
프로세스
📌 운영체제로부터 자원을 할당받는 작업의 단위
프로세스 작업 단위
- 프로세스는 “실행 중인 프로그램”을 의미합니다.
- 예를 들어 우리가 Java 프로그램을 실행시키면 이 프로그램은 프로세스라는 이름으로 운영체제 위에서 실행됩니다.
- 즉, OS 위에서 실행되는 모든 프로그램은 OS가 만들어준 프로세스에서 실행됩니다.
- 카카오톡, 브라우저, JAVA 프로그램 모두 프로세스로 실행되며
- 크롬 브라우저를 2개 띄우면 크롬 브라우저 프로세스도 2개가 띄워진 것입니다.

프로세스 구조
📌 OS가 프로그램 실행을 위한 프로세스를 할당해 줄 때 프로세스 안에 프로그램 Code와 Data 그리고 메모리 영역(Stack, Heap)을 함께 할당해 줍니다.
- Code는 Java main 메소드와 같은 코드를 말합니다.
- Data는 프로그램이 실행 중 저장할 수 있는 저장 공간을 의미합니다.
- 전역변수, 정적 변수(static), 배열 등 초기화된 데이터를 저장하는 공간
- Memory (메모리 영역)
- Stack : 지역변수, 매개변수 리턴 변수를 저장하는 공간
- Heap : 프로그램이 동적으로 필요한 변수를 저장하는 공간 (new(), mallock())
쓰레드
📌 프로세스가 할당받은 자원을 이용하는 실행의 단위
- 위 그림처럼 OS는 프로세스 마다 메모리와 CPU 사용량을 할당해 준다.
- 쓰레드 1개 생성 = 프로세스 1개를 실행할 일꾼을 배치 한다는 의미이다.
- 여기서 프로세스는 정해진 자원을 할당받으면 위 처럼 같은 프로세스를 2번 실행하면 자원을 반씩 할당 받는가? 라고 생각할 수 있는데, 프로세스가 할당받은 총 자원의 양은 변하지 않으며, 그 자원을 여러 쓰레드가 협업하며 사용하는 방식이다.
- 흔히 쓰레드는 LIFO나 FIFO 방식으로 운영되다보니 확실히 쓰레드 1개인 프로세스와 2개인 프로세스의 처리 속도는 다를 수 밖에 없다.
쓰레드의 생성
- 프로세스가 작업 중인 프로그램에서 실행 요청이 들어오면 쓰레드(일꾼)을 만들어 명령을 처리하도록 합니다.
쓰레드의 자원
- 프로세스 안에는 여러 쓰레드(일꾼)들이 있고, 쓰레드들은 실행을 위한 프로세스 내 주소 공간이나 메모리 공간(Heap)을 공유 받습니다. (자원에 대한 정보는 프로세스에게 있고 쓰레드는 공유하는 것)
- 추가로, 쓰레드(일꾼)들은 각각 명령 처리를 위한 자신만의 메모리 공간(Stack)도 할당받습니다.
Java 쓰레드
📌 일반 쓰레드와 동일하며 JVM 프로세스 안에서 실행되는 쓰레드를 말합니다.
- Java 프로그램을 실행하면 앞서 배운 JVM 프로세스 위에서 실행됩니다.
- Java 프로그램 쓰레드는 Java Main 쓰레드부터 실행되며 JVM에 의해 실행됩니다.
- = Java는 메인 쓰레드가 main() 메서드를 실행시키면서 시작이 됩니다.
싱글 & 멀티 쓰레드
싱글 쓰레드
📌 프로세스 안에서 하나의 쓰레드만 실행되는 것을 말합니다.
- Java 프로그램의 경우 main() 메서드만 실행시켰을 때 이것을 싱글 쓰레드 라고 합니다.
- 지금까지 코드스니펫을 통해 실습한 모든 Java 프로그램들은 main() 메서드만 실행시켰기 때문에 모두 싱글 쓰레드로 실행되고 있었습니다.
- Java 프로그램 main() 메서드의 쓰레드를 ‘메인 쓰레드’ 라고 부릅니다.
- JVM의 메인 쓰레드가 종료되면, JVM도 같이 종료됩니다.
멀티 쓰레드
📌 프로세스 안에서 여러 개의 쓰레드가 실행되는 것을 말합니다.
- 하나의 프로세스는 여러 개의 실행 단위(쓰레드)를 가질 수 있으며 이 쓰레드들은 프로세스의 자원을 공유합니다.
- Java 프로그램은 메인 쓰레드 외에 다른 작업 쓰레드들을 생성하여 여러 개의 실행 흐름을 만들 수 있습니다.
- 멀티 쓰레드 장점
- 여러 개의 쓰레드(실행 흐름)을 통해 여러 개의 작업을 동시에 할 수 있어서 성능이 좋아집니다.
- 스택을 제외한 모든 영역에서 메모리를 공유하기 때문에 자원을 보다 효율적으로 사용할 수 있습니다.
- 응답 쓰레드와 작업 쓰레드를 분리하여 빠르게 응답을 줄 수 있습니다. (비동기)
- 멀티 쓰레드 단점
- 동기화 문제가 발생할 수 있습니다.
- 프로세스의 자원을 공유하면서 작업을 처리하기 때문에 자원을 서로 사용하려고 하는 충돌이 발생하는 경우를 의미합니다.
- A쓰레드는 자원이 10개 남았다고 들어서 10개 예약했는데, 지금 자원을 쓰고 있는 B가 써보니 자원이 8개 남았다
- 이 과정에서 자원이 얼마 남았는지 쓰레드끼리 서로 정확히 알고 있어야 하는데, 이 서로 알려주는 과정을 동기화라고 한다.
- 교착 상태(데드락)이 발생할 수 있습니다.
- 둘 이상의 쓰레드가 서로의 자원을 원하는 상태가 되었을 때 서로 작업이 종료되기만을 기다리며 작업을 더 이상 진행하지 못하게 되는 상태를 의미합니다.
- A,B 쓰레드 둘다 동시에 자원에 접근하면 코드가 에러가 난다. 병렬처리라고 하지만, 실제로 PC는 아주 빠른 속도로 데이터를 번갈아 가면서 처리하는 것이라 자원은 무조건 하나의 쓰레드만 차지할 수 있다. 근데 A,B가 동시에 요청하면 OS상에서 쓰레드가 중지된다.
- 동기화 문제가 발생할 수 있습니다.
쓰레드의 구현
Thread (클래스)
public class Main {
public static void main(String[] args) {
TestThread thread = new TestThread();
thread.start();
}
}
class TestThread extends Thread {
@Override
public void run() {
for (int i = 0; i <100; i++) {
System.out.print("*");
}
}
}- Java에서 제공하는 Thread 클래스를 상속받아 쓰레드를 구현해 줍니다.
- run() 메서드에 작성된 코드가 쓰레드가 수행할 작업입니다.
Runnable (인터페이스)
public class Main {
public static void main(String[] args) {
Runnable run = new TestRunnable();
Thread thread = new Thread(run);
thread.start();
}
}
class TestRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i <100; i++) {
System.out.print("$");
}
}
}- Java에서 제공하는 Runnable 인터페이스를 사용하여 쓰레드를 구현해 줍니다.
- 여기서의 run() 메서드도 마찬가지로 쓰레드가 수행할 작업입니다.
- 그렇다면 Thread를 직접 상속받아 사용하는 방법이 더 간단해 보이는데 왜? Runnable을 사용하여 쓰레드를 구현하는 방법을 소개해 드렸을까요?
- 바로 클래스와 인터페이스 차이 때문입니다. Java는 다중 상속을 지원하지 않습니다.
- 그렇기 때문에 Thread를 상속받아 처리하는 방법은 확장성이 매우 떨어집니다.
- 반대로 Runnable은 인터페이스이기 때문에 다른 필요한 클래스를 상속받을 수 있습니다.
- 따라서 확정성에 매우 유리합니다.
람다식
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
int sum = 0;
for (int i = 0; i < 50; i++) {
sum += i;
System.out.println(sum);
}
System.out.println(Thread.currentThread().getName() + " 최종 합 : " + sum);
};
Thread thread1 = new Thread(task);
thread1.setName("thread1");
Thread thread2 = new Thread(task);
thread2.setName("thread2");
thread1.start();
thread2.start();
}
}- run() 메서드에 작성했던 쓰레드가 수행할 작업을 실행 블록 { } 안에 작성하시면 됩니다.
- setName() 메서드는 쓰레드에 이름을 부여할 수 있습니다.
