 수 있습니다. 😊
추가로 궁금한 점이 있다면 알려주세요!
Fetch (조회 시점)
엔티티 간의 연관 관계에서 데이터를 언제 조회할지를 결정하는 전략을 의미합니다. JPA는 @OneToOne, @OneToMany, @ManyToOne, @ManyToMany와 같은 연관 관계를 매핑할 때 **지연 로딩(Lazy Loading)**과 즉시 로딩(Eager Loading) 방식을 제공합니다.
Fetch 전략의 종류
전략 설명
즉시 로딩
연관된 엔티티를 즉시 조회. 부모 엔티티를 조회할 때 연관된 자식 엔티티를 함께 가져옴.
지연 로딩
연관된 엔티티를 필요할 때 조회. 부모 엔티티만 먼저 조회하고, 자식 엔티티는 실제로 접근할 때 로딩.
1. Fetch 전략 설정
Fetch 전략은 연관 관계 매핑 애너테이션에서 fetch 속성을 사용해 설정합니다.
1) 즉시 로딩 (EAGER)
연관된 엔티티를 즉시 조회.
부모 엔티티를 조회할 때, 연관된 자식 엔티티를 JOIN으로 한 번에 가져옴.
기본값:
@OneToOne, @ManyToOne 관계에서 즉시 로딩이 기본값.
설정 예시
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "user_id")
private User user;
2) 지연 로딩 (LAZY)
연관된 엔티티를 필요할 때 조회.
부모 엔티티만 먼저 로드하고, 자식 엔티티는 실제로 접근하는 시점에 별도의 쿼리로 가져옴.
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.EAGER) // 즉시 로딩 설정
@JoinColumn(name = "user_id")
private User user;
}
em.find(Order.class, 1L) 실행 시, Order와 연관된 User를 한 번의 JOIN 쿼리로 가져옵니다.
실행 쿼리 (즉시 로딩)
SELECT o.*, u.*
FROM orders o
LEFT JOIN users u ON o.user_id = u.id
WHERE o.id = 1;
(2) 지연 로딩
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY) // 지연 로딩 설정
@JoinColumn(name = "user_id")
private User user;
}
em.find(Order.class, 1L) 실행 시, Order만 조회되고, User는 로드되지 않습니다.
order.getUser() 호출 시점에 User를 조회하는 쿼리가 실행됩니다.
실행 쿼리 (지연 로딩)
부모 엔티티 조회:
SELECT * FROM orders WHERE id = 1;
연관된 자식 엔티티 조회:
SELECT * FROM users WHERE id = ?;
4. N+1 문제
지연 로딩을 사용할 때, 부모 엔티티를 조회하고 각 자식 엔티티를 조회하는 쿼리가 추가로 발생하여 성능 저하.
예: 부모 엔티티 1개와 자식 엔티티 N개를 조회하는 경우 N+1개의 쿼리가 실행.
예시
List<Order> orders = em.createQuery("SELECT o FROM Order o", Order.class).getResultList();
for (Order order : orders) {
System.out.println(order.getUser().getName()); // 각 User를 조회할 때마다 쿼리 실행
}
해결 방법
JPQL의 FETCH JOIN 사용
필요한 데이터를 한 번의 쿼리로 가져옴.
List<Order> orders = em.createQuery(
"SELECT o FROM Order o JOIN FETCH o.user", Order.class).getResultList();
Batch Fetch 크기 조정
Hibernate 설정에서 Batch Fetch를 사용해 N+1 문제를 완화.
hibernate.default_batch_fetch_size=10
5. Fetch 전략 선택 기준
상황 추천
Fetch 전략
연관된 엔티티를 항상 함께 사용해야 할 때
즉시 로딩 (EAGER)
연관된 엔티티를 사용할 가능성이 적을 때
지연 로딩 (LAZY)
데이터가 많고, 관계를 자주 조회해야 할 때
지연 로딩 (LAZY) + FETCH JOIN
6. 즉시 로딩과 지연 로딩의 기본값
연관 관계 기본
Fetch 전략
@OneToOne
즉시 로딩 (EAGER)
@ManyToOne
즉시 로딩 (EAGER)
@OneToMany
지연 로딩 (LAZY)
@ManyToMany
지연 로딩 (LAZY)
7. 결론
즉시 로딩 (EAGER): 항상 연관 데이터를 함께 사용해야 하거나, 관계가 단순한 경우 적합.
지연 로딩 (LAZY): 성능과 메모리 효율을 위해 기본적으로 추천되며, 필요 시 FETCH JOIN으로 최적화.
Fetch 전략은 애플리케이션의 데이터 접근 패턴과 성능 요구 사항에 따라 신중하게 설정해야 합니다. N+1 문제와 Lazy Loading 설계에 주의하며, 적절한 시점에 데이터를 로딩하는 방식으로 성능 최적화를 도모할 수 있습니다. 😊
- 영속성 컨텍스트가 관리. - 변경 감지(Dirty Checking)로 변경 사항 자동 반영.
em.persist(entity)
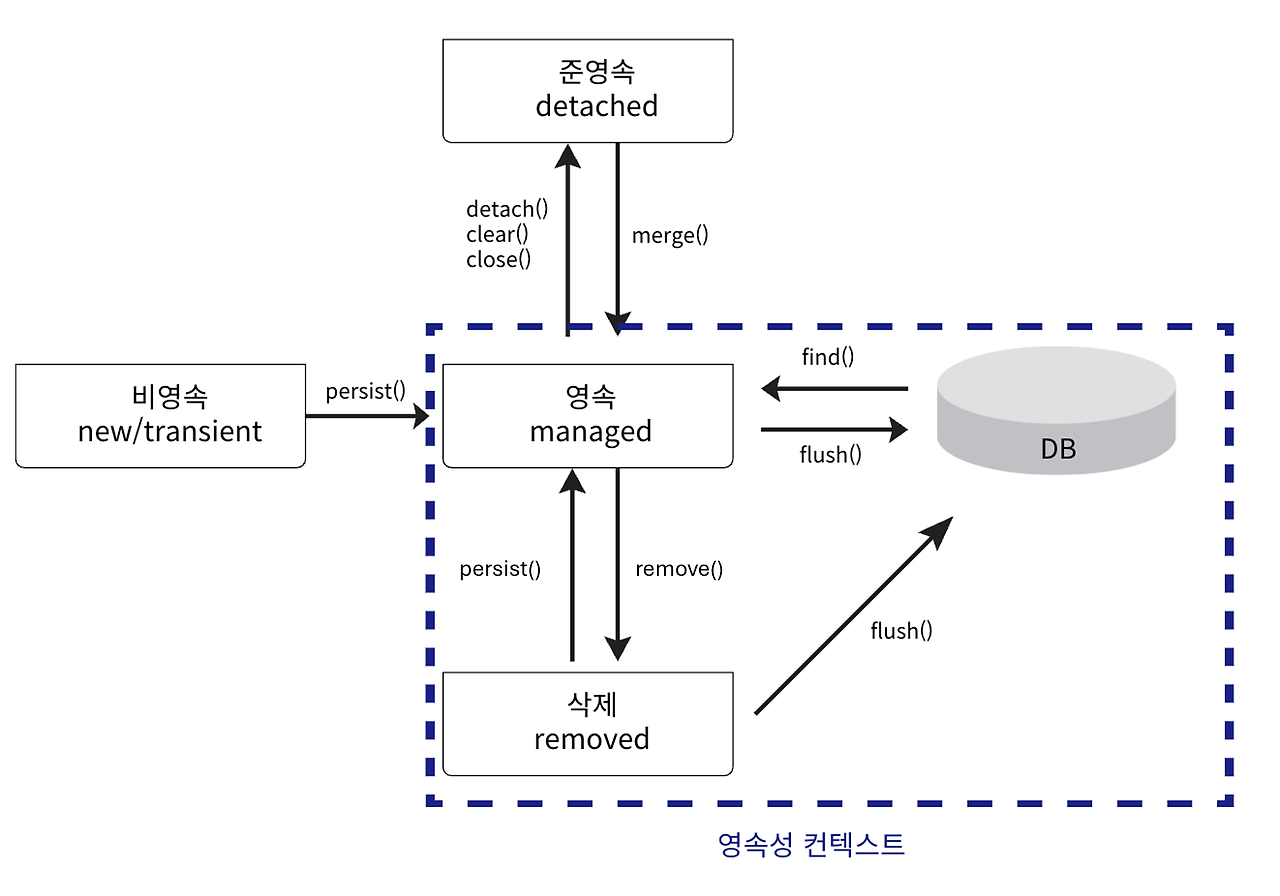
준영속 (Detached)
한때 영속 상태였지만 영속성 컨텍스트에서 분리된 상태. 데이터베이스와 동기화되지 않음.
주민등록 말소 상태
- 영속성 컨텍스트와 연결 끊김. - 변경 사항이 데이터베이스에 반영되지 않음.
em.detach(entity), em.clear(), em.close()
삭제 (Removed)
영속성 컨텍스트에 의해 삭제로 표시된 상태. 트랜잭션 완료 시 데이터베이스에서 제거됨.
사망신고 상태
- 영속성 컨텍스트에 의해 삭제로 표시. - 트랜잭션 완료 시 데이터베이스에서 완전히 삭제.
em.remove(entity)
상태 전환 흐름 예시
상태 전환
설명
비영속 → 영속
em.persist(entity) 호출 시.
영속 → 준영속
em.detach(entity) 또는 em.clear() 호출 시.
영속 → 삭제
em.remove(entity) 호출 후 트랜잭션 완료 시.
상태 전환 주요 코드 예시
비영속 상태
User user = new User(); // 비영속 user.setName("John");
영속 상태로 전환
em.persist(user); // 영속 상태
준영속 상태로 전환
em.detach(user); // 준영속 상태
삭제 상태로 전환
em.remove(user); // 삭제 상태 em.getTransaction().commit(); // 데이터베이스에서 제거
영속성 컨텍스트 (Persistence Context)
📌 JPA에서 엔티티(Entity)를 관리하는 일종의 메모리 공간으로, 애플리케이션과 데이터베이스 사이의 중간 계층 역할을 합니다. 엔티티 객체의 상태를 관리하고, 데이터베이스와 동기화하며, 데이터 변경 사항을 추적합니다.
1. 영속성 컨텍스트의 주요 개념
항목
설명
정의
엔티티를 저장하고 관리하며, 엔티티 객체와 데이터베이스 간의 중개자 역할을 하는 메모리 공간.
EntityManager와 관계
EntityManager를 통해 영속성 컨텍스트에 접근하고 관리.
엔티티 생명주기
엔티티 객체의 상태(비영속, 영속, 준영속, 삭제)를 관리.
1차 캐시
영속성 컨텍스트 내부에 저장된 엔티티 객체를 캐싱하여 동일 엔티티를 중복 조회하지 않음.
변경 감지 (Dirty Checking)
영속성 컨텍스트에 의해 관리되는 엔티티의 변경 사항을 감지하여 자동으로 데이터베이스에 반영.
2. 영속성 컨텍스트의 주요 기능
(1) 1차 캐시
영속성 컨텍스트 내부에 엔티티 객체를 캐싱하여 관리.
동일한 식별자를 가진 엔티티를 여러 번 조회할 경우, 데이터베이스를 재조회하지 않고 1차 캐시에서 반환.
// 첫 번째 조회 -> 데이터베이스에서 조회 후 1차 캐시에 저장
User user1 = em.find(User.class, 1L);
// 두 번째 조회 -> 1차 캐시에서 반환 (SQL 실행되지 않음)
User user2 = em.find(User.class, 1L);
System.out.println(user1 == user2); // true
(2) 엔티티 동일성 보장
동일한 트랜잭션 내에서는 같은 식별자를 가진 엔티티 객체는 **동일성 (==)**을 보장.
User user1 = em.find(User.class, 1L);
User user2 = em.find(User.class, 1L);
System.out.println(user1 == user2); // true (동일 객체)
(3) 변경 감지 (Dirty Checking)
영속성 컨텍스트는 관리 중인 엔티티의 변경 사항을 감지하고, 트랜잭션 커밋 시 자동으로 데이터베이스에 반영.
User user = em.find(User.class, 1L); // 영속 상태
user.setName("Updated Name"); // 엔티티 수정 (Dirty Checking 발생)
em.getTransaction().commit(); // UPDATE 쿼리 실행
(4) 쓰기 지연 (Write-Behind)
엔티티 변경 작업(INSERT, UPDATE, DELETE)은 즉시 실행되지 않고, 쓰기 지연 저장소에 SQL이 누적된 후 트랜잭션 커밋 시점에 한꺼번에 실행.
User user = new User();
user.setName("John");
em.persist(user); // INSERT SQL이 즉시 실행되지 않고 쓰기 지연 저장소에 저장
em.getTransaction().commit(); // INSERT SQL 실행
(5) 지연 로딩 (Lazy Loading) 지원
연관된 엔티티를 필요할 때 로드하는 지연 로딩을 지원.
User user = em.find(User.class, 1L); // User만 조회
List<Order> orders = user.getOrders(); // 이 시점에 Order 조회 쿼리 실행
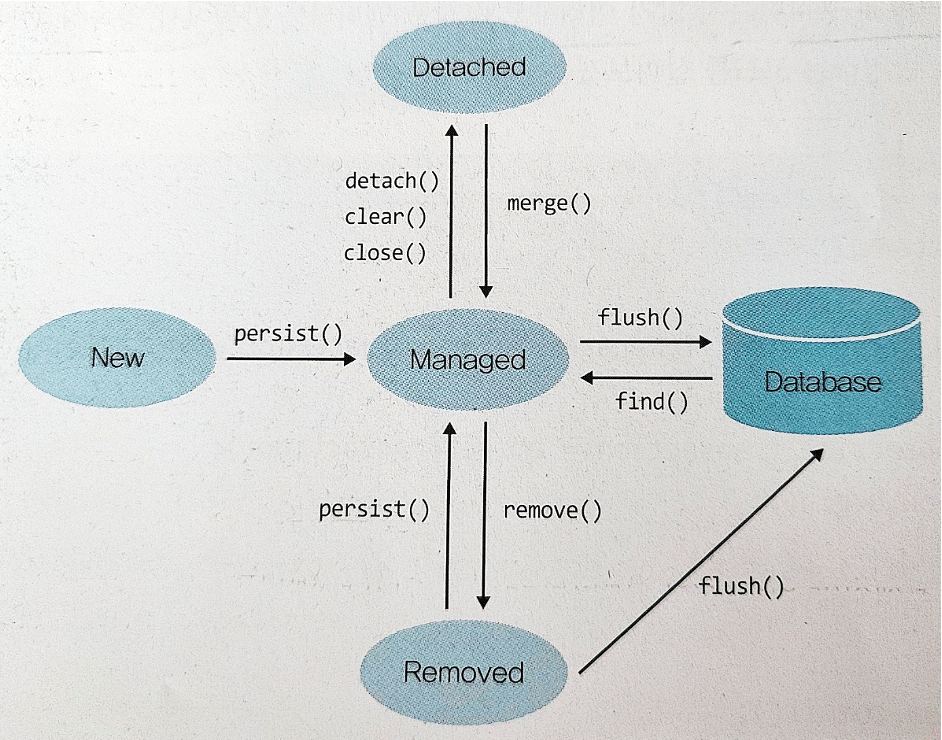
3. 엔티티 생명주기
상태
설명
전환 방법
비영속 (New)
영속성 컨텍스트와 관계없는 상태. 데이터베이스와 연관되지 않음.
new Entity()
영속 (Managed)
영속성 컨텍스트에 저장되어 관리되는 상태. 데이터베이스와 동기화 가능.
em.persist(entity) 또는 em.find()
준영속 (Detached)
한때 영속 상태였지만, 현재는 영속성 컨텍스트에서 분리된 상태. 데이터베이스와 동기화되지 않음.
em.detach(entity), em.clear(), em.close()
삭제 (Removed)
삭제 상태로 표시되어 트랜잭션 커밋 시 데이터베이스에서 제거됨.
em.remove(entity)
4. 영속성 컨텍스트의 동작 방식
(1) 엔티티 저장
영속성 컨텍스트에 엔티티를 저장하고 관리.
em.persist(entity) 호출 시 영속 상태로 전환.
(2) 엔티티 조회
em.find() 호출 시, 영속성 컨텍스트의 1차 캐시에서 먼저 조회.
1차 캐시에 없으면 데이터베이스에서 조회 후 1차 캐시에 저장.
(3) 변경 내용 반영
영속 상태의 엔티티가 변경되면 변경 감지를 통해 자동으로 데이터베이스에 반영.
(4) 트랜잭션 커밋
쓰기 지연 저장소의 SQL을 한꺼번에 실행하고 트랜잭션을 종료.
5. 영속성 컨텍스트의 활용 예시
기본 사용 흐름
EntityManagerFactory emf = Persistence.createEntityManagerFactory("example-unit");
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin();
try {
// 엔티티 저장 (비영속 → 영속)
User user = new User();
user.setName("John");
em.persist(user);
// 엔티티 조회 (1차 캐시 사용)
User foundUser = em.find(User.class, user.getId());
// 엔티티 수정 (Dirty Checking)
foundUser.setName("Updated Name");
// 트랜잭션 커밋 (쓰기 지연 SQL 실행)
transaction.commit();
} catch (Exception e) {
transaction.rollback();
} finally {
em.close();
}
emf.close();
6. 영속성 컨텍스트의 장점
1차 캐시로 성능 최적화
동일 트랜잭션 내에서 중복 조회를 방지.
변경 감지로 데이터 자동 반영
코드의 단순화 및 일관성 유지.
쓰기 지연으로 효율적 SQL 처리
트랜잭션 커밋 시점에 한 번에 SQL 실행.
데이터 일관성 보장
동일성 보장(==)으로 엔티티 간의 데이터 충돌 방지.
7. 영속성 컨텍스트 사용 시 주의사항
(1) 메모리 사용량 증가
영속성 컨텍스트에 관리 중인 엔티티가 많아질 경우 메모리 사용량이 증가할 수 있음.
해결 방법:
em.clear() 또는 em.detach(entity)로 필요하지 않은 엔티티를 준영속 상태로 전환.
(2) LazyInitializationException
지연 로딩 사용 시, 트랜잭션이 종료된 상태에서 프록시 객체 접근 시 오류 발생.
해결 방법:
트랜잭션 내에서 데이터를 모두 로드하거나, FETCH JOIN 사용.
(3) 쓰기 지연의 데이터 충돌
쓰기 지연으로 인해 트랜잭션 종료 시점에 SQL 실행 중 충돌 가능.
해결 방법:
중요한 작업 시 명시적 flush() 호출.
8. 결론
영속성 컨텍스트는 JPA에서 핵심적인 역할을 하며, 데이터의 상태를 관리하고 성능 최적화를 지원합니다. 하지만, 이를 효율적으로 활용하기 위해 N+1 문제, Lazy Loading, 메모리 사용량 등 주의점을 고려해야 합니다. 설계와 구현 단계에서 영속성 컨텍스트의 동작을 명확히 이해하고 사용하는 것이 중요합니다.
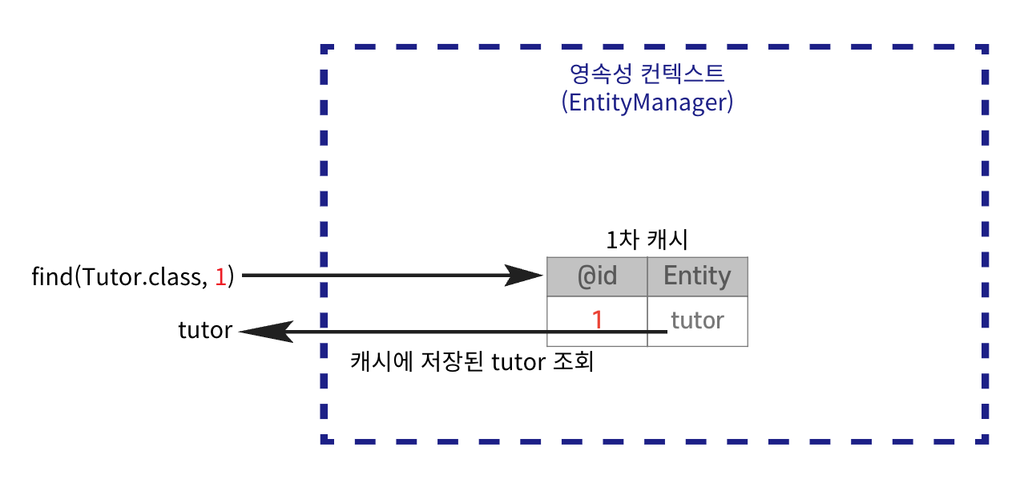
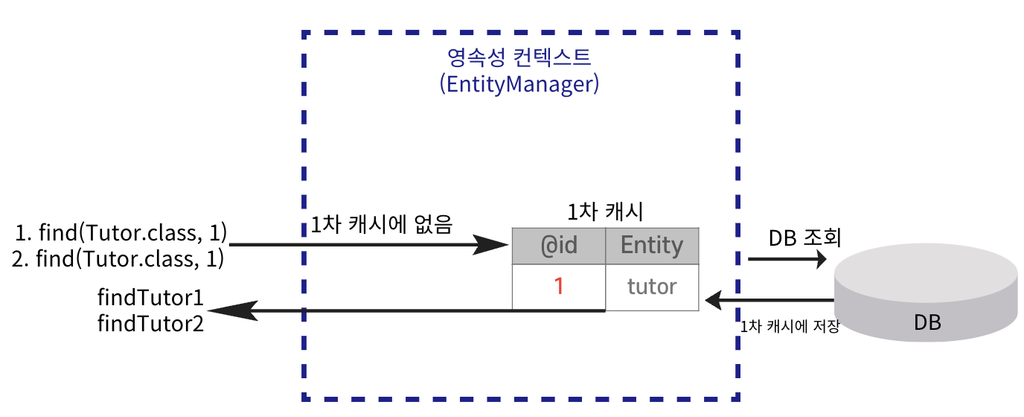
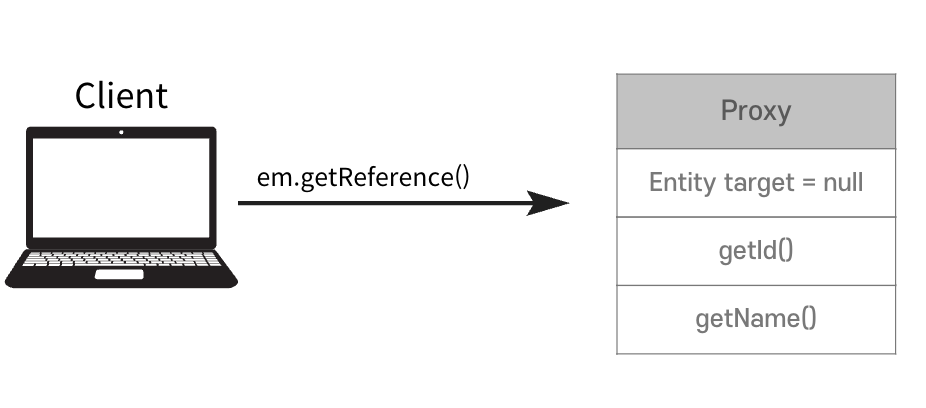
1차 캐시
📌엔티티를 영속성 컨텍스트에 저장할 때 생성되는 메모리 내 캐시이다. 엔티티는 먼저 1차 캐시에 저장되고 이후 같은 엔티티를 요청하면 DB를 조회하지 않고 1차 캐시에서 데이터를 반환하여 성능을 높일 수 있다.
// 비영속
Tutor tutor = new Tutor(1L, "wonuk", 100);
// 영속, 1차 캐시에 저장
em.persist(tutor);
영속된 Entity 조회
Database가 아닌 1차 캐시에 저장된 Entity를 먼저 조회한다.
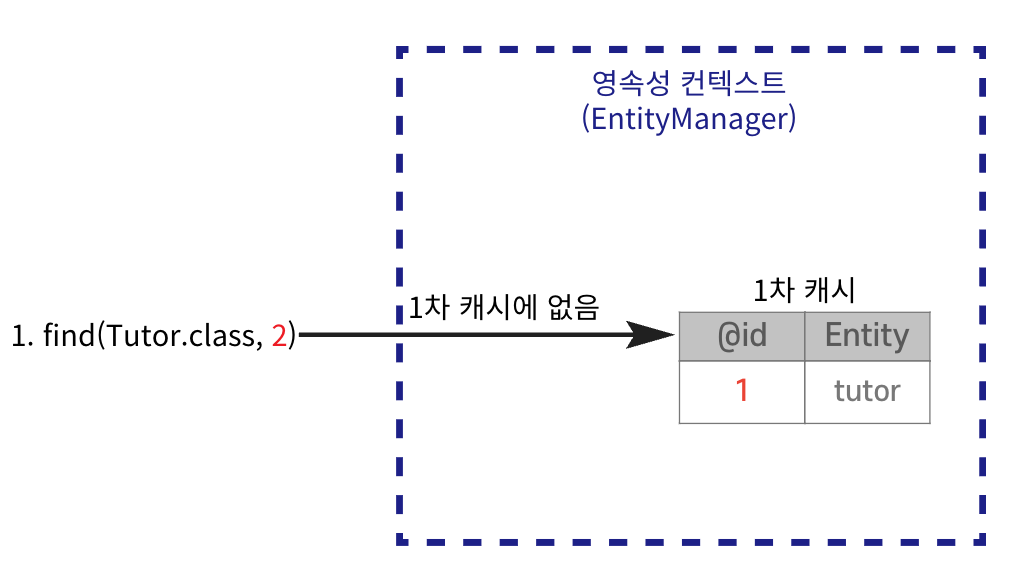
// 1차 캐시에서 조회
Tutor findTutor = em.find(Tutor.class, 1L);
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
// 비영속
Tutor tutor = new Tutor(1L, "wonuk", 100);
// 영속
System.out.println("persist 전");
em.persist(tutor);
System.out.println("persist 후");
Tutor findTutor = em.find(Tutor.class, 1L);
System.out.println("findTutor.getId() = " + findTutor.getId());
System.out.println("findTutor.getName() = " + findTutor.getName());
System.out.println("findTutor.getAge() = " + findTutor.getAge());
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
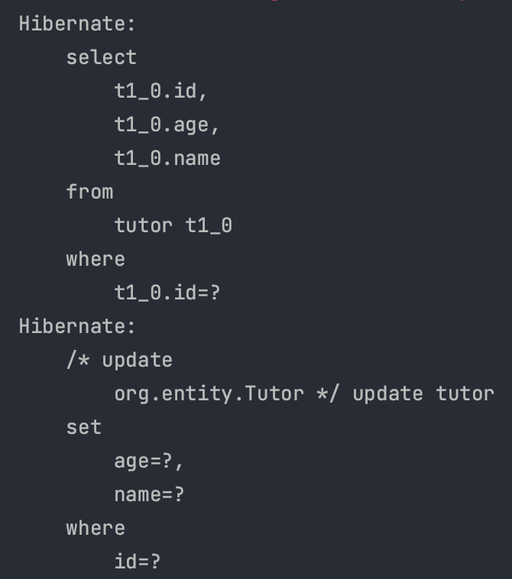
z
실행결과
1차 캐시의 Entity를 조회한다.
조회 SQL이 실행되지 않는다.
트랜잭션 Commit 시점에 INSERT SQL이 실행된다.
**트랜잭션(Transaction)**은 데이터베이스 작업에서데이터의 일관성, 무결성을 보장하기 위해 논리적으로 묶여있는 작업 단위를 의미합니다.
데이터베이스에 저장된 데이터 조회
1차 캐시는 동일한 트랜잭션 안에서만 사용이 가능하다.
요청이 들어오고 트랜잭션이 종료되면 영속성 컨텍스트는 삭제된다.
동일성 보장
📌동일한 트랜잭션 안에서 특정 엔티티를 여러 번 조회해도 항상 같은 객체 인스턴스를 반환한다. 영속성 컨텍스트는 1차 캐시를 사용하여 같은 엔티티를 중복 조회해도 동일한 객체를 참조하게 하여 일관성을 유지한다.
동일한 트랜잭션 내에서 조회된 Entity는 같은 인스턴스를 반환한다.
DB에 저장된 데이터를 조회하여 1차 캐시에 저장한다.
1차 캐시에 저장된 데이터를 조회한다.
JPA의 동일성 보장 (Identity)
JPA에서 동일성(Identity)은 영속성 컨텍스트가 같은 엔티티 객체를 하나만 관리하여, 동일한 엔티티를 여러 번 조회해도 항상 같은 객체를 반환하는 특성을 의미합니다. 이를 통해 객체 간의 일관성과 효율적인 데이터 관리가 가능합니다.
주요 개념
구분
설명
동일성 보장
동일한 트랜잭션 내에서 같은 엔티티는 동일한 객체(instance)로 관리.
비교 방식
- 동일성(identity): == 연산자를 사용해 객체가 동일한 인스턴스인지 비교.- 동등성(equality): .equals() 메서드를 사용해 논리적으로 같은 값인지 비교.
영속성 컨텍스트
동일성 보장이 가능한 이유는 영속성 컨텍스트가 엔티티를 1차 캐시에 저장하고 관리하기 때문.
1차 캐시
- 영속성 컨텍스트 내부에 엔티티 객체를 저장하는 메모리 공간.- 동일한 엔티티를 조회할 경우 1차 캐시에서 반환하므로 동일성을 보장.
동일성 보장의 동작 방식
동일 엔티티를 조회할 때 동일 객체 반환
같은 트랜잭션 안에서 같은 식별자(@Id)를 가진 엔티티를 조회하면 영속성 컨텍스트의 1차 캐시에 있는 동일 객체를 반환.
User user1 = em.find(User.class, 1L); // 첫 번째 조회
User user2 = em.find(User.class, 1L); // 두 번째 조회
System.out.println(user1 == user2); // true (동일 객체)
변경 감지(Dirty Checking)와의 연계
동일 객체가 관리되므로 변경 사항은 영속성 컨텍스트를 통해 자동 감지되고 데이터베이스에 반영.
user1.setName("Updated Name");
// 트랜잭션 커밋 시, 변경 내용이 데이터베이스에 자동 반영.
다른 트랜잭션에서는 동일성 보장 불가
트랜잭션이 다르면 영속성 컨텍스트가 다르므로 동일 객체로 관리되지 않음.
User user1 = em1.find(User.class, 1L); // 첫 번째 트랜잭션
User user2 = em2.find(User.class, 1L); // 두 번째 트랜잭션
System.out.println(user1 == user2); // false (다른 트랜잭션, 다른 객체)
동일성과 동등성 비교
비교 기준
동일성 (Identity)
동등성 (Equality)
비교 방식
== 연산자로 비교
.equals() 메서드로 비교
비교 목적
같은 객체인지 확인
논리적으로 같은 데이터인지 확인
사용 예시
동일 엔티티인지 확인 (JPA에서 중요)
엔티티 내용의 동등성 확인
JPA 보장 여부
영속성 컨텍스트에서 보장
사용자 정의 메서드로 구현 필요
동일성 보장의 장점
데이터 일관성 유지
동일 엔티티를 변경하면 모든 참조 객체가 동일하게 반영.
성능 최적화
동일 엔티티를 여러 번 조회해도 데이터베이스를 다시 조회하지 않고 1차 캐시 사용.
관리의 편리성
영속성 컨텍스트가 엔티티의 생명주기를 관리하여 복잡성을 줄임.
주의 사항 및 한계
트랜잭션 범위 제한
동일성 보장은 같은 영속성 컨텍스트 내에서만 유효.