- Thread.currentThread().getName() 은 현재 실행 중인 쓰레드의 이름을 반환합니다.
멀티 쓰레드의 처리
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
for (int i = 0; i < 100; i++) {
System.out.print("$");
}
};
Runnable task2 = () -> {
for (int i = 0; i < 100; i++) {
System.out.print("*");
}
};
Thread thread1 = new Thread(task);
thread1.setName("thread1");
Thread thread2 = new Thread(task2);
thread2.setName("thread2");
thread1.start();
thread2.start();
}
}
// 결과
$$$***$$$**$$$***$$***$$$***$$**$$**$$**$*$*$**$$**$**... (등등)- 메인 쓰레드에서 멀티 쓰레드로 여러 개의 작업을 실행해 봅시다.
- $ 와 * 이 순서가 일정하지 않게 출력되는 모습을 볼 수 있습니다.
- 여러 번 실행해서 보면 순서가 정해져 있지 않아 출력의 형태가 계속해서 변화하는 것을 확인할 수 있습니다.
- 즉, 2개의 쓰레드는 서로 번갈아가면서 수행됩니다.
- 여기서 이 두 쓰레드의 실행 순서나 걸리는 시간은 OS의 스케줄러가 처리하기 때문에 알 수 없습니다.
- = 그래서 $$$***$$$**$$$***$$***$$$***$$**$$**$$**$*$*$**$$**$**... 이따구로 나옴...
함수형 인터페이스
📌 단 하나의 추상 메서드만 가지는 인터페이스를 말합니다. 보통 함수를 값으로 전달하기위해 사용됩니다.
- 뒤의 람다식의 이해를 위해 필요한 챕터입니다.
// Car 클래스 내부에 두 메서드 구현
public static boolean hasTicket(Car car) {
return car.hasParkingTicket;
}
public static boolean noTicketButMoney(Car car) {
return !car.hasParkingTicket && car.getParkingMoney() > 1000;
}
함수형 인터페이스를 다음과 같이 정리합니다.
interface Predicate<T> {
boolean test(T t);
}
이 두 함수를 리팩토링
public static List<Car> parkingCarWithTicket(List<Car> carsWantToPark) {
ArrayList<Car> cars = new ArrayList<>();
for (Car car : carsWantToPark) {
if (car.hasParkingTicket()) {
cars.add(car);
}
}
return cars;
}
public static List<Car> parkingCarWithMoney(List<Car> carsWantToPark) {
ArrayList<Car> cars = new ArrayList<>();
for (Car car : carsWantToPark) {
if (!car.hasParkingTicket() && car.getParkingMoney() > 1000) {
cars.add(car);
}
}
return cars;
}- 우리는 함수를 값으로 처리할 수 있게 됐기 때문에, 거의 똑같은 두 개의 함수 따위는 필요가 없다.
- 즉 아래와 같이 수정된다.
// 변경점 1 : Predicate<Car> 인터페이스를 타입 삼아 함수를 전달합니다!
public static List<Car> parkCars(List<Car> carsWantToPark, Predicate<Car> function) {
List<Car> cars = new ArrayList<>();
for (Car car : carsWantToPark) {
// 변경점 2 : 전달된 함수는 다음과 같이 사용됩니다!
if (function.test(car)) {
cars.add(car);
}
}
return cars;
}
< 실제 사용 >
parkingLot.addAll(parkCars(carsWantToPark, Car::hasTicket));
parkingLot.addAll(parkCars(carsWantToPark, Car::noTicketButMoney));- 새로운 문법 Car::hasTicket 이 보이시나요?
- 우리는 함수를 값으로 취급하기 때문에, 함수를 참조로 불러서 쓸 수 있습니다.
- Car 클래스의 hasTicket 함수를 값으로 가져와서 전달하는 부분입니다!
< 예제 >
import java.util.ArrayList;
import java.util.List;
public class LambdaAndStream {
public static void main(String[] args) {
ArrayList<Car> carsWantToPark = new ArrayList<>();
ArrayList<Car> parkingLot = new ArrayList<>();
Car car1 = new Car("Benz", "Class E", true, 0);
Car car2 = new Car("BMW", "Series 7", false, 100);
Car car3 = new Car("BMW", "X9", false, 0);
Car car4 = new Car("Audi", "A7", true, 0);
Car car5 = new Car("Hyundai", "Ionic 6", false, 10000);
carsWantToPark.add(car1);
carsWantToPark.add(car2);
carsWantToPark.add(car3);
carsWantToPark.add(car4);
carsWantToPark.add(car5);
parkingLot.addAll(parkCars(carsWantToPark, Car::hasTicket));
parkingLot.addAll(parkCars(carsWantToPark, Car::noTicketButMoney));
for (Car car : parkingLot) {
System.out.println("Parked Car : " + car.getCompany() + "-" + car.getModel());
}
}
public static List<Car> parkCars(List<Car> carsWantToPark, Predicate<Car> function) {
List<Car> cars = new ArrayList<>();
for (Car car : carsWantToPark) {
if (function.test(car)) {
cars.add(car);
}
}
return cars;
}
}
Car 클래스 내부에 메서드 구현
class Car {
private final String company; // 자동차 회사
private final String model; // 자동차 모델
private final boolean hasParkingTicket;
private final int parkingMoney;
public Car(String company, String model, boolean hasParkingTicket, int parkingMoney) {
this.company = company;
this.model = model;
this.hasParkingTicket = hasParkingTicket;
this.parkingMoney = parkingMoney;
}
public String getCompany() {
return company;
}
public String getModel() {
return model;
}
public boolean hasParkingTicket() {
return hasParkingTicket;
}
public int getParkingMoney() {
return parkingMoney;
}
public static boolean hasTicket(Car car) {
return car.hasParkingTicket;
}
public static boolean noTicketButMoney(Car car) {
return !car.hasParkingTicket && car.getParkingMoney() > 1000;
}
}
함수형 인터페이스를 다음과 같이 정리합니다.
interface Predicate<T> {
boolean test(T t);
}
람다식
📌 Java 8 (함수형 프로그래밍, 병렬의 시작 굉장히 중요한 버전이다.)부터 도입된 기능으로, 익명 함수(이름 없는 함수)를 간단하게 표현할 수 있는 문법입니다. 주로 코드를 간결하게 하고, 함수형 프로그래밍 스타일을 지원하기 위해 사용됩니다.
| 기존 방식 | 람다 |
| Runnable runnable = new Runnable() { @Override public void run() { System.out.println("Hello, World!"); } }; |
() -> System.out.println("Hello, World!"); (매개변수) -> { 함수 본문 } |
// 주말의 주차장 추가
ArrayList<Car> weekendParkingLot = new ArrayList<>();
weekendParkingLot
.addAll(parkCars(carsWantToPark, (Car car) -> car.hasParkingTicket() && car.getParkingMoney() > 1000));
- 새로운 문법! (Car car) -> car.hasParkingTicket() && car.getParkingMoney() > 1000))
- 함수를 값으로 전달하는데, 어딘가에 구현하지 않고 그냥 간단하게 구현해서 넘기고 싶으면 람다식을 이용하면 됩니다!
- 람다식은 “함수 값”으로 평가되며, 한 번만 사용됩니다.
람다 함수의 장점
- 코드 간결성: 익명 클래스보다 간결하고 가독성이 좋음.
- 함수형 프로그래밍 지원: Stream API와 결합해 데이터 처리를 선언적으로 표현.
- 지연 평가 가능: 필요한 시점까지 계산을 미뤄 성능 최적화에 유리.
- 익명 클래스 중복 감소: 반복적인 익명 클래스 코드를 줄여 유지보수성 향상.
- 병렬 처리 지원: Stream API와 함께 멀티코어 병렬 처리에 유리.
람다 함수의 단점
- 디버깅 어려움: 스택 트레이스가 불명확해 오류 추적이 어려울 수 있음.
- 재사용성 제한: 복잡한 로직은 재사용이 어렵고 가독성 저하 가능.
- 가독성 저하 가능성: 다중 중첩된 람다식은 코드 흐름을 파악하기 어려움.
- 한발쏘면 끝나는 샷건으로 간결하고 현재의 상황을 모두 깔끔하게 정리할 수 있지만, 다시 못쓴다...
< 람다 함수 문법 >
// 기본적으로 문법은 다음과 같습니다.
(파라미터 값, ...) -> { 함수 몸체 }
// 아래의 함수 두개는 같은 함수입니다.