Lazy Loading 주의
프록시 객체를 사용할 경우 == 연산이 예상대로 동작하지 않을 수 있음.
1차 캐시 메모리 관리
1차 캐시가 크면 메모리 사용량 증가 및 성능 저하 가능.
결론
JPA의 동일성 보장은 객체 지향적 데이터 관리를 가능하게 하고, 데이터 일관성을 유지하며, 성능을 최적화하는 데 중요한 역할을 합니다. 그러나 트랜잭션과 영속성 컨텍스트 범위에 따라 보장이 달라지므로, 이를 이해하고 활용하는 것이 중요합니다. 😊
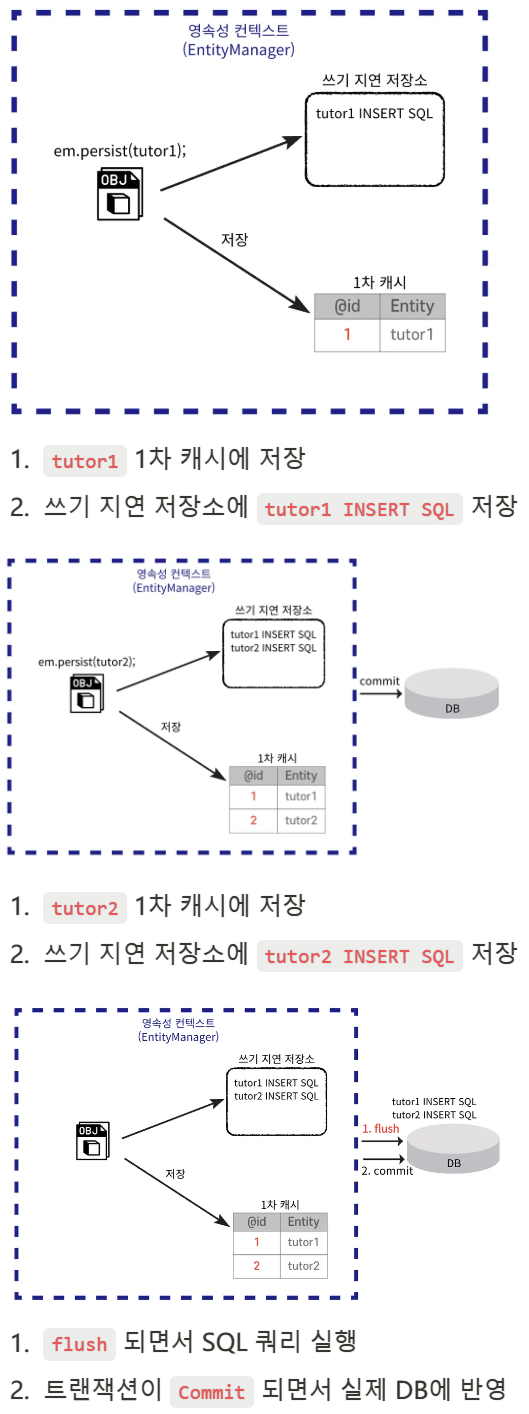
쓰기 지연
📌 엔티티 객체의변경 사항을 DB에 바로 반영하지 않고 트랜잭션이 커밋될 때 한 번에 반영하는 방식으로 이를 통해 성능을 최적화하고 트랜잭션 내에서의 불필요한 DB 쓰기 작업을 최소화한다.
JPA의쓰기 지연 (Write-Behind, Write-Delay)
쓰기 지연은 JPA에서 영속성 컨텍스트(Persistence Context)가 엔티티 매니저를 통해 데이터베이스와 직접 상호작용하지 않고, 내부 버퍼(쓰기 지연 저장소)에 변경 내역(SQL)을 저장한 후트랜잭션이 커밋될 때 한꺼번에 데이터베이스에 반영하는 전략을 의미합니다. 이를 통해 성능 최적화와 효율적인 데이터베이스 처리 작업이 가능합니다.
주요 동작 원리
엔티티 변경 감지
영속성 컨텍스트에서 관리 중인 엔티티의 상태를 지속적으로 감지.
변경된 엔티티는 내부 쓰기 지연 저장소에 기록됨.
쓰기 지연 저장소에 SQL 누적
INSERT, UPDATE, DELETE와 같은 SQL 명령문이 즉시 실행되지 않고 저장소에 보관.
트랜잭션 커밋 시점에 SQL 실행
트랜잭션이 commit될 때 누적된 SQL을 데이터베이스에 한꺼번에 전달하여 실행.
쓰기 지연 동작 예시
코드 예제
EntityManagerFactory emf = Persistence.createEntityManagerFactory("example-unit");
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin(); // 트랜잭션 시작
try {
// 1. 엔티티 생성 및 영속성 컨텍스트 등록
User user1 = new User();
user1.setName("John");
em.persist(user1); // INSERT SQL 생성 (쓰기 지연 저장소에 저장)
User user2 = new User();
user2.setName("Jane");
em.persist(user2); // 또 다른 INSERT SQL 생성 (쓰기 지연 저장소에 저장)
// 2. 트랜잭션 커밋
transaction.commit(); // SQL이 한꺼번에 실행 (INSERT 문 두 개)
} catch (Exception e) {
transaction.rollback(); // 오류 발생 시 롤백
} finally {
em.close();
}
emf.close();
주요 동작 흐름
em.persist(user1) 및 em.persist(user2) 호출 시, INSERT 문은 바로 실행되지 않고 쓰기 지연 저장소에 보관.
transaction.commit() 호출 시점에 누적된 INSERT 문이 한꺼번에 실행.
결과적으로 데이터베이스에 INSERT가 발생.
쓰기 지연의 장점
성능 최적화
여러 SQL 명령을 한꺼번에 전송하여 데이터베이스 통신 횟수를 줄임.
배치 작업과 함께 사용하면 더 큰 성능 향상 가능.
트랜잭션 관리의 일관성
트랜잭션 종료 시 SQL 실행이 보장되어 데이터 무결성 유지.
효율적인 자원 사용
데이터베이스 연결 자원을 효율적으로 사용하며, 불필요한 SQL 실행을 방지.
쓰기 지연 주의점
트랜잭션 커밋 전 SQL 실행되지 않음
영속성 컨텍스트의 변경 사항은 트랜잭션이 커밋되지 않으면 데이터베이스에 반영되지 않음.
커밋 전에 **flush()**를 호출하면 SQL이 즉시 실행됨.
쓰기 지연 저장소의 크기 관리
많은 엔티티 변경이 있을 경우, 쓰기 지연 저장소가 커질 수 있으므로 메모리 사용량을 주의해야 함.
변경 사항 반영 시점 제어 필요
특정 시점에 변경 내용을 즉시 반영하려면 flush() 메서드를 명시적으로 호출해야 함.
flush()와 쓰기 지연 비교
구분
설명
호출 시점
쓰기 지연
SQL을 쓰기 지연 저장소에 모아두고, 트랜잭션 커밋 시 한꺼번에 실행.
트랜잭션 커밋 시.
flush()
쓰기 지연 저장소에 있는 SQL을 데이터베이스에 즉시 실행.
명시적으로 em.flush() 호출 시.
쓰기 지연의 동작 확인
Hibernate가 생성하는 SQL 로그
User user = new User();
user.setName("Test");
em.persist(user); // SQL 생성되지만 실행 X (쓰기 지연 저장소에 저장)
// SQL 로그 출력
// No SQL executed yet
transaction.commit(); // 커밋 시점에 SQL 실행
// INSERT INTO User (name) VALUES ('Test')
쓰기 지연과 배치 처리
쓰기 지연은 **배치 처리(batch processing)**와 결합해 성능을 극대화할 수 있습니다. 배치 처리는 쓰기 지연 저장소에 있는 SQL을 그룹화하여 한꺼번에 처리하는 방식으로, 대규모 데이터 처리 시 유용합니다.
배치 처리 예시
Hibernate 설정에서 배치 크기 지정:
hibernate.jdbc.batch_size=30
결론
쓰기 지연은 JPA의 중요한 최적화 전략으로, 성능을 개선하고 데이터 일관성을 유지합니다. 하지만 트랜잭션 커밋 시점에 모든 SQL이 실행되므로, 이를 적절히 이해하고 활용하는 것이 중요합니다. 😊
flush
📌영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화하는 작업입니다. 즉, 쓰기 지연 저장소에 있는 SQL 명령문을 데이터베이스에 반영하는 과정을 의미합니다. 하지만 트랜잭션은 여전히 열려 있으며, 커밋이 이루어진 것은 아닙니다.
Flush의 주요 특징
쓰기 지연 저장소의 SQL 실행
영속성 컨텍스트에 있는 쓰기 지연 저장소에 누적된 SQL을 데이터베이스로 전송해 실행합니다.
트랜잭션 유지
Flush는 트랜잭션을 종료하지 않습니다. 즉, 데이터베이스에 반영되더라도 트랜잭션 롤백이 가능합니다.
자동 호출 시점
기본적으로 JPA는 특정 상황에서 Flush를 자동으로 호출합니다:
트랜잭션 커밋 시점: commit() 호출 전에 Flush가 실행됩니다.
JPQL 또는 Criteria 쿼리 실행 전: 쿼리 실행 전에 Flush로 변경 내용을 동기화해 일관성을 유지합니다.
Flush 동작 예시
코드 예제
EntityManagerFactory emf = Persistence.createEntityManagerFactory("example-unit");
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin();
User user = new User();
user.setName("John");
em.persist(user); // 영속성 컨텍스트에 저장, SQL은 실행되지 않음
em.flush(); // Flush 호출, INSERT SQL 실행
System.out.println("Flush 이후 실행");
user.setName("Updated John"); // 영속성 컨텍스트에서 Dirty Checking
transaction.commit(); // 트랜잭션 커밋, 변경 내용 반영
동작 흐름
em.persist(user)로 쓰기 지연 저장소에 INSERT 문이 추가됨.
em.flush() 호출 시, INSERT 문이 즉시 실행되어 데이터베이스에 반영.
user.setName()으로 엔티티 변경 후, commit() 시 Dirty Checking으로 변경 사항이 반영됨.
Flush 호출 방식
자동 Flush
특정 시점에서 JPA가 자동으로 Flush를 호출합니다.
자동 호출 시점:
트랜잭션 커밋 직전.
JPQL 실행 직전 (변경 내용과 쿼리 결과의 일관성을 유지하기 위해).
명시적 Flush
개발자가 EntityManager.flush()를 직접 호출해 변경 내용을 즉시 반영할 수 있습니다.
em.flush();
Flush의 동작 원리
단계
설명
쓰기 지연 저장소 확인
쓰기 지연 저장소에 있는 INSERT, UPDATE, DELETE SQL 문을 확인.
변경 감지(Dirty Checking)
영속 상태의 엔티티를 확인하고 변경된 엔티티를 쓰기 지연 저장소에 업데이트.
SQL 실행
쓰기 지연 저장소의 SQL 명령을 데이터베이스로 전송.
트랜잭션 유지
Flush 후에도 트랜잭션은 유지되며, 롤백이 가능.
Flush와 트랜잭션 커밋 비교
구분
Flush
Commit
역할
영속성 컨텍스트 변경 내용을 데이터베이스에 동기화.
데이터베이스 트랜잭션을 종료하고, 모든 변경 내용을 확정.
트랜잭션 유지
트랜잭션 유지 (롤백 가능).
트랜잭션 종료.
호출 시점
필요할 때 수동 호출 또는 자동 호출 (JPQL, Criteria 쿼리, Commit).
transaction.commit() 호출 시.
Flush의 활용 예시
JPQL 실행 전 Flush
JPQL 쿼리를 실행하면 Flush가 자동으로 호출되어 변경 사항을 반영한 최신 데이터를 조회합니다.
User user = new User();
user.setName("John");
em.persist(user); // 영속성 컨텍스트에 저장
em.createQuery("SELECT u FROM User u").getResultList(); // Flush 후 쿼리 실행
변경 내용 강제 반영
특정 시점에 변경 내용을 강제로 데이터베이스에 반영해야 할 때.
em.flush(); // SQL 실행
Batch 처리
Flush를 사용해 주기적으로 데이터베이스에 변경 사항을 반영하여 메모리 사용량을 줄임.
Flush의 주의사항
Flush 호출 후 롤백 가능
Flush는 트랜잭션을 종료하지 않으므로, 커밋 전 롤백이 가능합니다.
Flush로 인해 성능 저하 가능
Flush가 자주 호출되면 데이터베이스와의 통신이 빈번해져 성능 저하를 초래할 수 있습니다.
필요하지 않은 시점에서 Flush가 발생하지 않도록 주의해야 합니다.
자동 Flush 관리
JPQL 실행 시 자동 Flush가 발생하므로 불필요한 변경이 데이터베이스에 반영되지 않도록 주의해야 합니다.
결론
Flush는 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화하는 핵심 메커니즘으로, 데이터의 일관성을 유지하고 데이터베이스 작업을 제어하는 데 중요한 역할을 합니다. 이를 적절히 사용하여 트랜잭션 내에서 원하는 시점에 변경 내용을 반영할 수 있습니다. 😊
Flush는 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화하는 작업입니다. 즉, 쓰기 지연 저장소에 있는 SQL 명령문을 데이터베이스에 반영하는 과정을 의미합니다. 하지만 트랜잭션은 여전히 열려 있으며, 커밋이 이루어진 것은 아닙니다.
즉시 로딩 (Eager Loading)
📌JPA에서 엔티티를 조회할 때 연관된 모든 데이터(연관된 엔티티)를 즉시 로딩하는 전략입니다. 즉, 부모 엔티티를 조회할 때 연관된 자식 엔티티까지 한 번에 가져오는 방식입니다.
1. Eager Loading의 특징
항목
설명
로딩 시점
부모 엔티티를 조회하는 시점에 연관된 엔티티도 함께 로딩.
기본값
- @ManyToOne과 @OneToOne 관계에서는 기본 로딩 전략이 Eager.- 나머지는 Lazy가 기본값.
쿼리 특징
연관된 엔티티를 JOIN을 사용하여 한 번의 SQL로 가져오거나, 별도의 SELECT 쿼리로 가져옴.
SELECT o.*, u.*
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.id = 1;
(2) N+1 문제 발생 가능
Eager Loading으로 인해 추가적으로 불필요한 SELECT 쿼리가 다수 실행될 가능성이 있음.
-- 부모 엔티티 조회
SELECT * FROM orders;
-- 연관된 자식 엔티티 개별 조회 (N번 실행)
SELECT * FROM users WHERE id = ?;
SELECT * FROM users WHERE id = ?;
...
4. Eager Loading의 장점
편리한 데이터 로딩
연관된 엔티티를 즉시 사용할 수 있어 코드가 단순화됨.
한 번에 필요한 데이터 조회
적절히 설계하면 한 번의 JOIN으로 필요한 데이터를 모두 가져올 수 있음.
일관된 데이터 제공
트랜잭션 내에서 연관된 모든 엔티티를 로드해 항상 최신 데이터를 제공.
5. Eager Loading의 주의점
(1) N+1 문제
부모 엔티티를 조회한 뒤 연관된 자식 엔티티를 각각 조회하는 추가 쿼리가 발생.
데이터가 많아질수록 성능이 급격히 저하됨.
예: 부모 엔티티 1개와 자식 엔티티 N개를 조회할 때 N+1개의 쿼리 발생.
해결 방법:
FETCH JOIN 사용:
SELECT o FROM Order o JOIN FETCH o.user;
Batch Fetch 크기 설정 (Hibernate):
hibernate.default_batch_fetch_size=10
(2) 불필요한 데이터 로딩
연관된 엔티티가 항상 필요한 것은 아니기 때문에, 성능이나 메모리 낭비로 이어질 수 있음.
예: 연관된 데이터가 매우 크거나, 자주 사용되지 않는 경우.
해결 방법:
FetchType.LAZY로 변경하여 필요한 시점에 데이터 로딩.
(3) 대량의 데이터 로딩 시 성능 문제
연관된 엔티티가 대량일 경우 Eager Loading으로 인해 불필요한 데이터가 메모리에 로드될 수 있음.
해결 방법:
페이징을 고려하거나, 연관된 엔티티를 필요한 시점에 로딩.
(4) 복잡한 연관관계에서 JOIN 과다
다단계 연관 관계에서 Eager Loading이 적용되면, 불필요한 JOIN으로 인해 SQL이 복잡해지고 성능 저하가 발생.
해결 방법:
JPQL이나 네이티브 쿼리로 필요한 데이터만 로드.
6. Eager Loading을 사용할 때 고려해야 할 상황
상황 권장
사용 여부
연관된 엔티티를 항상 사용하는 경우
Eager Loading 사용 가능
연관된 엔티티가 자주 사용되지 않는 경우
Lazy Loading 사용 권장
데이터가 대량이고, 일부만 필요한 경우
Lazy Loading + Fetch Join
여러 계층으로 복잡한 연관관계가 있는 경우
Lazy Loading 사용 권장
7. Eager vs Lazy 비교
Eager Loading
Lazy Loading
로딩 시점
즉시 로딩 (부모 조회 시 자식도 함께 로드)
지연 로딩 (연관 엔티티를 사용할 때 로드)
기본값
@ManyToOne, @OneToOne
@OneToMany, @ManyToMany
성능
데이터가 많으면 성능 저하 (불필요한 데이터 로드)
필요할 때만 로딩하므로 성능에 유리
쿼리 발생
추가 JOIN이나 SELECT 쿼리가 발생
실제로 접근하기 전까지 쿼리 발생 안 함
사용 목적
연관 데이터를 항상 사용하는 경우 적합
연관 데이터를 자주 사용하지 않는 경우 적합
8. 결론
Eager Loading은 연관된 데이터를 항상 사용하는 경우 편리하고 유용하지만, N+1 문제, 불필요한 데이터 로딩, 복잡한 쿼리로 인해 성능 저하를 유발할 수 있습니다. 일반적으로 JPA에서는 **지연 로딩(Lazy Loading)**을 기본으로 설정하고, 필요 시 FETCH JOIN 또는 Batch Fetch 전략을 병행하여 성능을 최적화하는 것이 권장됩니다.
지연 로딩 (Lazy Loading)
📌JPA에서 연관된 엔티티를 실제 사용할 때 데이터베이스에서 로딩하는 방식입니다. 즉, 부모 엔티티를 조회할 때는 연관된 자식 엔티티를 로드하지 않고, 자식 엔티티에 접근하는 시점에 데이터를 가져옵니다. 이를 통해 성능 최적화와 메모리 사용량 절감이 가능합니다.
1. Lazy Loading의 특징
항목
설명
로딩 시점
연관된 엔티티에 실제 접근하는 순간에 데이터베이스에서 쿼리를 실행.
기본값
@OneToMany, @ManyToMany 관계에서는 기본 Fetch 전략이 Lazy.
쿼리 특징
부모 엔티티를 조회할 때 연관된 자식 엔티티를 즉시 로드하지 않음.
사용 목적
연관된 엔티티를 자주 사용하지 않을 경우 성능 최적화에 적합.
2. Lazy Loading 설정
기본 설정
@OneToMany, @ManyToMany는 기본적으로 Fetch 전략이 Lazy로 설정되어 있음.
@OneToMany(mappedBy = "parent") // 기본적으로 Lazy Loading
private List<Child> children;
명시적 설정
FetchType을 명시적으로 **FetchType.LAZY**로 설정.
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
3. Lazy Loading 동작 방식
(1) 프록시 객체 활용
Lazy Loading은 프록시 객체를 사용하여 동작.
JPA는 연관된 엔티티 대신 프록시 객체를 반환하며, 실제 데이터가 필요할 때 데이터베이스 쿼리를 실행하여 로드.
프록시 객체는 초기에는 실제 데이터를 포함하지 않으며, 접근 시 데이터를 로드.
User user = em.find(User.class, 1L); // User만 조회, 연관된 Order는 로드되지 않음
user.getOrders(); // 이 시점에 Order를 조회하는 쿼리가 실행됨
4. Lazy Loading 쿼리 예시
(1) 부모 엔티티 조회
SELECT * FROM users WHERE id = 1;
(2) 자식 엔티티 조회 (프록시 객체 접근 시)
SELECT * FROM orders WHERE user_id = 1;
5. Lazy Loading의 장점
성능 최적화
연관된 엔티티를 필요할 때만 로드하므로, 초기 로딩 시 성능 저하를 방지.
메모리 효율성
연관된 데이터가 많을 경우, 사용하지 않는 데이터를 메모리에 로드하지 않아 메모리 사용량 절감.
유연성
애플리케이션 요구사항에 따라 실제로 필요한 데이터만 로드 가능.
6. Lazy Loading의 주의점
(1) N+1 문제
Lazy Loading을 사용하는 경우, 부모 엔티티를 조회한 뒤 각 자식 엔티티를 조회하면서 추가 쿼리가 발생.
예를 들어, 부모 엔티티 N개에 대해 자식 엔티티를 조회하면 총 N+1개의 쿼리가 실행됨.
문제 발생 예시
List<User> users = em.createQuery("SELECT u FROM User u", User.class).getResultList();
for (User user : users) {
System.out.println(user.getOrders().size()); // 자식 엔티티를 조회할 때마다 쿼리 발생
}
해결 방법
FETCH JOIN 사용:
부모와 자식 데이터를 한 번에 로드.
SELECT u FROM User u JOIN FETCH u.orders;
Hibernate Batch Fetch:
Hibernate 설정을 통해 Batch Fetch 크기 조정.
hibernate.default_batch_fetch_size=10
(2) 프록시 초기화 오류 (LazyInitializationException)
Lazy Loading은 **영속성 컨텍스트(EntityManager)**가 열려 있어야 동작.
트랜잭션이 종료된 후에 프록시 객체를 접근하면 데이터베이스를 조회할 수 없으므로 **LazyInitializationException**이 발생.
문제 발생 예시
@Transactional
public User getUser(Long userId) {
User user = em.find(User.class, userId); // Lazy 프록시 반환
return user; // 트랜잭션 종료
}
User user = service.getUser(1L);
System.out.println(user.getOrders().size()); // LazyInitializationException 발생
해결 방법
트랜잭션 범위 확장:
데이터를 조회하고 필요한 데이터에 접근하는 작업을 같은 트랜잭션 내에서 수행.
FETCH JOIN 사용:
데이터 조회 시 필요한 연관 데이터를 모두 로드.
DTO로 변환:
필요한 데이터를 조회한 후 DTO로 변환하여 반환.
@Query("SELECT new com.example.dto.UserDTO(u.id, u.name, o.id) FROM User u JOIN u.orders o WHERE u.id = :id")
UserDTO findUserWithOrders(@Param("id") Long id);
7. Lazy Loading 사용 시 고려 사항
상황
권장 전략
연관 엔티티가 항상 필요한 경우
Eager Loading 또는 FETCH JOIN 사용.
연관 엔티티를 자주 사용하지 않는 경우
Lazy Loading.
트랜잭션 외부에서 연관 데이터를 사용할 경우
DTO 변환 또는 FETCH JOIN 사용.
데이터 양이 많아 성능 문제가 우려되는 경우
Lazy Loading + Batch Fetch 사용.
8. Lazy Loading을 최적화하는 방법
FETCH JOIN 사용:
JPQL에서 FETCH JOIN을 통해 필요한 데이터를 한 번에 로드.
SELECT u FROM User u JOIN FETCH u.orders;
Hibernate Batch Fetch 설정:
Hibernate의 default_batch_fetch_size 설정으로 한 번에 여러 엔티티를 로드.
hibernate.default_batch_fetch_size=10
DTO로 필요한 데이터만 변환:
복잡한 연관 관계가 있는 엔티티는 DTO로 필요한 필드만 조회하여 반환.
@Query("SELECT new com.example.dto.UserDTO(u.id, u.name, COUNT(o.id)) FROM User u LEFT JOIN u.orders o GROUP BY u.id")
List<UserDTO> findUsersWithOrderCount();
9. 결론
Lazy Loading은 메모리와 성능 최적화를 위해 기본적으로 권장되는 로딩 전략입니다. 하지만 N+1 문제와 프록시 초기화 오류에 유의해야 하며, 이를 방지하기 위해 FETCH JOIN, Batch Fetch, DTO 변환 등을 적절히 활용하는 것이 중요합니다.
Proxy
📌**지연 로딩(Lazy Loading)**을 지원하기 위해 생성되는 가짜 객체로, 엔티티의 실제 데이터 로딩을 지연시키고 필요한 시점에 데이터베이스에서 로딩합니다. 프록시는 JPA가 연관된 엔티티를 즉시 로드하지 않고, 필요한 시점에 쿼리를 실행하여 성능을 최적화하는 데 중요한 역할을 합니다.
1. Proxy란?
프록시는 JPA가 생성하는 가짜 객체로, 실제 엔티티 대신 반환됩니다.
프록시는 실제 데이터베이스 조회를 지연하고, 엔티티의 메서드가 호출되거나 필드에 접근하는 시점에 데이터베이스에서 데이터를 로드합니다.
Hibernate는 프록시 객체를 통해 Lazy Loading을 구현합니다.
2. Proxy의 동작 원리
em.find() 대신 em.getReference()를 호출하거나, 연관 엔티티가 Lazy 로딩으로 설정된 경우 프록시 객체가 반환됩니다.
프록시 객체는 실제 엔티티 클래스를 상속받아 생성되며, 데이터가 로드되기 전에는 **필요 최소한의 메타데이터(ID 값)**만 가지고 있습니다.
데이터베이스에서 데이터를 로드해야 할 때, 프록시가 내부적으로 데이터베이스에 접근하여 데이터를 로드합니다.
예제 코드
User user = em.getReference(User.class, 1L); // 프록시 객체 반환
System.out.println(user.getClass().getName()); // 프록시 클래스 이름 출력
System.out.println(user.getName()); // 실제 데이터베이스 쿼리가 실행되어 이름 로드
3. Proxy 사용 예제
(1) 프록시 반환
em.getReference()를 사용하면 프록시 객체가 반환됩니다.
User user = em.getReference(User.class, 1L);
System.out.println(user.getClass().getName()); // 프록시 객체의 클래스 이름 출력
(2) 프록시 초기화
프록시 객체의 데이터를 실제로 사용할 때 데이터베이스 쿼리가 실행되어 초기화됩니다.
System.out.println(user.getName()); // 이 시점에 SELECT 쿼리가 실행됨
4. Proxy와 Lazy Loading
Lazy Loading은 연관된 엔티티를 처음부터 로드하지 않고, 실제로 접근하는 시점에 로드합니다.
프록시 객체를 활용해 필요한 시점까지 데이터 로딩을 지연시킵니다.
Lazy Loading 설정
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
5. Proxy 사용 시 주의사항
(1) LazyInitializationException
프록시 객체는 **영속성 컨텍스트(EntityManager)**가 열려 있는 동안에만 초기화할 수 있습니다.
트랜잭션이 종료된 상태에서 프록시 객체에 접근하려 하면 LazyInitializationException이 발생합니다.
문제 상황
@Transactional
public User getUser(Long id) {
return em.getReference(User.class, id); // 프록시 반환
}
// 트랜잭션 종료 후
System.out.println(user.getName()); // LazyInitializationException 발생
해결 방법
트랜잭션 내에서 데이터 초기화
트랜잭션이 종료되기 전에 데이터를 로드.
user.getName(); // 트랜잭션 내에서 초기화
FETCH JOIN 사용
JPQL로 데이터를 조회할 때 필요한 연관 데이터를 함께 로드.
SELECT u FROM User u JOIN FETCH u.orders WHERE u.id = :id
DTO 사용
필요한 데이터를 조회하여 DTO로 반환.
@Query("SELECT new com.example.dto.UserDTO(u.id, u.name) FROM User u WHERE u.id = :id")
UserDTO findUserDTO(Long id);
(2) 프록시 객체 비교
프록시는 실제 엔티티와 다른 객체이기 때문에, == 비교가 아닌 equals() 비교를 사용해야 합니다.
User user1 = em.find(User.class, 1L); // 실제 엔티티 반환
User user2 = em.getReference(User.class, 1L); // 프록시 반환
System.out.println(user1 == user2); // false (프록시와 실제 엔티티는 다른 객체)
System.out.println(user1.equals(user2)); // true (equals() 비교는 같음)
(3) 성능 문제
프록시 초기화 시 쿼리가 실행되므로, 연관 엔티티가 많을 경우 N+1 문제가 발생할 수 있습니다.
문제 상황
List<User> users = em.createQuery("SELECT u FROM User u", User.class).getResultList();
for (User user : users) {
System.out.println(user.getOrders().size()); // 각 User의 Orders를 조회할 때마다 쿼리 발생
}
해결 방법
FETCH JOIN 사용:
SELECT u FROM User u JOIN FETCH u.orders;
Batch Fetch 설정:
hibernate.default_batch_fetch_size=10
6. Proxy의 장점
성능 최적화
초기 로딩 시 필요한 최소한의 데이터만 가져와 성능을 최적화.
메모리 효율성
대량의 연관 데이터를 지연 로딩하여 메모리 사용량 절감.
유연성
실제 데이터를 로드하지 않고도 엔티티의 ID와 같은 기본 정보를 사용할 수 있음.
7. Proxy와 관련된 메서드
(1) Hibernate.initialize()
Hibernate가 제공하는 메서드로, 프록시 객체를 강제로 초기화.
User user = em.getReference(User.class, 1L);
Hibernate.initialize(user); // 강제로 초기화
(2) PersistenceUtil.isLoaded()
JPA 표준 메서드로, 프록시 객체가 초기화되었는지 확인.
User user = em.getReference(User.class, 1L);
boolean isLoaded = Persistence.getPersistenceUtil().isLoaded(user); // 초기화 여부 확인
8. 결론
JPA의 프록시(Proxy)는 Lazy Loading의 핵심적인 구현 도구로, 성능 최적화와 메모리 효율성을 제공합니다. 그러나 LazyInitializationException, N+1 문제, 프록시 객체 비교 이슈와 같은 주의 사항이 있으므로, 적절한 시점에 데이터를 로드하거나 **FETCH JOIN**과 Batch Fetch를 활용하여 최적화해야 합니다.
N + 1 문제
📌 JPA에서 **지연 로딩(Lazy Loading)**을 사용하는 경우 발생하는 성능 문제로, **하나의 쿼리(N)**로 조회한 엔티티에 대해 연관된 데이터를 조회하면서 **추가적인 쿼리(1)**가 반복적으로 발생하는 현상입니다. 데이터가 많아질수록 추가 쿼리 수가 증가하므로 성능에 큰 영향을 미칩니다.
1. N + 1 문제의 동작 원리
1 쿼리: 부모 엔티티를 조회하는 기본 쿼리 실행.
N 쿼리: 각 부모 엔티티와 연관된 자식 엔티티를 조회하기 위해 N번 추가 쿼리 실행.
예제 코드
List<User> users = em.createQuery("SELECT u FROM User u", User.class).getResultList();
for (User user : users) {
System.out.println(user.getOrders().size()); // 지연 로딩으로 인해 쿼리 발생
}
발생 쿼리
부모 엔티티 조회 (1번 실행):
SELECT * FROM User;
자식 엔티티 조회 (부모 수만큼 실행):
SELECT * FROM Order WHERE user_id = 1;
SELECT * FROM Order WHERE user_id = 2;
...
2. N + 1 문제의 영향
데이터의 양이 많아질수록 실행되는 쿼리 수가 기하급수적으로 증가.
데이터베이스 부하 증가와 성능 저하 발생.