// 이름 반환타입, return문 여부에 따라 {}까지도 생략이 가능합니다.
public int toLambdaMethod(int x, int y) {
return x + y;
}
(x, y) -> x + y
// 이런 함수도 가능하겠죠?
public int toLambdaMethod2() {
return 100;
}
() -> 100
// 모든 유형의 함수에 가능합니다.
public void toLambdaMethod3() {
System.out.println("Hello World");
}
() -> System.out.println("Hello World")
스트림
📌 Java 8부터 제공되는 기술로 람다를 활용해컬렉션(또는 배열)을 함수형으로 간단하게 처리하기 위한 API로, 함수형 프로그래밍 스타일을 지원하는 매우 강력한 도구입니다. 스트림을 사용하면 데이터 처리를 선언적이고 간결하게 할 수 있으며, 병렬 처리와 같은 고급 기능도 지원합니다.
- 스트림은 정확하게는 Java 8부터 제공되는, 한 번 더 추상화된 자료구조와 자주 사용하는 프로그래밍 API를 제공한 것입니다. 자료구조를 한 번 더 추상화했기 때문에, 자료구조의 종류에 상관없이 같은 방식으로 다룰 수 있습니다.
- ( + 병렬 처리에 유리한 구조로 조건부로 성능도 챙길 수 있습니다.)
- 조금 더 쉽게 “비유” 하자면, 자료구조의 “흐름”을 객체로 제공해 주고, 그 흐름 동안 사용할 수 있는 메서드들을 api로 제공해 주고 있는 것이죠 일단은 “자료구조” (리스트, 맵, 셋 등)의 흐름이라고 비유하면 이해가 조금 더 쉬울 것 같습니다.
- 스트림 메서드는 collection에 정의되어 있기 때문에, 모든 컬렉션을 상속하는 구현체들은 스트림을 반환할 수 있습니다.
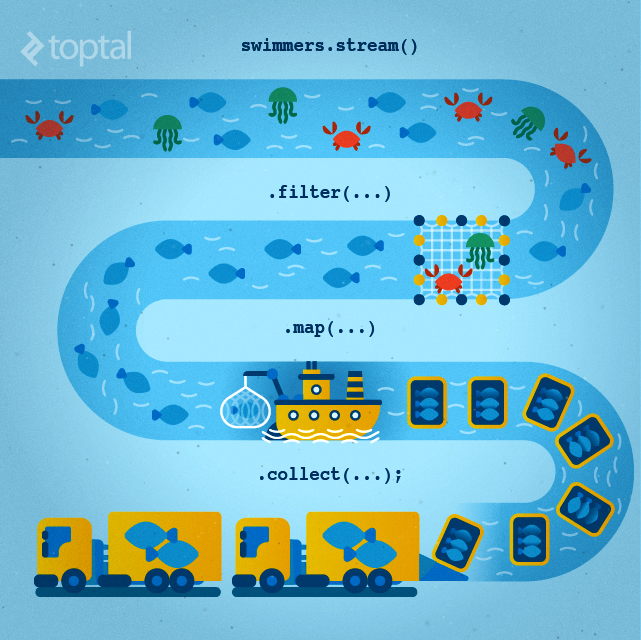
- 말이 어려운데, 보통 우리가 데이터를 다룰때 각 자료구조마다 약간씩은 사용방식이 다른 경우가 많다.
- 예를 들면, List를 정렬할 때는 Collections.sort()를 사용하고, 배열을 정렬할 때는 Arrays.sort()를 사용한다
- 비슷한 기능들을 하나의 방식으로 통일해서 사용할 수 없을까? 에서 시작한 것이 스트림이다.
- 스트림은 데이터 소스가 무엇이던 다 통일하여 같은 방식으로 다룰 수 있게 해준다.
- 그래서 자료구조를 추상화 했다는 말이 나오는 것
- 더 나아가 하나의 "흐름" 처럼 위 그림과 같이 과정을 연속적으로 처리한다.
List<String> filteredList = namesList.stream() // List를 스트림으로 변환
.filter(name -> name.startsWith("A") || name.startsWith("B")) // A 또는 B로 시작하는 이름 필터링
.sorted() // 알파벳 순 정렬
.map(String::toUpperCase) // 대문자로 변환
.collect(Collectors.toList()); // List로 변환- 정말 그냥 대놓고 1열로 나열해 버린다.
< 예시 >
import java.util.*;
import java.util.stream.*;
public class WithoutStreamExample {
// 스트림 적용 안한 상태
public static void main(String[] args) {
// 1. List를 필터링, 정렬, 변환하는 작업
List<String> namesList = Arrays.asList("Alice", "Bob", "Charlie", "David");
♣////////////////////////////////////////////////////////////////////////////////
List<String> filteredList = new ArrayList<>();
for (String name : namesList) {
if (name.startsWith("A") || name.startsWith("B")) { // A 또는 B로 시작하는 이름 필터링
filteredList.add(name.toUpperCase()); // 대문자로 변환
}
}
Collections.sort(filteredList); // 알파벳 순 정렬
////////////////////////////////////////////////////////////////////////////////
System.out.println("Filtered List without Stream: " + filteredList);
public static void main(String[] args) {
// 스트림 적용한 상태
// 1. List를 스트림을 통해 필터링, 정렬, 변환하는 작업
List<String> namesList = Arrays.asList("Alice", "Bob", "Charlie", "David");
★////////////////////////////////////////////////////////////////////////////////
List<String> filteredList = namesList.stream() // List를 스트림으로 변환
.filter(name -> name.startsWith("A") || name.startsWith("B")) // A 또는 B로 시작하는 이름 필터링
.sorted() // 알파벳 순 정렬
.map(String::toUpperCase) // 대문자로 변환
.collect(Collectors.toList()); // List로 변환
////////////////////////////////////////////////////////////////////////////////
System.out.println("Filtered List with Stream: " + filteredList);
}}- 기존의 방식(♣)은 for, if, 외부 메서드 호출을 통해 여러 과정을 거쳐 filter(구분) 하거나 collect(수집) 해야했지만
- 스트림(★)은 filter, map, collect와 같은 기능이 이미 구현이 되어있고, 1열로 그냥 나열해서 써도 되다보니 간결하고 처리가 빠르다.
- 스트림을 사용하지 않은 방식에서는 for 루프와 조건문을 활용하여 데이터를 필터링하고, 별도의 메서드(Collections.sort)로 정렬을 수행하며, 최종적으로 변환을 진행했습니다.
- 코드가 길어지고, 각 작업 단계가 명확하게 분리되지 않아 가독성이 떨어질 수 있습니다.
- List와 배열을 다룰 때 처리 방식에 차이가 있으며, 필터링과 변환 작업을 추가할수록 코드 복잡도가 높아집니다.
- 스트림을 사용한 방식에서는 filter, sorted, map, collect 등 스트림 메서드를 체인 형태로 연결하여 간결하고 일관된 방식으로 데이터를 처리했습니다.
- List와 배열을 동일한 스트림 메서드로 처리하여 코드의 일관성이 높아집니다.
- 각 작업이 명확하게 분리되고 체이닝으로 연결되어 있어 가독성과 유지보수성이 크게 향상됩니다.
+ 체인 형태 : 메서드를 연달아 호출하여 작업을 순차적으로 처리하는 방식
스트림의 특징
- 원본 데이터 불변성: 스트림은 데이터를 읽거나 쓰는 동안 원본 데이터를 변경하지 않습니다. 스트림이 데이터를 처리하는 방식은 원본 데이터의 복사본을 사용하여 전달하고 처리하는 방식이므로, 데이터가 변조되지 않습니다.
- 일회성(단일 소비 가능): 스트림은 한 번 사용되면 재사용할 수 없습니다. 데이터를 읽는 스트림은 데이터를 한 번 읽고 나면 다시 읽을 수 없으며, 새로운 스트림을 만들어야 합니다. 이런 특성은 자바의 java.util.stream 패키지의 스트림에도 적용되며, 데이터 처리 후 스트림이 자동으로 소멸됩니다.
- 단방향성: 스트림은 데이터를 한 방향으로만 전달합니다. 읽기와 쓰기는 각각 별도의 스트림을 사용해야 하며, 데이터를 주고받으려면 각각 입력 스트림과 출력 스트림을 따로 생성해야 합니다.
- 연속성: 스트림은 데이터를 끊김 없이 연속적으로 처리합니다. 이는 파일이나 네트워크 통신에서 특히 유용하며, 데이터를 필요한 순간에 조금씩 처리해 메모리 사용량을 줄입니다.
- 시간 지연 최소화: 스트림은 데이터를 즉시 처리하거나 대기하지 않고 바로 전달하므로, 실시간 처리가 중요한 작업에 적합합니다. 네트워크에서 데이터가 도착하는 즉시 처리할 수 있도록 설계되었습니다.