3. N + 1 문제의 해결 방법
(1) Fetch Join 사용
FETCH JOIN은 JPQL에서 부모와 자식 엔티티를 함께 조회하여 N+1 문제를 해결합니다. 연관된 데이터를 한 번의 JOIN 쿼리로 가져옵니다.
JPQL 사용 예제
SELECT u FROM User u JOIN FETCH u.orders;
장점
부모와 자식 데이터를 한 번의 쿼리로 조회.
Lazy Loading 설정을 무시하고 즉시 로딩.
실행 쿼리
SELECT u.*, o.*
FROM User u
LEFT JOIN Order o ON u.id = o.user_id;
(2) Batch Fetch 설정
Hibernate의 Batch Fetch는 연관된 엔티티를 한 번에 가져오는 쿼리 최적화 방법입니다. N번 쿼리를 Batch Size 크기로 묶어 실행합니다.
Batch Fetch 설정
hibernate.default_batch_fetch_size=10
동작 방식
10개 단위로 연관 데이터를 로드.
여러 쿼리가 발생하지만, 성능이 크게 개선.
실행 쿼리
SELECT * FROM Order WHERE user_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
(3) Entity Graph 사용
JPA 2.1에서 제공하는 Entity Graph를 사용하면 특정 연관 데이터를 명시적으로 가져올 수 있습니다.
Entity Graph 설정
@Entity
@NamedEntityGraph(
name = "User.orders",
attributeNodes = @NamedAttributeNode("orders")
)
public class User {
// ...
}
사용 예제
EntityGraph<?> entityGraph = em.getEntityGraph("User.orders");
Map<String, Object> hints = new HashMap<>();
hints.put("javax.persistence.fetchgraph", entityGraph);
List<User> users = em.createQuery("SELECT u FROM User u", User.class)
.setHint("javax.persistence.fetchgraph", entityGraph)
.getResultList();
(4) DTO를 사용한 직접 조회
필요한 데이터만 조회하여 DTO(Data Transfer Object)에 담아 반환합니다. 이는 쿼리를 직접 작성하므로 가장 높은 성능을 제공합니다.
JPQL을 사용한 DTO 조회
List<UserOrderDTO> results = em.createQuery(
"SELECT new com.example.UserOrderDTO(u.name, o.productName) " +
"FROM User u JOIN u.orders o", UserOrderDTO.class)
.getResultList();
쿼리
SELECT u.name, o.product_name
FROM User u
JOIN Order o ON u.id = o.user_id;
(5) Lazy Loading이 필요 없는 경우 Eager Loading 사용
Lazy Loading으로 인해 N+1 문제가 발생하는 경우, Eager Loading으로 변경하여 연관 데이터를 즉시 로딩합니다.
Eager Loading은 항상 모든 연관 데이터를 로딩하므로, 불필요한 데이터가 많아지면 오히려 성능 저하를 유발할 수 있습니다.
4. 해결 방법 비교
장점
단점
Fetch Join
단일 쿼리로 데이터 로드.
다단계 연관관계에서 복잡한 JOIN으로 인해 성능 저하 가능.
Batch Fetch
쿼리 수를 줄이고 성능 개선.
추가 설정 필요, JOIN보다 많은 쿼리가 발생할 수 있음.
Entity Graph
명시적으로 연관 데이터를 로드하여 제어 가능.
설정 및 관리가 다소 복잡.
DTO 조회
필요한 데이터만 조회하여 성능 최적화.
JPQL 또는 네이티브 쿼리를 직접 작성해야 함.
Eager Loading
연관 데이터 항상 로딩, 코드 간결화.
불필요한 데이터 로딩으로 메모리 및 성능 문제 가능.
5. N + 1 문제 해결 시 주의사항
모든 연관 데이터를 항상 가져오지 말 것
Lazy Loading과 Fetch Join을 적절히 조합하여 필요할 때만 데이터를 로드.
복잡한 연관관계의 Fetch Join 주의
Fetch Join은 다단계 연관관계에서 SQL 쿼리가 매우 복잡해질 수 있음.
Batch Fetch 크기 조정
hibernate.default_batch_fetch_size 값을 적절히 조정하여 최적의 성능을 도출.
DTO 활용
복잡한 연관관계에서는 DTO를 사용하여 필요한 데이터만 조회하는 것이 효과적.
6. 결론
N+1 문제는 JPA를 사용할 때 빈번하게 발생하는 성능 문제 중 하나입니다. 이를 해결하기 위해서는 Fetch Join, Batch Fetch, DTO 조회, Entity Graph 등을 적절히 활용해야 합니다. 상황에 따라 가장 적합한 해결 방법을 선택하여 성능 최적화와 코드 유지보수성을 동시에 확보하는 것이 중요합니다.
변경 감지(Dirty Checking)
📌 영속성 컨텍스트가엔티티의 초기 상태를 저장하고 트랜잭션커밋 시점에 현재 상태와 비교해 변경 사항이 있는지 확인하는 기능이다.
Database에 저장된 데이터가 있는 상태
xml <property name="hibernate.hbm2ddl.auto" value="none" /> 설정
public static void main(String[] args) {
// EntityManagerFactory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("test");
// EntityManager 생성
EntityManager em = emf.createEntityManager();
// Transaction 생성
EntityTransaction transaction = em.getTransaction();
// 트랜잭션 시작
transaction.begin();
try {
Tutor tutor = em.find(Tutor.class, 1L);
tutor.setName("수정된 이름");
// Java Collection을 사용하면 값을 수정하고 다시 저장하지 않는다.
// em.persist(tutor);
System.out.println("트랜잭션 Commit 전");
// transaction이 commit되며 실제 SQL이 실행된다.
transaction.commit();
System.out.println("트랜잭션 Commit 후");
} catch (Exception e) {
// 실패 -> 롤백
e.printStackTrace();
transaction.rollback();
} finally {
// 엔티티 매니저 연결 종료
em.close();
}
emf.close();
}
em.persist(tutor); 로 저장하지 않아도 update SQL이 실행된다.
Entity를 변경하고자 할 때 em.persist() 를 사용하지 않아야 실수를 방지한다.
em.remove()를 통해 Entity를 삭제할 때도 위와 같은 방식으로 동작한다. DELETE SQL이 트랜잭션 Commit 시점에 실행된다.
데이터베이스 드라이버
🧩애플리케이션(클라이언트)과 데이터베이스 서버 간의 통신을 가능하게 하는 소프트웨어 구성 요소입니다.
드라이버는 표준화된 프로토콜(JDBC, ODBC 등)을 통해 서로 다른 언어와 시스템 간의 데이터 전송을 중개합니다.
2. 데이터베이스 드라이버의 역할
애플리케이션과 데이터베이스 간의 연결
애플리케이션이 데이터베이스와 통신할 수 있도록 DBMS 전용 프로토콜을 사용.
SQL 명령 전달
애플리케이션이 작성한 SQL 명령을 데이터베이스 서버가 이해할 수 있는 형식으로 변환.
결과 반환
데이터베이스 서버에서 반환된 결과를 클라이언트가 이해할 수 있는 형태로 변환.
3. 데이터베이스 드라이버의 종류
1) JDBC (Java Database Connectivity) 드라이버
JDBC는 자바에서 데이터베이스와 연결하기 위한 표준 인터페이스.
다양한 DBMS(MySQL, Oracle, PostgreSQL 등)에 맞는 JDBC 드라이버를 사용.
예시:
MySQL: mysql-connector-java
Oracle: ojdbc
PostgreSQL: postgresql
2) ODBC (Open Database Connectivity) 드라이버
ODBC는 운영 체제 수준에서 다양한 언어와 데이터베이스 간의 연결을 지원하는 표준 API.
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
while (rs.next()) {
System.out.println(rs.getString("name"));
}
7. 데이터베이스 드라이버의 장점
다양한 DBMS 지원
동일한 애플리케이션에서 여러 데이터베이스를 연결 가능.
표준화된 API 제공
JDBC/ODBC 표준을 통해 통일된 방식으로 DBMS와 통신 가능.
다양한 언어 지원
자바, C++, 파이썬 등 다양한 언어에서 데이터베이스 접근 가능.
8. 데이터베이스 드라이버의 단점
DBMS 종속성
특정 DBMS에 최적화된 드라이버 사용 시 다른 DBMS로 전환이 어려움.
성능 문제
ODBC와 같은 브릿지 드라이버는 성능이 느릴 수 있음.
초기 설정 필요
드라이버 파일 설치 및 클래스 경로 설정이 필요.
결론
데이터베이스 드라이버는 애플리케이션이 데이터베이스와 원활히 통신할 수 있도록 지원하는 필수적인 구성 요소입니다. 특히, JDBC 드라이버는 자바 기반 애플리케이션에서 가장 많이 사용되며, DBMS에 맞는 드라이버를 선택하여 사용하면 됩니다. 추가로, 드라이버의 유형과 설정 방법을 잘 이해하면 데이터베이스 연결 작업이 훨씬 수월해집니다.
궁금한 점이 있다면 언제든지 물어보세요! 😊
[아래의 JDBC Template, MyBatis, 그리고 JPA/Hibernate는 DB 드라이버를 기반으로 동작하는 도구로, 데이터베이스 작업을 더 쉽게 처리하도록 돕는 라이브러리입니다. = 매핑하는 친구들입니다.
DB 드라이버는 데이터베이스와 애플리케이션 간의 기본적인 연결과 통신을 담당하는 소프트웨어입니다. 서로 다릅니다. 오히려 아래의 친구들이 DB드라이버를 이용하죠]
JDBC Template은 Spring Framework에서 제공하는 데이터베이스 액세스 도구로, JDBC를 사용한 데이터베이스 작업을 단순화하고, 자원 관리 및 예외 처리를 자동으로 처리해주는 역할을 합니다. JDBC API를 기반으로 하지만, 번거로운 작업(커넥션, 스테이트먼트, ResultSet 처리 등)을 자동화하여 개발자의 생산성을 높여줍니다.
주요 특징
JDBC 작업 단순화:
JDBC API의 반복적인 코드(자원 관리, 예외 처리 등)를 제거합니다.
SQL 실행 및 결과 매핑 과정을 간소화합니다.
자원 관리 자동화:
Connection, Statement, ResultSet과 같은 리소스를 자동으로 닫아줍니다.
개발자가 명시적으로 자원을 해제할 필요가 없습니다.
예외 변환:
JDBC의 SQLException을 Spring의 DataAccessException으로 변환하여 좀 더 이해하기 쉬운 예외 처리를 제공합니다.
유연한 SQL 실행:
CRUD 작업, 배치 처리, 동적 쿼리 실행 등을 간단히 처리할 수 있습니다.
결과 매핑 지원:
데이터베이스에서 가져온 결과를 RowMapper, BeanPropertyRowMapper 등을 사용해 Java 객체로 쉽게 변환할 수 있습니다.
JDBC Template 주요 메서드
queryForObject():
단일 행의 결과를 가져와 Java 객체로 매핑합니다.
예:
String sql = "SELECT name FROM users WHERE id = ?";
String name = jdbcTemplate.queryForObject(sql, new Object[]{1}, String.class);
query():
다수의 결과 행을 가져와 RowMapper를 통해 매핑합니다.
예:
String sql = "SELECT id, name FROM users";
List<User> users = jdbcTemplate.query(sql, new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
return user;
}
});
update():
INSERT, UPDATE, DELETE와 같은 데이터 변경 작업을 수행합니다.
예:
String sql = "UPDATE users SET name = ? WHERE id = ?";
int rowsAffected = jdbcTemplate.update(sql, "John Doe", 1);
batchUpdate():
다수의 SQL을 한 번에 실행(배치 처리).
예:
String sql = "INSERT INTO users (name) VALUES (?)";
List<Object[]> batchArgs = Arrays.asList(
new Object[]{"John"},
new Object[]{"Jane"},
new Object[]{"Jack"}
);
jdbcTemplate.batchUpdate(sql, batchArgs);
queryForList():
쿼리 결과를 List 형태로 반환.
예:
String sql = "SELECT name FROM users";
List<String> names = jdbcTemplate.queryForList(sql, String.class);
JDBC Template의 동작 원리
데이터 소스(DataSource) 사용:
JDBC Template는 데이터베이스 연결을 관리하기 위해 DataSource를 사용합니다.
Spring의 DataSource 설정을 통해 커넥션 풀(Connection Pool)과 같은 기능을 활용합니다.
RowMapper 또는 BeanPropertyRowMapper를 사용해 SQL 결과를 Java 객체로 변환합니다.
JDBC Template 예제
1. 데이터 조회 (단일 결과):
String sql = "SELECT id, name, email FROM users WHERE id = ?";
User user = jdbcTemplate.queryForObject(sql, new Object[]{1}, new BeanPropertyRowMapper<>(User.class));
2. 데이터 조회 (다중 결과):
String sql = "SELECT id, name FROM users";
List<User> users = jdbcTemplate.query(sql, new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
return user;
}
});
3. 데이터 삽입:
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
int rowsInserted = jdbcTemplate.update(sql, "John Doe", "john.doe@example.com");
4. 배치 삽입:
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
List<Object[]> batchArgs = Arrays.asList(
new Object[]{"Alice", "alice@example.com"},
new Object[]{"Bob", "bob@example.com"}
);
jdbcTemplate.batchUpdate(sql, batchArgs);
JDBC Template의 장점
코드 간소화:
자원 관리 및 예외 처리를 자동화하여 코드가 간결해집니다.
유연성:
복잡한 SQL 쿼리 실행과 결과 매핑 작업을 쉽게 처리할 수 있습니다.
데이터베이스 독립성:
다양한 DBMS에서 사용 가능하며, Spring의 DataSource를 활용해 쉽게 설정할 수 있습니다.
JDBC Template은 SQL 중심 개발을 지원하면서도, 자원 관리와 매핑 작업을 단순화합니다.
복잡한 ORM 프레임워크(JPA/Hibernate) 없이도 간단한 데이터베이스 작업에 적합하며, SQL을 직접 제어하고 싶을 때 유용합니다.
하지만 대규모 프로젝트에서 객체-관계 매핑을 자동화해야 한다면 ORM 기술(JPA 등)을 사용하는 것이 더 적합할 수 있습니다. 😊
OueryMapper와 RowMapper
🧩QueryMapper와RowMapper는 자바 애플리케이션에서 데이터베이스 조회 결과를객체로 변환하는 데 사용되는 개념입니다. 주로Spring JDBC에서 사용되며, 데이터베이스에서 가져온 데이터를 자바 객체로 매핑할 때 활용됩니다.
1. RowMapper란?
RowMapper는Spring JDBC에서 제공하는 인터페이스로, 데이터베이스의 결과 집합(ResultSet)의한 행(Row)을 자바 객체로 매핑하는 데 사용됩니다.
RowMapper의 메서드
T mapRow(ResultSet rs, int rowNum) throws SQLException;
ResultSet rs: 쿼리 결과에서 한 행의 데이터.
int rowNum: 현재 처리 중인 행의 번호.
T: 매핑된 자바 객체의 타입.
사용 예시
public class UserRowMapper implements RowMapper<User> {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
user.setEmail(rs.getString("email"));
return user;
}
}
2. QueryMapper란?
QueryMapper는 Spring에서 별도로 제공되는 클래스가 아니며, 데이터베이스 쿼리 결과를 자바 객체로 매핑하기 위한 사용자 정의 매퍼 또는 메커니즘을 의미합니다.
보통QueryMapper는ResultSetExtractor나RowMapper를 내부적으로 사용하여 쿼리 결과를 처리합니다.
특정 애플리케이션에서QueryMapper라는 이름으로결과 매핑을 처리하는 사용자 정의 클래스를 작성하는 경우가 많습니다.
RowMapper와 QueryMapper의 차이점
RowMapper
QueryMapper
정의
Spring JDBC에서 제공하는 인터페이스.
특정 애플리케이션에서 정의하는 사용자 정의 매핑 도구.
역할
ResultSet의 한 행을 자바 객체로 변환.