- 추상화된 데이터 처리: 스트림은 데이터 소스(파일, 네트워크, 메모리 등)와 데이터가 전달될 위치(출력 화면, 파일 등)를 추상화하여 개발자가 데이터의 출처에 관계없이 동일한 방식으로 처리할 수 있게 해줍니다.
- 버퍼링 지원: 스트림에는 버퍼를 사용하여 데이터 전송 속도를 최적화할 수 있는 클래스(BufferedInputStream, BufferedReader 등)가 있습니다. 버퍼링된 스트림은 데이터가 일정량 모였을 때 한 번에 읽거나 쓰는 방식으로 성능을 향상시킵니다.
- 다양한 데이터 타입 지원: 바이트 스트림과 문자 스트림처럼 서로 다른 데이터 타입을 처리할 수 있는 다양한 스트림이 제공됩니다. 바이트 스트림(InputStream, OutputStream)은 이진 데이터를, 문자 스트림(Reader, Writer)은 텍스트 데이터를 처리하는 데 사용됩니다.
- 필터링과 연결 가능: 필터 스트림(FilterInputStream, FilterOutputStream 등)은 스트림에 필터 기능을 추가할 수 있습니다. 예를 들어, BufferedInputStream을 사용해 버퍼링을 추가하거나, DataInputStream을 통해 기본 데이터 타입을 처리할 수 있습니다. 스트림을 체인처럼 연결하여 다단계로 처리가 가능합니다.
스트림은 왜 필요할까?
1. 효율적인 데이터 처리
- 연속적 데이터 처리: 스트림은 데이터를 한 번에 모두 불러오지 않고, 필요할 때 필요한 만큼만 읽거나 씁니다. 대용량 파일, 실시간 네트워크 데이터, 영상 스트리밍 등을 처리할 때 메모리를 절약하고 성능을 높일 수 있습니다.
- 버퍼링으로 성능 개선: 스트림의 버퍼링 기능(BufferedInputStream, BufferedReader 등)은 데이터를 임시로 저장해 두었다가 한 번에 처리함으로써 IO 성능을 향상시키고 대기 시간을 줄입니다.
2. 코드 간소화와 유지보수성 향상
- 고수준 추상화 제공: 스트림을 사용하면 데이터 소스와 관계없이 일관된 방식으로 데이터를 처리할 수 있습니다. 예를 들어, 파일, 네트워크, 메모리에서 데이터를 읽거나 쓸 때 동일한 인터페이스를 사용하여 코드의 가독성이 높아지고 유지보수가 쉬워집니다.
- 필터링과 변환 용이: 스트림은 체이닝을 통해 여러 필터와 변환 기능을 연달아 적용할 수 있습니다. 데이터 처리를 단일 흐름으로 작성할 수 있어 복잡한 로직을 간결하게 구현할 수 있습니다.
3. 원본 데이터 보호
- 불변성 유지: 스트림을 통해 데이터를 처리하면 원본 데이터는 그대로 유지되고, 필요할 경우 스트림의 복사본을 사용하여 데이터를 읽고 씁니다. 이로 인해 데이터 무결성을 보호할 수 있습니다.
4. 병렬 처리와 실시간 데이터 처리에 유리
- 실시간 처리: 네트워크 소켓에서 전송되는 데이터나 파일에서 실시간으로 읽어와야 하는 경우, 스트림을 사용하면 데이터가 도착할 때마다 바로 처리할 수 있습니다.
- 병렬 처리: 자바 8의 Stream API는 대량 데이터를 병렬 처리할 수 있어 멀티코어 CPU 환경에서 성능을 최적화할 수 있습니다.
5. 다양한 데이터 타입 지원
- 스트림은 바이트와 문자 기반으로 나뉘어 다양한 데이터 타입을 지원합니다. 이진 데이터(이미지, 영상 파일 등)나 텍스트 데이터 모두 쉽게 처리할 수 있는 클래스를 제공해 개발자가 데이터의 형태에 맞는 스트림을 선택해 사용할 수 있습니다.
스트림을 사용하는 방법
| 1. 스트림을 받아오기 (.stream()) |
| carsWantToPark.stream() |
| 2. 스트림 가공하기 |
| .filter((Car car) -> car.getCompany().equals("Benz")) |
| 3. 스트림 결과 만들기 |
| .toList(); |
스트림 API
- https://www.baeldung.com/java-8-streams
- 위는 스트림에서 제공하는 사이트로, 스트림 api 종류에 관해 상세히 기술되어 있다.
- 아래는 자주 사용하는 api 메서드들이다.
import java.util.*;
import java.util.stream.*;
public class StreamApiExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Edward", "Frank");
// 1. filter: 특정 조건에 맞는 요소만 걸러냄
List<String> filteredNames = names.stream()
.filter(name -> name.startsWith("A") || name.startsWith("D")) // A나 D로 시작하는 이름
.collect(Collectors.toList());
System.out.println("Filtered Names: " + filteredNames);
// 2. map: 각 요소를 다른 값으로 변환
List<String> upperCaseNames = names.stream()
.map(String::toUpperCase) // 대문자로 변환
.collect(Collectors.toList());
System.out.println("Upper Case Names: " + upperCaseNames);
// 3. sorted: 정렬
List<String> sortedNames = names.stream()
.sorted() // 기본 알파벳 순 정렬
.collect(Collectors.toList());
System.out.println("Sorted Names: " + sortedNames);
// 4. distinct: 중복 제거
List<String> namesWithDuplicates = Arrays.asList("Alice", "Bob", "Alice", "Charlie", "Bob");
List<String> distinctNames = namesWithDuplicates.stream()
.distinct() // 중복 제거
.collect(Collectors.toList());
System.out.println("Distinct Names: " + distinctNames);
// 5. limit: 앞에서부터 n개의 요소만 선택
List<String> limitedNames = names.stream()
.limit(3) // 처음 3개의 이름만 선택
.collect(Collectors.toList());
System.out.println("Limited Names: " + limitedNames);
// 6. skip: 앞에서부터 n개의 요소 건너뛰기
List<String> skippedNames = names.stream()
.skip(2) // 처음 2개의 이름 건너뛰기
.collect(Collectors.toList());
System.out.println("Skipped Names: " + skippedNames);
// 7. anyMatch: 조건을 만족하는 요소가 하나라도 있는지 확인
boolean hasNameStartingWithC = names.stream()
.anyMatch(name -> name.startsWith("C"));
System.out.println("Any name starts with 'C': " + hasNameStartingWithC);
// 8. allMatch: 모든 요소가 조건을 만족하는지 확인
boolean allNamesStartWithA = names.stream()
.allMatch(name -> name.startsWith("A"));
System.out.println("All names start with 'A': " + allNamesStartWithA);
// 9. noneMatch: 모든 요소가 조건을 만족하지 않는지 확인
boolean noNameStartsWithZ = names.stream()
.noneMatch(name -> name.startsWith("Z"));
System.out.println("No name starts with 'Z': " + noNameStartsWithZ);
// 10. reduce: 모든 요소를 하나의 값으로 합침
Optional<String> concatenatedNames = names.stream()
.reduce((name1, name2) -> name1 + ", " + name2); // 모든 이름을 콤마로 연결
concatenatedNames.ifPresent(result -> System.out.println("Concatenated Names: " + result));
// 11. count: 스트림의 총 요소 수 계산
long nameCount = names.stream()
.count();
System.out.println("Count of Names: " + nameCount);
// 12. collect: 결과를 특정 컬렉션으로 수집
Set<String> nameSet = names.stream()
.collect(Collectors.toSet()); // Set으로 수집
System.out.println("Names as Set: " + nameSet);
}
}
스트림에 대해 더 자세히 알고 싶다면 추천하는 사이트는 https://hstory0208.tistory.com/entry/Java%EC%9E%90%EB%B0%94-Stream%EC%8A%A4%ED%8A%B8%EB%A6%BC%EC%9D%B4%EB%9E%80 여기다.
데몬 쓰레드
📌 일반적인 사용자 쓰레드와 달리, 백그라운드에서 실행되는 쓰레드입니다. 이 쓰레드는 주 쓰레드가 종료되면 자동으로 종료되는 특징이 있습니다. 주로 백그라운드에서 실행되어 보조적인 작업을 수행하며, 주 쓰레드가 모든 작업을 끝내면 남아 있는 데몬 쓰레드도 종료됩니다.
+ 보조적인 역할을 담당하며 대표적인 데몬 쓰레드로는 메모리 영역을 정리해 주는 가비지 컬렉터(GC)가 있다.
public class Main {
public static void main(String[] args) {
Runnable demon = () -> {
for (int i = 0; i < 1000000; i++) {
System.out.println("demon");
}
};
Thread thread = new Thread(demon);
thread.setDaemon(true);
thread.start();
for (int i = 0; i < 100; i++) {
System.out.println("task");
}
}
}
- demon 쓰레드는 우선순위가 낮고 다른 쓰레드가 모두 종료되면 강제 종료 당하기 때문에 main() 쓰레드의 task가 100번이 먼저 찍히면 종료되어 1000000번 수행이 되지 않고 종료됩니다.
사용자 쓰레드
📌 일반적인 프로그램의 주 작업을 수행하는 쓰레드입니다. 자원을 활용해 특정 작업을 수행하며, 모든 사용자 쓰레드가 종료될 때까지 프로그램이 계속 실행됩니다. 이는 데몬 쓰레드와 달리, 사용자 쓰레드가 실행 중인 한 JVM이 종료되지 않는다는 특징이 있습니다.
+ 프로그램 기능을 담당하며 대표적인 사용자 쓰레드로는 메인 쓰레드가 있습니다.
사용자 쓰레드의 특징
- 주요 작업 담당
- 프로그램의 핵심 작업을 담당하며, 직접적인 연산, 데이터 처리, 입출력 등 다양한 작업을 수행합니다.
- 모든 사용자 쓰레드가 종료되어야 JVM이 종료
- 프로그램 내 모든 사용자 쓰레드가 종료되지 않으면 JVM이 계속 실행됩니다. 반면, 사용자 쓰레드가 모두 종료되면 데몬 쓰레드가 남아있어도 프로그램은 종료됩니다.
- 데몬 쓰레드와 구분
- 기본적으로 생성되는 모든 쓰레드는 사용자 쓰레드로 설정되어 있으며, 명시적으로 setDaemon(true)를 호출하지 않는 한 사용자 쓰레드입니다.
public class Main {
public static void main(String[] args) {
Runnable userTask = () -> {
try {
for (int i = 0; i < 5; i++) {
System.out.println("사용자 쓰레드 작업 중...");
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("사용자 쓰레드 종료");
};
Thread userThread = new Thread(userTask); // 사용자 쓰레드로 설정
userThread.start();
System.out.println("메인 쓰레드 종료");
}
}
메인 쓰레드 종료
사용자 쓰레드 작업 중...
사용자 쓰레드 작업 중...
사용자 쓰레드 작업 중...
사용자 쓰레드 작업 중...
사용자 쓰레드 작업 중...
사용자 쓰레드 종료
설명: 사용자 쓰레드가 모두 종료되기 전에는 JVM이 계속 실행되기 때문에, 메인 쓰레드가 종료된 이후에도 프로그램이 끝나지 않고 사용자 쓰레드의 작업이 끝날 때까지 실행됩니다.
- 사실 데몬 선언 없이 만드는 코드는 전부 사용자 쓰레드로 실행된다.
- 그냥 코드를 짜면 다 사용자 쓰레드라는 것
쓰레드 우선순위
📌쓰레드 작업의 중요도에 따라서 쓰레드의 우선순위를 부여할 수 있습니다.
- 작업의 중요도가 높을 때 우선순위를 높게 지정하면 더 많은 작업시간을 부여받아 빠르게 처리될 수 있습니다.
- 쓰레드는 생성될 때 우선순위가 정해집니다.
- 이 우선순위는 우리가 직접 지정하거나 JVM에 의해 지정될 수 있습니다.
- 우선순위는 아래와 같이 3가지 (최대/최소/보통) 우선순위로 나뉩니다.
- 최대 우선순위 (MAX_PRIORITY) = 10
- 최소 우선순위 (MIN_PRIORITY) = 1
- 보통 우선순위 (NROM_PRIORITY) = 5
- 기본 값이 보통 우선순위입니다.
- 더 자세하게 나눈다면 1~10 사이의 숫자로 지정 가능합니다.
- 이 우선순위의 범위는 OS가 아니라 JVM에서 설정한 우선순위입니다.
- 스레드 우선순위는 setPriority() 메서드로 설정할 수 있습니다.
- getPriority()로 우선순위를 반환하여 확인할 수 있습니다.
public class Main {
public static void main(String[] args) {
Runnable task1 = () -> {
for (int i = 0; i < 100; i++) {
System.out.print("$");
}
};
Runnable task2 = () -> {
for (int i = 0; i < 100; i++) {
System.out.print("*");
}
};
Thread thread1 = new Thread(task1);
thread1.setPriority(8);
int threadPriority = thread1.getPriority();
System.out.println("threadPriority = " + threadPriority);
Thread thread2 = new Thread(task2);
thread2.setPriority(2);
thread1.start();
thread2.start();
}
}
쓰레드 그룹
📌 여러 개의 쓰레드를 그룹으로 묶어 관리하고 제어할 수 있도록 해주는 Java의 기능입니다. 이를 통해 관련된 쓰레드를 하나의 단위로 묶어 일괄 처리하거나, 특정 그룹에 속한 쓰레드들에 대해 동시에 작업을 수행하는 것이 가능합니다.
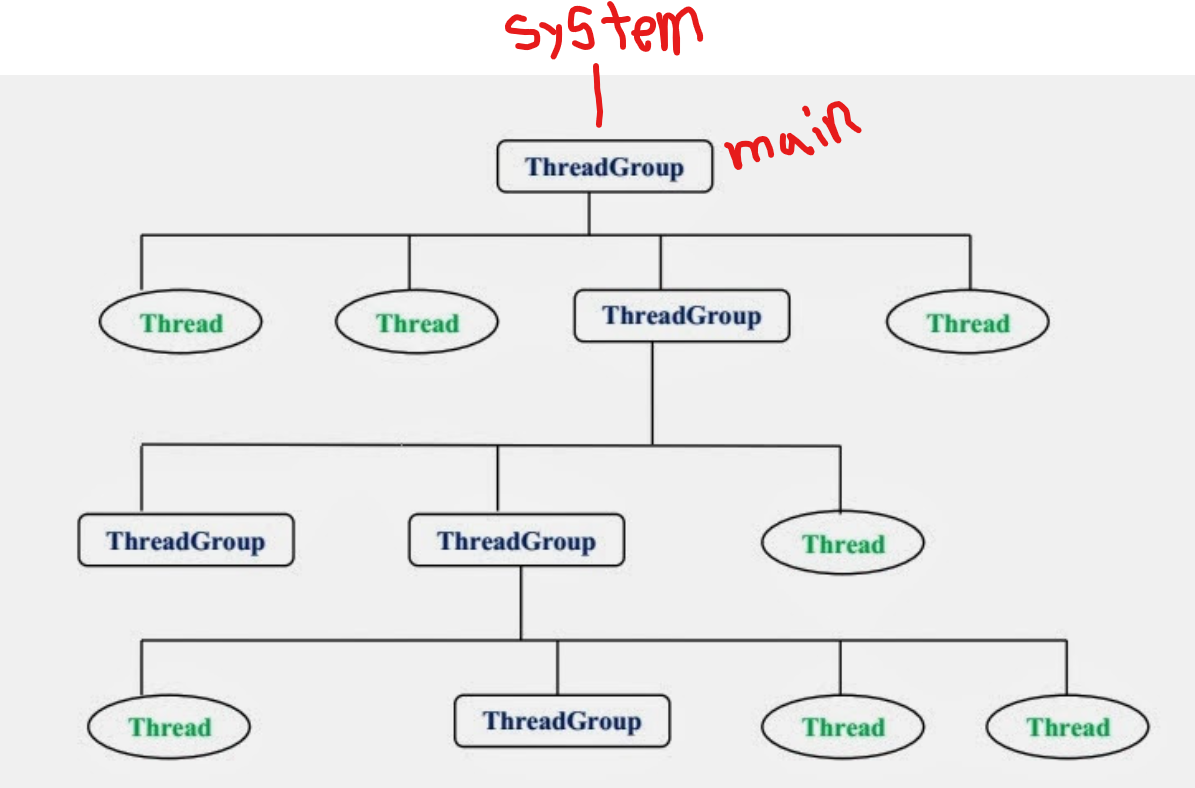
- 쓰레드들은 기본적으로 그룹에 포함되어 있습니다.
- JVM 이 시작되면 system 그룹이 생성되고 쓰레드들은 기본적으로 system 그룹에 포함됩니다.