쿼리 결과 전체를 처리하여 복합 객체나 여러 데이터로 변환.
Spring 지원 여부
Spring에서 기본 제공.
Spring에서 제공하지 않음(사용자 정의).
RowMapper와 QueryMapper 사용 예시
RowMapper 사용
String sql = "SELECT id, name, email FROM users";
List<User> users = jdbcTemplate.query(sql, new UserRowMapper());
QueryMapper로 사용자 정의
public class QueryMapper {
public static List<User> mapToUsers(ResultSet rs) throws SQLException {
List<User> users = new ArrayList<>();
while (rs.next()) {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
user.setEmail(rs.getString("email"));
users.add(user);
}
return users;
}
}
복잡한 쿼리를 자주 작성해야 하거나, 성능 최적화를 위해 SQL을 직접 관리해야 하는 경우 적합합니다.
DBMS 고유 기능 활용:
MyBatis는 DBMS 특정 기능을 활용하기 쉬우며, 프로시저/함수와의 연계가 필요할 때 강력한 도구가 됩니다.
데이터 중심 애플리케이션:
간단한 CRUD 외에 대량의 데이터 처리 작업이 필요한 애플리케이션에서 사용됩니다.
6. MyBatis와 ORM 비교
MyBatis
ORM (JPA/Hibernate)
SQL 작성
직접 작성
SQL 자동 생성 (필요 시 JPQL 사용)
유연성
높음 (SQL 직접 작성 가능)
제한적 (복잡한 SQL 작성 시 불편)
객체 상태 관리
없음 (객체와 DB 상태는 별도 관리)
영속성 컨텍스트로 객체 상태와 DB 상태 동기화
러닝 커브
낮음
높음 (Entity 설계, JPQL 학습 필요)
성능 최적화
SQL 튜닝으로 직접 제어 가능
ORM 내부 최적화에 의존
생산성
복잡한 작업에 적합
CRUD 작업에서는 더 높은 생산성
7. 결론
MyBatis는 SQL을 직접 제어하고 싶거나 복잡한 쿼리가 필요한 프로젝트에 적합합니다.
데이터베이스와 객체의 동기화 관리가 자동으로 필요하지 않고, 높은 SQL 최적화가 중요한 경우 사용하면 효율적입니다.
다만, 관리해야 할 SQL이 많아질수록 유지보수가 어려워질 수 있으니, 프로젝트의 복잡성과 요구 사항에 따라 선택해야 합니다.
ORM
🧩ORM(Object-Relational Mapping)은 객체 지향 프로그래밍(OOP)의 객체와 관계형 데이터베이스(RDB)의 테이블 간의데이터 변환 및 매핑을 자동화하는 기술입니다.
객체 지향 언어에서 객체를 사용하여 데이터베이스와 상호작용.
객체 간의 관계를 테이블 간의 관계로 매핑.
QueryMapper 의 DB의존성 및 중복 쿼리 문제로 ORM 이 탄생했다.
Mapper는 "SQL로 데이터를 가져오고, 객체로 변환하는 도구"이고,ORM은 "테이블과 객체를 아예 1:1로 대응시키는 추상화된 설계"로 Mapper의 경우 java에서 매핑한 객체를 수정해도 DB에 영향이 없지만 ORM은 대응이기에 한번에 수정가능하다. 이렇게 DB에 바로 적용되는 걸 지정하는 것 중에 하나가 지연 쓰기이다.
-flush()호출 전까지 SQL 쿼리를 영속성 컨텍스트에 모아두었다가, 한 번에 DB로 전송하는 최적화 메커니즘.
쓰기 지연 발생 시점
- 트랜잭션 중 객체 생성, 수정, 삭제 시. - flush() 호출 전까지 쿼리를 최적화하여 보관.
쓰기 지연 효과
- 여러 동작을 모아 쿼리를 한번에 전송하여 최소화. - 생성/수정/삭제 작업의 중간 상태가 발생하더라도 실제 DB에는 최적화된 쿼리만 전송. - 불필요한 쿼리 전송 방지.
주의점
-GenerationType.IDENTITY사용 시, 쓰기 지연이 적용되지 않음. - 이유: IDENTITY 전략은 키 생성 시점에 단일 쿼리가 필요하며, 외부 트랜잭션 간의 키 중복을 방지하기 위해 즉시 DB에 반영됨.
6. 대표적인 ORM 프레임워크
프레임워크
언어
특징
JPA
Java
Java 표준 ORM API. Hibernate가 대표적인 구현체.
Hibernate
Java
가장 널리 사용되는 JPA 구현체. 다양한 기능과 확장성을 제공.
Entity Framework
C#/.NET
Microsoft에서 제공하는 .NET 기반 ORM.
SQLAlchemy
Python
파이썬에서 널리 사용되는 ORM. 고급 매핑 및 SQL 표현 지원.
Django ORM
Python
Django 프레임워크에 기본 제공되는 ORM.
7. ORM vs SQL (직접 작성)
특징
ORM
SQL 직접 작성
개발 생산성
SQL을 자동 생성하므로 빠르게 개발 가능.
직접 SQL을 작성해야 하므로 반복 작업 많음.
데이터베이스 독립성
DBMS 변경 시 코드 수정 최소화.
DBMS 특화 SQL 사용 시 독립성 떨어짐.
쿼리 제어
ORM이 SQL을 생성하므로 제어가 제한될 수 있음.
쿼리를 직접 작성하여 완전한 제어 가능.
복잡한 쿼리
복잡한 쿼리는 ORM에서 처리하기 어렵거나 성능 저하 가능.
복잡한 쿼리 작성에 유리.
초기 학습 비용
ORM 자체를 이해해야 하므로 학습 시간이 필요.
SQL만 이해하면 바로 시작 가능.
8. 언제 ORM을 사용해야 할까?
CRUD 중심 애플리케이션
데이터베이스와 상호작용이 단순한 경우 ORM이 효율적.
객체 지향적인 설계
도메인 모델 중심으로 설계된 애플리케이션에서 객체-테이블 간 매핑이 적합.
복잡한 비즈니스 로직
데이터 처리보다는 비즈니스 로직이 복잡한 경우 ORM이 유리.
데이터베이스 독립성이 필요한 경우
DBMS가 자주 변경되거나 여러 데이터베이스를 지원해야 하는 경우.
9. 결론
ORM은 객체 지향 프로그래밍과 관계형 데이터베이스 간의 패러다임 불일치를 해소하여생산성을 높이고 유지보수를 용이하게만듭니다. 특히,JPA와 같은 ORM 프레임워크를 사용하면 객체 지향적으로 데이터를 다루면서 SQL 작성 부담을 줄일 수 있습니다.
그러나 복잡한 쿼리나 성능이 중요한 프로젝트에서는 SQL과 ORM을 적절히 병행해서 사용하는 것이 좋습니다.
Hibernate
🎵 자바 애플리케이션에서 관계형 데이터베이스와 객체 간의 매핑(ORM, Object-Relational Mapping)을 처리하는 오픈소스 프레임워크입니다. Hibernate는 JPA(Java Persistence API)의 구현체 중 하나로, 개발자가 객체 중심의 데이터 처리와 SQL 작성 부담을 줄이고 생산성을 높일 수 있게 합니다.
Hibernate는 자바 애플리케이션에서 관계형 데이터베이스와 객체 간의 매핑(ORM, Object-Relational Mapping)을 처리하는 오픈소스 프레임워크입니다. Hibernate는 JPA(Java Persistence API)의 구현체 중 하나로, 개발자가 객체 중심의 데이터 처리와 SQL 작성 부담을 줄이고 생산성을 높일 수 있게 합니다.
Hibernate의 주요 특징
특징
설명
ORM (객체-관계 매핑)
자바 객체와 데이터베이스 테이블을 매핑하여 객체 중심 설계 가능.
JPA 구현체
Java EE 표준인 JPA를 구현하여 JPA API를 기반으로 동작.
HQL (Hibernate Query Language)
객체를 대상으로 하는 SQL 유사 쿼리 언어로 복잡한 SQL 대신 사용 가능.
1차 캐시
동일 트랜잭션 내에서 영속성 컨텍스트를 활용해 엔티티 조회 시 동일 객체를 반환 (동일성 보장).
Lazy Loading
연관된 엔티티를 필요할 때만 로딩하여 성능 최적화.
쓰기 지연 (Write-Behind)
SQL 명령어를 트랜잭션 종료 시점에 한꺼번에 실행.
데이터베이스 독립성
Dialect 설정을 통해 특정 데이터베이스에 종속되지 않음.
자동 DDL 생성
엔티티를 기반으로 테이블 구조 자동 생성 가능.
Hibernate의 주요 장점
객체 중심 설계
객체 모델과 데이터베이스 모델 간의 불일치를 해결하여 객체 지향적 개발 가능.
SQL 자동 생성
복잡한 SQL 작성 부담을 줄이고, 기본적인 CRUD 작업을 자동화.
데이터베이스 독립성
다양한 데이터베이스를 지원하며, 데이터베이스 변경 시 애플리케이션 코드 수정을 최소화.
1차 캐시
동일 트랜잭션 내에서 같은 객체를 반환하여 메모리와 성능 최적화.
Lazy Loading
실제로 필요한 데이터만 로딩하여 불필요한 데이터 로드를 방지.
Hibernate의 주요 구성 요소
구성 요소
설명
Session
Hibernate의 주요 작업 단위로, 영속성 컨텍스트를 관리. 엔티티 저장, 조회, 업데이트, 삭제 등 수행.
SessionFactory
Session을 생성하기 위한 팩토리. 애플리케이션에서 하나만 생성하고 재사용.
Transaction
트랜잭션을 관리하며, 데이터베이스 작업의 원자성을 보장.
Configuration
Hibernate 설정 파일(hibernate.cfg.xml)이나 속성 파일을 로드하여 초기 설정 관리.
Query
HQL 또는 Native SQL 쿼리를 실행하기 위한 인터페이스.
Hibernate의 주요 애너테이션
애너테이션
설명
@Entity
클래스를 Hibernate 엔티티로 선언.
@Table
매핑할 데이터베이스 테이블 이름 지정.
@Id
엔티티의 기본 키를 지정.
@GeneratedValue
기본 키 값의 자동 생성 전략을 설정 (IDENTITY, SEQUENCE 등).
@Column
필드를 데이터베이스 컬럼에 매핑하며, 컬럼 이름, 길이, NULL 여부 등을 설정.
@OneToOne
1:1 관계 매핑.
@OneToMany
1:N 관계 매핑.
@ManyToOne
N:1 관계 매핑.
@ManyToMany
N:M 관계 매핑.
@JoinColumn
외래 키 컬럼을 지정.
Hibernate 주요 동작 예시
1. 기본 엔티티
import jakarta.persistence.*;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(unique = true)
private String email;
// Getters and Setters
}
SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
try {
// 데이터 저장
User user = new User();
user.setName("John");
user.setEmail("john@example.com");
session.save(user);
// 데이터 조회
User retrievedUser = session.get(User.class, 1L);
System.out.println(retrievedUser.getName());
// 데이터 수정
retrievedUser.setName("Updated John");
session.update(retrievedUser);
// 데이터 삭제
session.delete(retrievedUser);
transaction.commit();
} catch (Exception e) {
transaction.rollback();
e.printStackTrace();
} finally {
session.close();
}
Hibernate와 JPA의 관계
항목
Hibernate
JPA
정의
ORM 프레임워크로 JPA의 구현체 중 하나.
자바의 ORM 표준 API.
표준 여부
Hibernate는 표준이 아님.
JPA는 Java EE 표준.
호환성
JPA 표준을 따르면서, Hibernate 고유 기능 제공.
Hibernate, EclipseLink 등 다양한 구현체와 호환.
Hibernate의 장단점
장점
단점
객체 중심 개발 가능.
설정 복잡도가 높음.
다양한 데이터베이스 지원 및 독립성 보장.
대규모 애플리케이션에서 1차 캐시 사용으로 메모리 부담 가능성 있음.
SQL 작성 부담 감소 (CRUD 작업 자동화).
잘못된 Lazy Loading 설계로 인해 성능 문제가 발생할 수 있음.
HQL을 통해 객체 중심 쿼리 작성 가능.
Hibernate 고유 기능 사용 시 JPA 구현체를 변경하기 어려울 수 있음.
결론
Hibernate는 JPA 표준을 구현하면서도 강력한 ORM 기능과 성능 최적화를 제공하는 프레임워크입니다. JPA의 구현체로 시작해도 고유한 기능을 활용할 수 있으므로, 개발 생산성을 높이고 객체 지향적인 데이터베이스 설계를 구현하는 데 적합합니다. 추가적으로 Hibernate 고유 기능이나 성능 최적화에 대해 궁금한 점이 있다면 알려주세요! 😊
OueryMapper, RowMapper, MYABITS, ORM 차이점
1. 차이점 정리
QueryMapper (Spring JDBC)
RowMapper (Spring JDBC)
MyBatis
ORM (JPA/Hibernate)
주요 역할
SQL 실행과 쿼리 매핑을 단순화 = 원래는 길었던 코드를 어노테이션으로 간단히 처리
데이터베이스 결과(ResultSet)를 Java 객체로 변환
QueryMapper가 RowMapper를 포함한다.
SQL을 직접 작성해 데이터베이스와 상호작용
객체와 데이터베이스 테이블 간 매핑을 자동화
SQL 작성 방식
직접 작성
직접 작성
직접 작성
자동 생성 (필요 시 JPQL/HQL 작성 가능)
결과 매핑 방식
개발자가 ResultSet 처리
RowMapper 구현체로 각 행을 매핑
XML 또는 애노테이션으로 매핑
엔티티(Entity)와 필드 매핑 자동화
유연성
SQL 중심으로 고도의 유연성을 제공
SQL에 따라 객체 변환이 유연
SQL에 대한 높은 제어 가능
복잡한 쿼리 작성은 어렵지만 기본 작업은 자동화
러닝 커브
낮음
낮음
중간
높음
캐싱 지원 여부
없음
없음
기본적으로 없음
1차 캐시(영속성 컨텍스트) 및 2차 캐시 지원
복잡한 쿼리 지원
가능
가능
가능
JPQL이나 네이티브 SQL로 가능하지만 제약 있음
데이터 변경 반영
직접 SQL 실행 필요
직접 SQL 실행 필요
직접 SQL 실행 필요
객체 변경 시 트랜잭션 커밋 시점에 자동 반영
2. 용어별 간단 설명
JDBC Template
QueryMapper (Spring JDBC)
Spring JDBC의 기능으로, SQL 실행과 매핑을 단순화하기 위한 API.
SQL 쿼리와 매핑 코드를 통합적으로 관리하기 위한 역할을 합니다.
ResultSet을 처리하는 RowMapper와 함께 사용됩니다.
사용 예시:
String sql = "SELECT * FROM users WHERE id = ?";
User user = jdbcTemplate.queryForObject(sql, new Object[]{id}, new UserRowMapper());
RowMapper (Spring JDBC)
ResultSet의 각 행(row)을 Java 객체로 변환하기 위한 인터페이스.
개발자가 필요한 매핑 로직을 직접 작성해야 합니다.
사용 예시:
public class UserRowMapper implements RowMapper<User> {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
return user;
}
}
SQL Mapper
MyBatis
SQL 중심의 SQL Mapper 프레임워크.
SQL을 XML 또는 애노테이션으로 작성하고, 객체와 매핑합니다.
SQL 작성에 대한 유연성을 보장하면서도, 매핑 작업을 간소화합니다.
사용 예시:
<select id="getUserById" parameterType="int" resultType="com.example.User">
SELECT * FROM users WHERE id = #{id}
</select>
ORM (JPA/Hibernate)
ORM (JPA/Hibernate)
객체-관계 매핑(ORM) 프레임워크.
객체와 데이터베이스 테이블을 매핑하여, 객체 지향적으로 데이터베이스 작업을 처리합니다.