- 메인 쓰레드는 system 그룹 하위에 있는 main 그룹에 포함됩니다.
- 모든 쓰레드들은 반드시 하나의 그룹에 포함되어 있어야 합니다.
- 쓰레드 그룹을 지정받지 못한 쓰레드는 자신을 생성한 부모 쓰레드의 그룹과 우선순위를 상속받게 되는데 우리가 생성하는 쓰레드들은 main 쓰레드 하위에 포함됩니다.
- 따라서 쓰레드 그룹을 지정하지 않으면 해당 쓰레드는 자동으로 main 그룹에 포함됩니다.
쓰레드 그룹 생성
- ThreadGroup 클래스로 객체를 만들어서 Thread 객체 생성 시 첫 번째 매개변수로 넣어주면 됩니다.
// ThreadGroup 클래스로 객체를 만듭니다.
ThreadGroup group1 = new ThreadGroup("Group1");
// Thread 객체 생성시 첫번째 매개변수로 넣어줍니다.
// Thread(ThreadGroup group, Runnable target, String name)
Thread thread1 = new Thread(group1, task, "Thread 1");
// Thread에 ThreadGroup 이 할당된것을 확인할 수 있습니다.
System.out.println("Group of thread1 : " + thread1.getThreadGroup().getName());
쓰레드 그룹으로 묶어서 쓰레드 관리
- ThreadGroup 객체의 interrupt() 메서드를 실행시키면 해당 그룹 쓰레드들이 실행 대기 상태로 변경됩니다.
// ThreadGroup 클래스로 객체를 만듭니다.
ThreadGroup group1 = new ThreadGroup("Group1");
// Thread 객체 생성시 첫번째 매개변수로 넣어줍니다.
// Thread(ThreadGroup group, Runnable target, String name)
Thread thread1 = new Thread(group1, task, "Thread 1");
Thread thread2 = new Thread(group1, task, "Thread 2");
// interrupt()는 일시정지 상태인 쓰레드를 실행대기 상태로 만듭니다.
group1.interrupt();
< 예제 >
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
while (!Thread.currentThread().isInterrupted()) {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
break;
}
}
System.out.println(Thread.currentThread().getName() + " Interrupted");
};
// ThreadGroup 클래스로 객체를 만듭니다.
ThreadGroup group1 = new ThreadGroup("Group1");
// Thread 객체 생성시 첫번째 매개변수로 넣어줍니다.
// Thread(ThreadGroup group, Runnable target, String name)
Thread thread1 = new Thread(group1, task, "Thread 1");
Thread thread2 = new Thread(group1, task, "Thread 2");
// Thread에 ThreadGroup 이 할당된것을 확인할 수 있습니다.
System.out.println("Group of thread1 : " + thread1.getThreadGroup().getName());
System.out.println("Group of thread2 : " + thread2.getThreadGroup().getName());
thread1.start();
thread2.start();
try {
// 현재 쓰레드를 지정된 시간동안 멈추게 합니다.
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// interrupt()는 일시정지 상태인 쓰레드를 실행대기 상태로 만듭니다.
group1.interrupt();
}
}
쓰레드 상태
📌 우리는 동영상을 보거나 음악을 듣고 있을 때 일시정지 후에 다시 보거나 듣기도 하고 중간에 종료 시키기도 합니다. 쓰레드도 마찬가지로 상태가 존재하고 이를 제어를 할 수 있습니다.
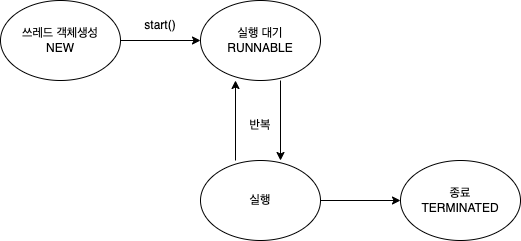
- 이처럼 쓰레드는 실행과 대기를 반복하며 run() 메서드를 수행합니다.
- run() 메서드가 종료되면 실행이 멈추게 됩니다.
쓰레드 상태 종류
|
상태
|
Enum
|
설명
|
|
객체생성
|
NEW
|
쓰레드 객체 생성, 아직 start() 메서드 호출 전의 상태
|
|
실행대기
|
RUNNABLE
|
실행 상태로 언제든지 갈 수 있는 상태
|
|
일시정지
|
WAITING
|
다른 쓰레드가 통지(notify) 할 때까지 기다리는 상태
|
|
일시정지
|
TIMED_WAITING
|
주어진 시간 동안 기다리는 상태
|
|
일시정지
|
BLOCKED
|
사용하고자 하는 객체의 Lock이 풀릴 때까지 기다리는 상태
|
|
종료
|
TERMINATED
|
쓰레드의 작업이 종료된 상태
|
NEW (새 상태)
- 설명: 쓰레드가 생성되었지만 아직 시작되지 않은 상태입니다.
- 특징: new Thread()를 호출하여 객체를 생성했지만 start() 메서드를 호출하지 않은 상태입니다.
2. RUNNABLE (실행 가능 상태)
- 설명: 실행 중이거나 실행 준비가 된 상태입니다.
- 특징: start()가 호출되어 쓰레드가 스케줄러에 의해 실행될 준비가 되었을 때입니다. CPU가 사용 가능하면 실행됩니다.
- 예시: RUNNABLE 상태는 대기 중이지만 곧 CPU에서 실행될 수 있는 상태도 포함됩니다.
3. BLOCKED (블로킹 상태)
- 설명: 다른 쓰레드가 사용 중인 리소스(예: synchronized 블록)를 기다리는 상태입니다.
- 특징: 락(lock)을 얻지 못해 일시적으로 실행할 수 없는 상태입니다. 예를 들어, synchronized 블록에 접근하려 했으나 이미 다른 쓰레드가 해당 블록에 들어가 있을 때 발생합니다.
4. WAITING (대기 상태)
- 설명: 다른 쓰레드가 특정 작업을 완료할 때까지 대기하는 상태입니다.
- 특징: wait() 메서드 호출, join() 메서드 호출 시 대기 상태가 됩니다. 지정된 조건이 충족되어야 다음 단계로 넘어갈 수 있습니다.
- 예시: 특정 쓰레드가 종료될 때까지 join()을 호출해 기다리거나, Object.wait()를 호출한 경우.
5. TIMED_WAITING (시간 지정 대기 상태)
- 설명: 지정된 시간 동안 기다리는 상태입니다.
- 특징: 특정 시간 동안 기다리며, 시간이 지나면 자동으로 RUNNABLE 상태로 돌아갑니다. sleep(time), wait(time), join(time), LockSupport.parkNanos(), LockSupport.parkUntil() 등이 있습니다.
- 예시: Thread.sleep(1000);는 1초간 TIMED_WAITING 상태가 됩니다.
6. TERMINATED (종료 상태)
- 설명: 쓰레드가 종료된 상태입니다.
- 특징: 쓰레드의 작업이 완료되거나, 예외로 인해 종료된 경우입니다. 이 상태에서는 다시 실행할 수 없습니다.
쓰레드 제어
📌 쓰레드의 실행을 관리하고, 여러 쓰레드 간의 작업을 조정하는 과정입니다.
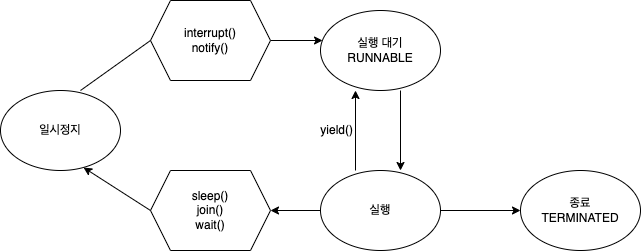
start()
📌 쓰레드를 시작하는 메서드로, 쓰레드를 NEW 상태에서 RUNNABLE 상태로 전환시킵니다.
- start() 메서드를 호출해야만 쓰레드가 실행을 시작할 수 있으며, 이를 호출하지 않으면 쓰레드는 시작되지 않습니다.
Thread thread = new Thread(task);
thread.start(); // 쓰레드 시작
sleep()
📌 현재 쓰레드를 지정된 시간 동안 멈추게 합니다.
- sleep()은 쓰레드 자기 자신에 대해서만 멈추게 할 수 있습니다.
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task : " + Thread.currentThread().getName());
};
Thread thread = new Thread(task, "Thread");
thread.start();
try {
thread.sleep(1000);
System.out.println("sleep(1000) : " + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- Thread.sleep(ms); ms(밀리초) 단위로 설정됩니다.
- 예외 처리를 해야 합니다.