데이터베이스와 객체 상태를 자동으로 동기화하며, 트랜잭션 커밋 시점에 데이터베이스에 반영됩니다.
사용 예시:
@Entity
public class User {
@Id
@GeneratedValue
private int id;
private String name;
}
User user = entityManager.find(User.class, 1);
user.setName("Updated Name"); // 데이터베이스에 자동 반영
3. 장단점 비교
QueryMapper/RowMapper (Spring JDBC)
MyBatis
ORM (JPA/Hibernate)
장점
- SQL 제어가 쉬움- 간단한 매핑 로직 구현 가능
- SQL 작성 자유도 높음- 유연한 매핑 가능
- 생산성 높음- 데이터베이스 작업 자동화- 객체 중심 설계 가능
단점
- 반복 코드 많음- 유지보수 어려움
- SQL 작성 필요- 코드 중복 가능성 있음
- 학습 곡선 높음- 복잡한 쿼리 작성 어려움- 오버헤드 가능성
4. 추천 사용 시나리오
사용 시점
QueryMapper/RowMapper
간단한 데이터 처리 작업이나 Spring JDBC 사용 시
MyBatis
SQL 중심의 복잡한 데이터베이스 작업이 필요하거나, 성능 최적화가 중요한 경우
ORM (JPA/Hibernate)
객체 지향적인 설계가 중요한 대규모 프로젝트에서 CRUD 중심의 작업을 빠르게 처리해야 하는 경우
5. 결론
QueryMapper/RowMapper: Spring JDBC를 기반으로 한 저수준의 데이터 처리 도구.
MyBatis: SQL 작성에 자유로우며 복잡한 데이터 처리에 적합한 SQL Mapper.
ORM (JPA/Hibernate): 객체 중심 설계와 데이터베이스 동기화를 자동화하는 고수준 프레임워크.
JpaRepository
📌 JpaRepository는 Spring Data JPA에서 제공하는 인터페이스로, JPA를 사용한 데이터베이스 작업을 간소화하기 위해 제공됩니다. 기본적인 CRUD(Create, Read, Update, Delete) 기능과 더불어 페이징 처리, 정렬, 그리고 커스텀 쿼리 메서드 정의 등을 지원합니다.
실상 ORM 을 사용하는 가장 쉬운 방법입니다.
JpaRepository의 계층 구조
JpaRepository는 Spring Data JPA에서 제공하는 여러 인터페이스 중 하나이며, 계층 구조는 다음과 같습니다:
Repository
모든 Spring Data Repository의 최상위 인터페이스.
마커 인터페이스로, 실제로는 기능을 제공하지 않음.
CrudRepository
기본적인 CRUD 작업(Create, Read, Update, Delete)을 제공하는 인터페이스.
PagingAndSortingRepository
페이징 및 정렬 기능을 추가로 제공하는 인터페이스.
JpaRepository
JPA에서 사용할 수 있는 고급 기능(배치 처리, 페이징, 정렬 등)을 포함한 인터페이스.
JpaRepository가 제공하는 주요 기능
1. CRUD 기능
기본적인 데이터 생성, 조회, 수정, 삭제를 처리하는 메서드를 제공합니다.
메서드
설명
save(S entity)
엔티티를 저장하거나 업데이트합니다.
findById(ID id)
ID를 기반으로 엔티티를 조회합니다.
findAll()
모든 엔티티를 조회합니다.
findAllById(Iterable<ID> ids)
주어진 ID 리스트에 해당하는 엔티티들을 조회합니다.
deleteById(ID id)
주어진 ID에 해당하는 엔티티를 삭제합니다.
deleteAll()
모든 엔티티를 삭제합니다.
2. 페이징 및 정렬
페이징과 정렬을 위한 메서드를 제공합니다.
메서드
설명
findAll(Pageable pageable)
페이징된 결과를 반환합니다.
findAll(Sort sort)
정렬된 결과를 반환합니다.
findAll(Pageable pageable, Sort sort)
페이징과 정렬을 함께 적용하여 결과를 반환합니다.
3. 커스텀 쿼리 메서드
JPA는 메서드 이름을 기반으로 자동으로 SQL 쿼리를 생성해주는 기능을 제공합니다.
메서드 예시
SQL 쿼리로 변환 예시
findByName(String name)
SELECT * FROM Entity WHERE name = ?
findByAgeGreaterThan(int age)
SELECT * FROM Entity WHERE age > ?
findByEmailAndName(String email, String name)
SELECT * FROM Entity WHERE email = ? AND name = ?
findByCreatedAtBetween(Date start, Date end)
SELECT * FROM Entity WHERE created_at BETWEEN ? AND ?
4. 배치 처리
엔티티를 대량으로 저장하거나 삭제할 때 배치 작업을 지원합니다.
메서드
설명
saveAll(Iterable<S> entities)
여러 엔티티를 한 번에 저장합니다.
deleteAllInBatch()
모든 데이터를 배치 방식으로 삭제합니다.
deleteInBatch(Iterable<T> entities)
특정 엔티티들을 배치 방식으로 삭제합니다.
JpaRepository의 사용 방법
1. 엔티티 클래스 작성
먼저 JPA 엔티티를 정의합니다.
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
private String email;
// Getters, Setters, Constructors
}
2. JpaRepository 인터페이스 정의
JpaRepository를 상속받는 인터페이스를 정의합니다.
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
// 추가적으로 사용자 정의 메서드도 선언 가능
User findByEmail(String email);
List<User> findByName(String name);
}
3. Service 또는 Controller에서 사용
UserRepository를 의존성 주입 받아 사용합니다.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(String name, String email) {
User user = new User();
user.setName(name);
user.setEmail(email);
return userRepository.save(user);
}
public List<User> getUsers() {
return userRepository.findAll();
}
public User getUserByEmail(String email) {
return userRepository.findByEmail(email);
}
}
JpaRepository의 장점
생산성 향상:
반복적인 CRUD 작업을 최소화하여 개발 속도를 빠르게 합니다.
자동 쿼리 생성:
메서드 이름을 기반으로 JPA가 자동으로 SQL을 생성합니다.
페이징 및 정렬 지원:
페이징과 정렬이 내장되어 있어 별도의 구현 없이도 쉽게 사용할 수 있습니다.
배치 처리:
대량의 데이터를 처리하는 배치 작업을 쉽게 수행할 수 있습니다.
높은 확장성:
필요에 따라 사용자 정의 메서드나 쿼리를 추가할 수 있습니다.
JpaRepository의 한계
복잡한 쿼리 처리 제한:
매우 복잡한 쿼리는 메서드 이름으로 처리하기 어렵습니다. 이 경우 JPQL 또는 네이티브 쿼리를 사용해야 합니다.
SQL 최적화 제약:
자동 생성된 SQL이 항상 최적화된 형태로 실행되는 것은 아닙니다.
추상화로 인한 성능 이해 어려움:
내부적으로 JDBC를 사용하기 때문에 JPA의 작동 방식을 이해하지 못하면 성능 문제를 분석하기 어려울 수 있습니다.
N+1 문제:
연관된 엔티티를 가져올 때 발생하는 성능 문제를 개발자가 직접 관리해야 합니다.
결론
JpaRepository는 JPA 기반의 데이터베이스 작업을 간소화하기 위해 제공되는 도구로, 생산성이 매우 높습니다.
반복적인 CRUD 작업, 페이징 및 정렬, 배치 처리 같은 작업을 쉽게 처리할 수 있어 대부분의 JPA 기반 프로젝트에서 필수적으로 사용됩니다.
하지만 복잡한 쿼리나 최적화가 필요한 경우, JPQL, 네이티브 SQL, 또는 다른 기술과 함께 사용해야 합니다. 😊
@NoRepositoryBean된 ****상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다. (@NoRepositoryBean= 빈생성 막음 →상속받으면 생성돼서 사용가능)
JpaRepository (마스터 셰프):데이터 액세스를 위한 핵심 기능의 종합적인 요리책(기능) 을 제공합니다.
@NoRepositoryBean 인터페이스 (셰프):각 인터페이스는 특정 데이터 액세스 방법을 제공하는 전문적인 기술 또는 레시피를 나타냅니다.
JpaRepository 상속:마스터 셰프의 요리책과 셰프의 전문성을 얻습니다.
SpringDataJpa 에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다. (상위 인터페이스들의 기능)
Repository 와 JpaRepository 를 통해 얼마나 간단하게 구현하게 될지 미리 확인해볼까요?
Repository 샘플
EntityManager 멤버변수를 직접적으로 사용
// UserRepository.java
@Repository
public class UserRepository {
@PersistenceContext
EntityManager entityManager;
public User insertUser(User user) {
entityManager.persist(user);
return user;
}
public User selectUser(Long id) {
return entityManager.find(User.class, id);
}
}
JpaRepository 샘플
EntityManager 멤버변수를 간접적으로 사용
// UserRepository.java
public interface UserRepository extends JpaRepository<User, Long> {
// 기본 메서드는 자동으로 만들어짐
}
JpaRepository 페이징 및 정렬
페이징 처리 프로세스
PageRequest 생성:
PageRequest.of(page, size)로 페이지 번호와 크기를 설정.
정렬이 필요한 경우 추가적으로 Sort를 전달.
메서드 호출:
Pageable 객체를 JpaRepository 메서드에 전달.
반환값은 Page<T>, Slice<T>, 또는 List<T>로 설정 가능.
응답 처리:
Page<T> 또는 Slice<T> 객체에서 메타정보와 데이터를 추출하여 비즈니스 로직 처리.
주요 클래스 및 메서드
Pageable 생성
기본 생성:
Pageable pageable = PageRequest.of(0, 10); // 페이지 번호: 0, 페이지 크기: 10
@Query("SELECT u.user_name AS userName FROM User u WHERE u.address = :address")
List<User> findByAddress(@Param("address") String address, Sort sort);
// 호출 시
List<User> users = userRepository.findByAddress("Korea", Sort.by("userName").ascending());
CREATE TABLE MEMBER (
MEMBER_ID BIGINT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
home_city VARCHAR(255) NOT NULL,
home_street VARCHAR(255) NOT NULL,
company_city VARCHAR(255) NOT NULL,
company_street VARCHAR(255) NOT NULL,
PRIMARY KEY (MEMBER_ID)
);
3. Collection Value 타입 매핑
@Entity
public class Product {
@Id
@GeneratedValue
private Long id;
@ElementCollection
@CollectionTable(name = "product_tags", joinColumns = @JoinColumn(name = "product_id"))
@Column(name = "tag")
private List<String> tags = new ArrayList<>();
}
생성되는 테이블:
CREATE TABLE product_tags (
product_id BIGINT NOT NULL,
tag VARCHAR(255),
PRIMARY KEY (product_id, tag)
);
특징 및 활용 요약
기본 타입: 일반적인 데이터 저장에 사용되며, 설정 옵션으로 제약조건 지정.
Composite Value 타입: 코드의 응집도를 높이고 복합 데이터를 쉽게 관리.
Collection Value 타입: 여러 값 관리에 유용하지만, 대규모 데이터에서는 다대일 연관관계를 선호.
정리된 특징
JPA는 테이블과 객체 간의 매핑을 위해 다양한 애노테이션을 제공하며, 이를 통해 엔티티를 정의하고 데이터베이스 작업을 쉽게 처리할 수 있습니다.
주요 애노테이션은 @Entity, @Table, @Id, @Column, @GeneratedValue 등으로, 각 애노테이션은 JPA와 데이터베이스 간의 매핑 설정을 세부적으로 제어합니다.
위의 요약은 JPA 애노테이션의 활용 방식과 예제를 포함하여, 데이터베이스 테이블과 객체를 매핑하는 데 필요한 핵심 개념을 다룹니다.
테이블 객체끼리 관계만들기
JPA 애노테이션으로 설정된 매핑 정보를 기반으로JpaRepository가 ORM 기능을 수행합니다.
Raw JPA 연관관계 매핑 기능 요약 표
애노테이션
설명
주요 속성
예시 코드
@OneToOne
- 1:1 관계를 매핑. - 단방향 및 양방향 매핑 가능. - 테이블 분리 여부를 신중히 검토.
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@OneToOne
@JoinColumn(name = "locker_id")
private Locker locker;
}
@Entity
public class Locker {
@Id
@GeneratedValue
private Long id;
}
2. @OneToMany와 @ManyToOne 양방향 매핑
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "parent")
private List<Child> childList;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
3. @ManyToMany 매핑
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
@ManyToMany(mappedBy = "parents")
private List<Child> childs;
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
@ManyToMany
@JoinTable(
name = "parent_child",
joinColumns = @JoinColumn(name = "parent_id"),
inverseJoinColumns = @JoinColumn(name = "child_id")
)
private List<Parent> parents;
}
실무 권장 사항
@ManyToMany 지양: 중간 매핑 테이블을 직접 정의하여 관리.
fetch 기본값 조정: 대부분의 관계를 LAZY로 설정.
단방향 vs 양방향: 필요에 따라 양방향 관계를 신중히 설정.
QueryDSL
📌 Java와 Kotlin 기반 애플리케이션에서 타입 안전(Type-safe)하고, 유연한 쿼리를 작성할 수 있도록 도와주는 SQL 쿼리 빌더 라이브러리입니다. JPA, MongoDB, SQL, JDBC, Elasticsearch 등 다양한 데이터 저장소를 지원하며, 코드 기반으로 동적 쿼리를 간결하게 작성할 수 있도록 설계되었습니다.
1. QueryDSL의 특징
특징
설명
타입 안전
컴파일 타임에 쿼리 오류를 감지할 수 있음.
동적 쿼리 작성
복잡한 동적 쿼리를 간결하고 안전하게 작성 가능.
코드 자동 생성
엔티티 클래스를 기반으로 Q클래스를 자동 생성하여 사용.
JPQL 대체
JPQL보다 간단하고 직관적인 문법 제공.
다양한 데이터 저장소 지원
JPA, SQL, MongoDB, Elasticsearch 등 다양한 환경에서 사용 가능.
String jpql = "SELECT u FROM User u WHERE u.name = :name";
List<User> users = em.createQuery(jpql, User.class)
.setParameter("name", "John")
.getResultList();
QueryDSL
QUser user = QUser.user;
JPAQuery<User> query = new JPAQuery<>(em);
List<User> users = query.select(user)
.from(user)
.where(user.name.eq("John"))
.fetch();
4. QueryDSL의 주요 메서드
메서드
설명
select()
조회할 엔티티나 필드를 지정.
from()
조회 대상 테이블이나 엔티티를 지정.
where()
조건을 추가. (and, or, not 등 지원)
join()
조인 조건을 추가. (innerJoin, leftJoin 등 지원)
groupBy()
그룹화 조건을 추가.
having()
그룹화 조건에 대한 필터 추가.
orderBy()
정렬 조건 추가.
fetch()
결과를 리스트로 반환.
fetchOne()
단일 결과 반환. (결과가 없거나 여러 개일 경우 예외 발생)
fetchFirst()
첫 번째 결과 반환. (결과가 없을 경우 null)
fetchCount()
조회된 데이터의 개수 반환.
fetchResults()
페이징 정보를 포함한 결과 반환 (QueryResults 객체로 반환).
5. QueryDSL 사용 예제
(1) 기본 조회
QUser user = QUser.user;
List<User> users = new JPAQuery<>(em)
.select(user)
.from(user)
.where(user.name.eq("John"))
.fetch();
(2) 동적 쿼리
String nameParam = "John";
Integer ageParam = null;
BooleanBuilder builder = new BooleanBuilder();
if (nameParam != null) {
builder.and(user.name.eq(nameParam));
}
if (ageParam != null) {
builder.and(user.age.eq(ageParam));
}
List<User> users = new JPAQuery<>(em)
.select(user)
.from(user)
.where(builder)
.fetch();
(3) 페이징 처리
QueryResults<User> results = new JPAQuery<>(em)
.select(user)
.from(user)
.where(user.name.contains("John"))
.offset(0) // 시작 인덱스
.limit(10) // 최대 개수
.fetchResults();
long total = results.getTotal(); // 전체 데이터 개수
List<User> users = results.getResults(); // 조회된 데이터
(4) 조인
QOrder order = QOrder.order;
QUser user = QUser.user;
List<Tuple> result = new JPAQuery<>(em)
.select(user.name, order.amount)
.from(order)
.join(order.user, user)
.where(order.amount.gt(100))
.fetch();
(5) 그룹화
List<Tuple> result = new JPAQuery<>(em)
.select(user.age, user.count())
.from(user)
.groupBy(user.age)
.having(user.count().gt(1))
.fetch();
6. QueryDSL의 장단점
장점
타입 안전
컴파일 타임에 쿼리 오류를 감지 가능.