- sleep 상태에 있는 동안 interrupt()를 만나면 다시 실행되기 때문에 InterruptedException이 발생할 수 있습니다.
interrupt()
📌 일시정지 상태인 쓰레드를 실행 대기 상태로 만듭니다.
public class Thread implements Runnable {
/* Make sure registerNatives is the first thing <clinit> does. */
private static native void registerNatives();
static {
registerNatives();
}
private volatile String name;
private int priority;
/* Whether or not the thread is a daemon thread. */
private boolean daemon = false;
/* Interrupt state of the thread - read/written directly by JVM */
private volatile boolean interrupted;
...
public void interrupt() {
if (this != Thread.currentThread()) {
checkAccess();
// thread may be blocked in an I/O operation
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupted = true;
interrupt0(); // inform VM of interrupt
b.interrupt(this);
return;
}
}
}
interrupted = true;
// inform VM of interrupt
interrupt0();
}
...
public boolean isInterrupted() {
return interrupted;
}
}- Thread 클래스 내부에 interrupted 되었는지를 체크하는 boolean 변수가 존재합니다.
- 쓰레드가 start() 된 후 동작하다 interrupt()를 만나 실행하면 interrupted 상태가 true가 됩니다.
- isInterrupted() 메서드를 사용하여 상태 값을 확인할 수 있습니다.
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
while (!Thread.currentThread().isInterrupted()) {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
break;
}
}
System.out.println("task : " + Thread.currentThread().getName());
};
Thread thread = new Thread(task, "Thread");
thread.start();
thread.interrupt();
System.out.println("thread.isInterrupted() = " + thread.isInterrupted());
}
}- !Thread.currentThread().isInterrupted()로 interrupted 상태를 체크해서 처리하면 오류를 방지할 수 있습니다.
- [ sleep 상태에 있는 동안 interrupt()를 만나면 다시 실행되기 때문에 InterruptedException이 발생할 수 있습니다. ]
join()
📌정해진 시간 동안 지정한 쓰레드가 작업하는 것을 기다립니다.
- 시간을 지정하지 않았을 때는 지정한 쓰레드의 작업이 끝날 때까지 기다립니다.
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
try {
Thread.sleep(5000); // 5초
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Thread thread = new Thread(task, "thread");
thread.start();
long start = System.currentTimeMillis();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// thread 의 소요시간인 5000ms 동안 main 쓰레드가 기다렸기 때문에 5000이상이 출력됩니다.
System.out.println("소요시간 = " + (System.currentTimeMillis() - start));
}
}- Thread.sleep(ms); ms(밀리초) 단위로 설정됩니다.
- 예외 처리를 해야 합니다.
- interrupt()를 만나면 기다리는 것을 멈추기 때문에 InterruptedException이 발생할 수 있습니다.
- 시간을 지정하지 않았기 때문에 thread가 작업을 끝낼 때까지 main 쓰레드는 기다리게 됩니다.
yield()
📌 남은 시간을 다음 쓰레드에게 양보하고 쓰레드 자신은 실행 대기 상태가 됩니다.
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
try {
for (int i = 0; i < 10; i++) {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
}
} catch (InterruptedException e) {
Thread.yield();
}
};
Thread thread1 = new Thread(task, "thread1");
Thread thread2 = new Thread(task, "thread2");
thread1.start();
thread2.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread1.interrupt();
}
}
- thread1과 thread2가 같이 1초에 한 번씩 출력
- 5초 뒤에 thread1에서 InterruptedException이 발생
- Thread.yield(); 이 실행
- thread1은 실행 대기 상태로 변경
- 남은 시간은 thread2에게 리소스가 양보됩니다.
synchronized
📌 멀티 쓰레드의 경우 여러 쓰레드가 한 프로세스의 자원을 공유해서 작업하기 때문에 서로에게 영향을 줄 수 있습니다. 이로 인해서 장애나 버그가 발생할 수 있습니다. 이러한 일을 방지하기 위해 한 쓰레드가 진행 중인 작업을 다른 쓰레드가 침범하지 못하도록 막기 위해, 모든 쓰레드는 현재 자원의 상태와 현재 쓰레드가 실행되고 있는지 등의 여부를 동일하게 알고 있어야 합니다. 이 상태 정보를 모두 동일하게 알도록 각 쓰레드가 가진 정보를 통일시키는 것이 '쓰레드 동기화(Synchronization)'라고 합니다.
- 동기화를 하려면 다른 쓰레드의 침범을 막아야 하는 코드들을 ‘임계 영역( 공유 자원에 접근하는 코드 부분)’으로 설정하면 됩니다.
- 임계 영역에는 Lock을 가진 단 하나의 쓰레드만 출입이 가능합니다.
- 즉, 임계 영역은 한 번에 한 쓰레드만 사용이 가능합니다.
1. 메서드 전체를 임계 영역으로 지정합니다.
public synchronized void asyncSum() {
...침범을 막아야하는 코드...
}
2.특정 영역을 임계 영역으로 지정합니다.
synchronized(해당 객체의 참조변수) {
...침범을 막아야하는 코드...
}
public class Main {
public static void main(String[] args) {
AppleStore appleStore = new AppleStore();
Runnable task = () -> {
while (appleStore.getStoredApple() > 0) {
appleStore.eatApple();
System.out.println("남은 사과의 수 = " + appleStore.getStoredApple());
}
};
for (int i = 0; i < 3; i++) {
new Thread(task).start();
}
}
}
class AppleStore {
private int storedApple = 10;
public int getStoredApple() {
return storedApple;
}
public void eatApple() {
synchronized (this) {
if(storedApple > 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
storedApple -= 1;
}
}
}
}- 위 코드는 동기화가 실행되어 있어, 순서대로 사과를 먹지만
- 만약 동기화를 안했다면 남은 사과의 수가 뒤죽박죽 출력될 뿐만 아니라 없는 사과를 먹는 경우도 발생한다 = 오류
wait(), notify()
📌침범을 막은 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니면, wait() 을 호출하여 쓰레드가 Lock을 반납하고 기다리게 할 수 있습니다.
- 그럼 다른 쓰레드가 락을 얻어 해당 객체에 대한 작업을 수행할 수 있게 되고,
- 추후에 작업을 진행할 수 있는 상황이 되면 notify()를 호출해서,
- 작업을 중단했던 쓰레드가 다시 Lock을 얻어 진행할 수 있게 됩니다.
wait()
- 실행 중이던 쓰레드는 해당 객체의 대기실(waiting pool)에서 통지를 기다립니다.
notify()
- 해당 객체의 대기실(waiting pool)에 있는 모든 쓰레드 중에서 임의의 쓰레드만 통지를 받습니다.
- 말 그대로 '알리다' 라는 의미
public class Main {
public static String[] itemList = {
"MacBook", "IPhone", "AirPods", "iMac", "Mac mini"
};
public static AppleStore appleStore = new AppleStore();
public static final int MAX_ITEM = 5;
public static void main(String[] args) {
// 가게 점원
Runnable StoreClerk = () -> {
while (true) {
int randomItem = (int) (Math.random() * MAX_ITEM);
appleStore.restock(itemList[randomItem]);
try {
Thread.sleep(50);
} catch (InterruptedException ignored) {
}
}
};
// 고객
Runnable Customer = () -> {
while (true) {
try {
Thread.sleep(77);
} catch (InterruptedException ignored) {
}
int randomItem = (int) (Math.random() * MAX_ITEM);
appleStore.sale(itemList[randomItem]);
System.out.println(Thread.currentThread().getName() + " Purchase Item " + itemList[randomItem]);
}
};
new Thread(StoreClerk, "StoreClerk").start();
new Thread(Customer, "Customer1").start();
new Thread(Customer, "Customer2").start();
}
}
class AppleStore {
private List<String> inventory = new ArrayList<>();
public void restock(String item) {
synchronized (this) {
while (inventory.size() >= Main.MAX_ITEM) {
System.out.println(Thread.currentThread().getName() + " Waiting!");
try {
wait(); // 재고가 꽉 차있어서 재입고하지 않고 기다리는 중!
Thread.sleep(333);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 재입고
inventory.add(item);
notify(); // 재입고 되었음을 고객에게 알려주기
System.out.println("Inventory 현황: " + inventory.toString());
}
}
public synchronized void sale(String itemName) {
while (inventory.size() == 0) {
System.out.println(Thread.currentThread().getName() + " Waiting!");
try {
wait(); // 재고가 없기 때문에 고객 대기중
Thread.sleep(333);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
while (true) {
// 고객이 주문한 제품이 있는지 확인
for (int i = 0; i < inventory.size(); i++) {
if (itemName.equals(inventory.get(i))) {
inventory.remove(itemName);
notify(); // 제품 하나 팔렸으니 재입고 하라고 알려주기
return; // 메서드 종료
}
}
// 고객이 찾는 제품이 없을 경우
try {
System.out.println(Thread.currentThread().getName() + " Waiting!");
wait();
Thread.sleep(333);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Lock
📌synchronized 블럭으로 동기화하면 자동적으로 Lock이 걸리고 풀리지만, 같은 메서드 내에서만 Lock을 걸 수 있다는 제약이 있습니다. 이런 제약을 해결하기 위해 Lock 클래스를 사용합니다.
- ReentrantLock
- 재진입 가능한 Lock, 가장 일반적인 배타 Lock
- 특정 조건에서 Lock을 풀고, 나중에 다시 Lock을 얻어 임계 영역으로 진입이 가능합니다.
public class MyClass {
private Object lock1 = new Object();
private Object lock2 = new Object();
public void methodA() {
synchronized (lock1) {
methodB();
}
}
public void methodB() {
synchronized (lock2) {
// do something
methodA();
}
}
}- methodA는 lock1을 가지고, methodB는 lock2를 가집니다.
- methodB에서 methodA를 호출하고 있으므로, methodB에서 lock2를 가진 상태에서 methodA를 호출하면 lock1을 가지려고 할 것입니다.
- 그러나 이때, methodA에서 이미 lock1을 가지고 있으므로 lock2를 기다리는 상태가 되어 데드락이 발생할 가능성이 있습니다.
- 하지만 ReentrantLock을 사용하면, 같은 스레드가 이미 락을 가지고 있더라도 락을 유지하며 계속 실행할 수 있기 때문에 데드락이 발생하지 않습니다.
- 즉, ReentrantLock을 사용하면 코드의 유연성을 높일 수 있습니다.
- ReentrantReadWriteLock
- 읽기를 위한 Lock과 쓰기를 위한 Lock을 따로 제공합니다.
- 읽기에는 공유적이고, 쓰기에는 베타적인 Lock입니다.
- 읽기 Lock이 걸려있으면 다른 쓰레드들도 읽기 Lock을 중복으로 걸고 읽기를 수행할 수 있습니다. (read-only)
- 읽기 Lock이 걸려있는 상태에서 쓰기 Lock을 거는 것은 허용되지 않습니다. (데이터 변경 방지)
- StampedLock
- ReentrantReadWriteLock에 낙관적인 Lock의 기능을 추가했습니다.
- 낙관적인 Lock : 데이터를 변경하기 전에 락을 걸지 않는 것을 말합니다. 낙관적인 락은 데이터 변경을 할 때 충돌이 일어날 가능성이 적은 상황에서 사용합니다.
- 낙관적인 락을 사용하면 읽기와 쓰기 작업 모두가 빠르게 처리됩니다. 쓰기 작업이 발생했을 때 데이터가 이미 변경된 경우 다시 읽기 작업을 수행하여 새로운 값을 읽어들이고, 변경 작업을 다시 수행합니다. 이러한 방식으로 쓰기 작업이 빈번하지 않은 경우에는 낙관적인 락을 사용하여 더 빠른 처리가 가능합니다.
- 낙관적인 읽기 Lock은 쓰기 Lock에 의해 바로 해제 가능합니다.
- 무조건 읽기 Lock을 걸지 않고, 쓰기와 읽기가 충돌할 때만 쓰기 후 읽기 Lock을 겁니다.
- ReentrantReadWriteLock에 낙관적인 Lock의 기능을 추가했습니다.
Condition
📌 wait()와 notify()는 몇 가지 문제점을 가지고 있습니다. 그 중 하나가 **"대기 중인 쓰레드를 구분할 수 없다"**는 점입니다. 이를 해결한 것이 Condition 인터페이스입니다.
[추가 설명]
wait()과 notify()는 객체에 대한 모니터링 락(lock)을 이용하여 스레드를 대기시키고 깨웁니다. 그러나 wait()과 notify()는 waiting pool 내에 대기 중인 스레드를 구분하지 못하므로, 특정 조건을 만족하는 스레드만 깨우기가 어렵습니다.
이러한 문제를 해결하기 위해 JDK 5에서는 java.util.concurrent.locks 패키지에서 Condition 인터페이스를 제공합니다. Condition은 waiting pool 내의 스레드를 분리하여 특정 조건이 만족될 때만 깨우도록 할 수 있으며, ReentrantLock 클래스와 함께 사용됩니다. 따라서 Condition을 사용하면 wait()과 notify()의 문제점을 보완할 수 있습니다.
- 좀 더 자세히 설명드리겠습니다.wait()와 notify()는 동기화된 객체의 모니터에서 사용되며, 주로 다음과 같은 동작을 합니다:
- wait(): 쓰레드를 대기 상태로 전환하고, 다른 쓰레드가 notify()나 notifyAll()을 호출할 때까지 대기합니다.
- notify(): 대기 중인 쓰레드 중 하나를 깨워서 실행하도록 합니다.
- notifyAll(): 대기 중인 모든 쓰레드를 깨웁니다.
2. Condition 인터페이스
- **Condition**은 **Lock**과 함께 사용되며, Object 클래스의 메서드인 wait(), notify(), notifyAll() 대신에 사용할 수 있습니다.
3. Condition의 장점
- 다양한 조건을 처리할 수 있다: 여러 조건을 갖는 대기 상태를 만들고, 조건에 맞는 쓰레드만 깨울 수 있습니다.
- 대기 중인 쓰레드를 구분할 수 있다: Condition을 사용하면 notify()와 notifyAll() 대신에 조건을 명시적으로 확인하고, 원하는 쓰레드만 깨울 수 있습니다.
4. Condition 사용 예시
- Condition을 사용하여 wait()와 notify()의 문제를 해결하는 방법은 다음과 같습니다:
- Condition은 java.util.concurrent.locks 패키지에 있는 고급 동기화 기능입니다. Condition을 사용하면 wait()와 notify()에서 발생하는 문제를 해결할 수 있습니다. 특히, 대기 중인 쓰레드를 구분하고 특정 조건을 만족하는 쓰레드만 깨어나게 할 수 있는 기능을 제공합니다.
- 이런 상황은 특정 조건에 맞는 쓰레드만 깨어나야 하는 경우에 문제가 됩니다.
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ConditionExample {
private static int count = 0;
private static Lock lock = new ReentrantLock();
private static Condition condition = lock.newCondition();
public static void main(String[] args) throws InterruptedException {
// 쓰레드 1
Thread thread1 = new Thread(() -> {
lock.lock();
try {
while (count <= 0) {
condition.await(); // count가 0보다 클 때까지 대기
}
System.out.println("Thread 1: count is " + count);
count--;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
});
// 쓰레드 2
Thread thread2 = new Thread(() -> {
lock.lock();
try {
System.out.println("Thread 2: incrementing count");
count++;
condition.signal(); // 대기 중인 쓰레드를 하나 깨운다.
} finally {
lock.unlock();
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}
}
5. Condition 메서드
Condition은 다음과 같은 주요 메서드를 제공합니다:
- await(): 쓰레드를 대기 상태로 전환합니다. wait()와 유사하지만 Condition에서는 대기 상태에 진입하기 전에 명시적으로 Lock을 획득해야 합니다.
- signal(): 대기 중인 쓰레드 중 하나를 깨웁니다. notify()와 유사합니다.
- signalAll(): 대기 중인 모든 쓰레드를 깨웁니다. notifyAll()과 유사합니다.
6. 결론
- wait()와 notify()는 쓰레드 간 통신에 유용하지만, 대기 중인 쓰레드를 구분할 수 없다는 한계가 있습니다.
- 이를 해결한 것이 **Condition**입니다. Condition을 사용하면 대기 중인 쓰레드를 구분하고 조건에 맞는 쓰레드만 깨어나게 할 수 있습니다.
- **Condition**은 Lock 객체와 함께 사용되며, 복잡한 동기화 문제를 해결하는 데 강력한 도구가 됩니다.
'Back-End (Web) > JAVA' 카테고리의 다른 글
| [JAVA] 응용 정리 (1) | 2024.11.15 |
|---|---|
| [JAVA] NULL (0) | 2024.11.13 |
| [JAVA] Generic (3) | 2024.11.12 |
| [JAVA] 오류 및 예외에 대한 이해 (1) | 2024.11.12 |
| [JAVA] 인터페이스 (2) | 2024.11.12 |