동적 쿼리 작성
복잡한 동적 쿼리를 간결하고 효율적으로 작성 가능.
직관적 문법
JPQL보다 간단하고 직관적인 빌더 패턴 문법 제공.
다양한 저장소 지원
JPA뿐만 아니라 MongoDB, SQL, Elasticsearch 등에서도 사용 가능.
단점
초기 설정의 복잡성
Q클래스 생성 및 Annotation Processor 설정 필요.
배우는 데 시간 필요
QueryDSL 문법과 메서드를 익히는 데 추가적인 학습 시간이 필요.
라이브러리 의존성
QueryDSL에 의존성이 생기므로 JPA 표준이 아닌 부분에서 잠재적 리스크.
7. QueryDSL vs JPQL 비교
QueryDSL
JPQL
타입 안전성
컴파일 타임에 오류를 감지 가능
런타임에 오류 발생 가능
동적 쿼리 작성
동적 쿼리 작성이 간단하고 직관적
동적 쿼리 작성이 복잡하고 번거로움
직관성
메서드 체인 형태로 직관적 작성 가능
문자열로 작성해야 하므로 복잡한 경우 가독성 저하
성능 최적화
동적 쿼리 최적화가 유리
쿼리 최적화는 개발자 몫
8. 결론
QueryDSL은 타입 안전하고 동적 쿼리를 간결하게 작성할 수 있는 강력한 도구입니다. 특히, 동적 쿼리가 빈번하거나, 복잡한 조건이 필요한 프로젝트에서 유용합니다. 다만, 초기 설정과 학습 곡선이 존재하므로, 프로젝트 요구사항에 맞게 QueryDSL을 도입하는 것이 중요합니다.
JDBC, JPA, JPQL, QueryDSL 비교
JDBC
JPA
JPQL
QueryDSL
정의
Java에서 DB와 직접 상호작용하기 위한저수준 API.
객체와 데이터베이스 간 매핑을 자동화하는ORM 프레임워크.
JPA에서 사용되는객체 지향 쿼리 언어.
JPA 기반타입 안전한 쿼리 빌더.
작성 방식
SQL을 직접 작성.
메서드 호출로 DB 작업.
SQL과 유사한 문법으로 JPA 엔티티를 다룸.
Java 코드로 SQL-like 문법 작성.
장점
- 직접 SQL 작성으로세밀한 제어 가능.
-자동화로 개발 생산성 증가.- 데이터베이스 독립성 보장.
- SQL 대신 객체 지향적으로 쿼리 작성 가능.- JPA와 자연스럽게 연동 가능.
-타입 안전성 보장.- 동적 쿼리 작성 용이.- 가독성과 유지보수성 향상.
단점
- 코드가 장황하고 반복적임.- 데이터베이스 종속적.
- 초기 학습 곡선 존재.- 성능 최적화를 위해 추가 설정 필요.
-런타임 시 오류 검출.- 동적 쿼리 작성 어려움.- 가독성이 떨어짐.
- 초기 설정 복잡.- Q 클래스 생성 필요.- 러닝 커브 존재.
사용 시기
-고성능작업이나 데이터베이스 벤더 특화 기능이 필요한 경우.
-일반적인 CRUD 작업과 객체 지향적 접근이 필요한 경우.
- 단순하고 고정된객체 지향 쿼리가 필요한 경우.
- 복잡한동적 쿼리나 타입 안전성을 중시하는 경우.
실행 시점
- SQL 문법이 컴파일 시점에 확인되지 않음(런타임 확인).
- SQL은 자동 생성됨. JPA 설정에 따라 실행.- 런타임 시 SQL 확인 가능.
- 런타임 시 JPQL 파싱 및 실행.- 실행 중 문법 오류 발견.
- SQL 문법을컴파일 시점에 확인 가능.
적용 환경
- 소규모 프로젝트.- SQL 최적화가 중요한 경우.
- 대규모 시스템.- 비즈니스 로직이 복잡한 경우.
- JPA를 사용하는 환경에서 정적 쿼리를 작성할 때.
- 대규모 프로젝트에서 유지보수성 및 가독성이 중요한 경우.
학습 난이도
낮음 (SQL만 익숙하면 사용 가능).
중간 (ORM 개념 및 설정 학습 필요).
중간 (SQL과 유사하지만 JPA 개념 필요).
높음 (JPA와 QueryDSL 문법 학습 필요).
주요 선택 기준
JDBC: SQL에 익숙하며, 데이터베이스에 최적화된 세부 작업이 필요한 경우.
JPA: 객체 지향적으로 데이터를 처리하고, 데이터베이스 독립성을 중시하는 경우.
JPQL: 객체 지향적 쿼리가 필요하지만, 단순한 정적 쿼리 위주로 사용할 때.
QueryDSL: 동적 쿼리와 복잡한 조건 쿼리가 빈번히 요구되며, 가독성과 타입 안전성을 중시할 때.
Auditing
📌 데이터 엔티티의 생성, 수정, 삭제 등과 같은 이벤트 발생 시점을 기록하고 관리하는 기능입니다. JPA와 Spring Data JPA는 Auditing 기능을 지원하며, 데이터 변경 이력을 자동으로 추적하고 기록할 수 있습니다. 주로 엔티티의 생성자, 수정자, 생성일, 수정일과 같은 정보를 관리하는 데 사용됩니다.
1. Auditing 주요 개념
항목
설명
CreatedDate
엔티티가 생성된 날짜를 기록.
LastModifiedDate
엔티티가 마지막으로 수정된 날짜를 기록.
CreatedBy
엔티티를 생성한 사용자(주체)를 기록.
LastModifiedBy
엔티티를 마지막으로 수정한 사용자(주체)를 기록.
자동 추적
엔티티 상태 변화에 따른 감사를 자동으로 기록.
2. Spring Data JPA Auditing 설정
(1) 의존성 추가
Auditing은 Spring Data JPA가 제공하는 기능입니다. spring-boot-starter-data-jpa 의존성을 포함하면 자동으로 사용할 수 있습니다.
import jakarta.persistence.*;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import java.time.LocalDateTime;
@Entity
@EntityListeners(AuditingEntityListener.class) // Auditing 활성화
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@CreatedDate // 생성일 자동 기록
@Column(updatable = false) // 생성일은 수정 불가
private LocalDateTime createdDate;
@LastModifiedDate // 수정일 자동 기록
private LocalDateTime lastModifiedDate;
// Getters and Setters
}
(2) 생성자와 수정자 기록 (CreatedBy, LastModifiedBy)
Auditing에서 생성자와 수정자를 기록하려면 @CreatedBy, **@LastModifiedBy**를 사용합니다. 이를 위해 AuditorAware 구현체를 설정해야 합니다.
AuditorAware 구현
import org.springframework.data.domain.AuditorAware;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class AuditorAwareImpl implements AuditorAware<String> {
@Override
public Optional<String> getCurrentAuditor() {
// 현재 사용자를 반환. SecurityContextHolder 또는 다른 인증 방식 사용 가능
return Optional.of("Admin"); // 예시: "Admin" 사용자로 고정
}
}
Auditing 필드 추가
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.LastModifiedBy;
@Entity
@EntityListeners(AuditingEntityListener.class)
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@CreatedDate
@Column(updatable = false)
private LocalDateTime createdDate;
@LastModifiedDate
private LocalDateTime lastModifiedDate;
@CreatedBy // 생성자 자동 기록
@Column(updatable = false)
private String createdBy;
@LastModifiedBy // 수정자 자동 기록
private String lastModifiedBy;
// Getters and Setters
}
4. Auditing 동작 방식
엔티티 생성: 엔티티가 저장되기 전 @CreatedDate와 @CreatedBy 필드가 자동으로 설정됩니다.
엔티티 수정: 엔티티가 수정되기 전 @LastModifiedDate와 @LastModifiedBy 필드가 자동으로 설정됩니다.
5. Auditing 활용 예제
(1) 데이터 생성
User user = new User();
user.setName("John Doe");
userRepository.save(user); // save 호출 시 createdDate와 createdBy 필드 자동 설정
(2) 데이터 수정
User user = userRepository.findById(1L).orElseThrow();
user.setName("Jane Doe");
userRepository.save(user); // save 호출 시 lastModifiedDate와 lastModifiedBy 필드 자동 업데이트
6. Auditing 주요 어노테이션
어노테이션
설명
@CreatedDate
엔티티가 처음 생성될 때 생성일을 자동 기록.
@LastModifiedDate
엔티티가 수정될 때 수정일을 자동 기록.
@CreatedBy
엔티티가 처음 생성될 때 생성자를 자동 기록.
@LastModifiedBy
엔티티가 수정될 때 수정자를 자동 기록.
@EntityListeners
엔티티 변경 이벤트(AuditingEntityListener 등)를 수신하기 위한 리스너를 지정.
7. Auditing 장단점
장점
자동화: 데이터 변경 이력을 자동으로 기록하여 개발자가 직접 관리할 필요가 없음.
유지보수성: 코드 중복 제거 및 코드의 간결성 향상.
일관성 보장: 데이터 생성 및 수정 작업에서 일관된 이력 기록.
단점
Auditor 설정 필요: 사용자 정보를 기록하려면 AuditorAware를 별도로 구현해야 함.
추가 설정 필요: 기본 Spring Data JPA 설정 외에 Auditing을 활성화해야 함.
8. 주의사항
@CreatedDate와 @LastModifiedDate는 반드시 날짜 타입 필드와 함께 사용해야 함.
AuditorAware 구현 필수
@CreatedBy와 @LastModifiedBy를 사용하려면 AuditorAware 인터페이스를 구현해야 합니다.
필드 업데이트 제한
@CreatedDate와 @CreatedBy는 @Column(updatable = false)로 설정하여 수정되지 않도록 하는 것이 일반적입니다.
트랜잭션 내에서 동작
Auditing은 영속성 컨텍스트와 연관되므로 트랜잭션 내에서만 작동합니다.
9. 결론
Spring Data JPA의 Auditing 기능은 데이터의 생성, 수정, 사용자 정보를 자동으로 기록하고 관리할 수 있는 강력한 도구입니다. 이를 활용하면 변경 이력 관리, 보안 감사 및 데이터 추적과 같은 기능을 효율적으로 구현할 수 있습니다.
Dynamic Insert/Update
📌 JPA 또는 Hibernate에서 엔티티의 변경이 발생할 때, 필요한 필드만으로 SQL을 생성하여 효율적으로 데이터베이스에 반영하는 기능입니다. 불필요한 컬럼을 제외하고 동적으로 SQL을 생성하므로 성능 최적화에 도움을 줄 수 있습니다.
1. Dynamic Insert
기본 동작
Dynamic Insert는 엔티티를 데이터베이스에 저장할 때, NULL이 아닌 값이 있는 필드만 INSERT SQL에 포함합니다.
이를 통해, 기본값을 데이터베이스에서 관리하도록 할 수 있습니다.
예제
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
private LocalDateTime createdDate;
// Getters and Setters
}
엔티티 저장 코드
User user = new User();
user.setName("John"); // email과 createdDate는 NULL 상태
userRepository.save(user);
SQL (Dynamic Insert 활성화 시)
INSERT INTO user (name) VALUES ('John');
-- email, createdDate는 제외
SQL (Dynamic Insert 비활성화 시)
INSERT INTO user (name, email, created_date) VALUES ('John', NULL, NULL);
2. Dynamic Update
기본 동작
Dynamic Update는 엔티티를 수정할 때, 변경된 필드만 UPDATE SQL에 포함합니다.
변경되지 않은 필드는 SQL에서 제외되므로, 불필요한 UPDATE 작업을 방지할 수 있습니다.
예제
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Getters and Setters
}
엔티티 수정 코드
User user = userRepository.findById(1L).orElseThrow();
user.setName("Updated Name"); // email은 변경되지 않음
userRepository.save(user);
SQL (Dynamic Update 활성화 시)
UPDATE user SET name = 'Updated Name' WHERE id = 1;
-- email은 제외
SQL (Dynamic Update 비활성화 시)
UPDATE user SET name = 'Updated Name', email = NULL WHERE id = 1;
3. Dynamic Insert/Update 활성화 방법
(1) Hibernate 어노테이션 사용
Hibernate에서는 **@DynamicInsert**와 @DynamicUpdate 어노테이션을 제공하여 설정할 수 있습니다.
import org.hibernate.annotations.DynamicInsert;
import org.hibernate.annotations.DynamicUpdate;
@Entity
@DynamicInsert // INSERT 시 NULL 필드 제외
@DynamicUpdate // UPDATE 시 변경된 필드만 포함
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Getters and Setters
}
(2) 기본 Hibernate 설정
Hibernate를 사용하는 프로젝트에서 기본 설정으로 적용할 수도 있습니다. 하지만, 엔티티 단위로 제어하는 것이 일반적입니다.
4. Dynamic Insert/Update 장단점
장점
SQL 효율성 증가
NULL 값이나 변경되지 않은 필드를 제외하여 쿼리를 최소화.
데이터베이스에서 기본값을 사용할 수 있음.
성능 최적화
불필요한 작업 감소로 인해 성능 개선.
대량 데이터를 처리할 때 효과적.
코드 간결성
NULL 처리를 수동으로 하지 않아도 됨.
단점
쿼리 복잡성 증가
INSERT/UPDATE 쿼리가 매번 동적으로 생성되므로, 디버깅이 어려울 수 있음.
미리 정의된 기본값 의존성
데이터베이스의 기본값이 변경되거나 의도와 다를 경우 데이터 무결성 문제가 발생할 가능성.
데이터베이스 성능
동적 SQL 생성으로 인해 데이터베이스 캐싱 효율성이 떨어질 수 있음.
5. Dynamic Insert/Update를 사용해야 할 경우
NULL 값이 많고 기본값을 활용해야 하는 경우
데이터베이스의 기본값 설정을 적극 활용하는 설계에서 유리.
대량의 엔티티를 처리할 때 성능이 중요한 경우
INSERT 또는 UPDATE 쿼리에서 불필요한 필드를 줄여 성능을 최적화.
선택적으로 필드를 업데이트해야 하는 경우
예: 특정 필드만 수정해야 하는 REST API 설계.
6. Dynamic Insert/Update를 사용하지 않을 경우
데이터베이스에서 기본값 관리가 필요하지 않은 경우
애플리케이션 레벨에서 NULL 값을 명시적으로 설정하는 경우에는 필요 없음.
SQL 디버깅과 유지보수성 중시
동적 SQL 생성이 디버깅을 어렵게 만들 수 있으므로, 간단한 INSERT/UPDATE 구조를 선호하는 경우.
캐싱 최적화가 중요한 경우
동적 쿼리는 데이터베이스에서 쿼리 캐싱이 어려울 수 있으므로, 정적인 쿼리를 선호하는 경우.
7. 결론
Dynamic Insert와 Dynamic Update는 필요한 필드만으로 동적 SQL을 생성하여 성능을 최적화하고, 데이터베이스의 기본값을 효과적으로 활용할 수 있게 해줍니다. 특히 대량 데이터 처리나 NULL 값이 많은 필드 처리에서 유용하지만, 디버깅 및 유지보수 복잡성을 고려하여 사용해야 합니다.