DBMS(Database Management System)
📌 데이터베이스를 생성, 관리, 유지보수, 운영하기 위한 소프트웨어입니다. 사용자는 DBMS를 통해 데이터를 효율적으로 저장, 검색, 수정, 삭제하며, 데이터의 일관성과 무결성을 유지할 수 있습니다.
- 데이터베이스 구조를 정의할 수 있는 기능을 제공한다.
DBMS의 역할
- 데이터 관리
- 데이터를 물리적으로 저장하고, 관리하는 역할을 수행한다.
- 데이터를 저장하기 위한 최적화된 구조와 파일 시스템을 관리합니다.
- 사용자가 데이터를 다룰 수 있도록 쿼리 언어(SQL)을 제공한다.
- 데이터 보안
- 사용자 권한 관리, 암호화, 감사 로그 등을 통해 데이터를 보호한다.
- 트랜잭션 관리
- DBMS는 여러 사용자가 동시에 데이터에 접근할 때, 데이터의 일관성을 유지하기 위한 트랜잭션 관리 기능을 제공한다.
- ACID 속성 보장
- Atomicity: 트랜잭션의 모든 작업이 성공적으로 완료되거나, 실패 시 모든 작업이 롤백
- Consistency: 트랜잭션이 데이터베이스를 일관된 상태로 유지
- Isolation: 동시에 실행되는 트랜잭션 간의 영향을 최소화
- Durability: 트랜잭션이 완료된 후 데이터의 변경 사항은 영구적으로 저장
- 백업 및 복구
- DBMS는 데이터 손실에 대비해 백업 및 복구 기능을 제공한다.
- 정기적인 백업을 통해 데이터를 보호하며, 장애 발생 시 데이터 복구가 가능하다.
- 동시성 제어
- 다수의 사용자가 동시에 데이터베이스에 접근하더라도 데이터 일관성이 유지되도록 동시성 제어를 제공한다. 이를 통해 충돌이나 데이터 불일치를 방지할 수 있다.

DBMS의 주요 기능
| 데이터 정의 (DDL) | 데이터베이스 구조(스키마) 정의. 테이블 생성, 수정, 삭제 등을 처리. |
| 데이터 조작 (DML) | 데이터를 추가, 검색, 수정, 삭제. |
| 데이터 제어 (DCL) | 데이터 접근 권한 및 제어. |
| 트랜잭션 관리 (TCL) | 데이터베이스의 일관성과 무결성을 보장하기 위해 트랜잭션을 관리. |
DBMS의 구조
a. 사용자:
- 데이터베이스와 상호작용하는 최종 사용자.
- 애플리케이션, 관리자, 또는 일반 사용자가 포함.
b. DBMS:
- 데이터베이스를 관리하고 사용자 요청을 처리하는 소프트웨어.
c. 데이터베이스:
- 데이터가 실제로 저장되는 영역.
DBMS의 종류
a. 관계형 데이터베이스 관리 시스템 (RDBMS)
- 가장 많이 사용하는 데이터베이스
- 데이터를 테이블 형태로 저장.
- 테이블 간 관계를 키(Foreign Key)로 정의.
- SQL(Structured Query Language)을 사용.
- 예시: MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server.
b. 비관계형 데이터베이스 관리 시스템 (NoSQL DBMS)
- 테이블이 아닌 key-value, document, graph 등의 다양한 형태로 데이터를 저장하고 관리한다.
- 스키마가 고정되지 않고, 대규모 데이터 처리와 높은 확장성을 제공한다.
- 예시: MongoDB, Cassandra, Redis, Neo4j.
c. 분산 데이터베이스 관리 시스템
- 데이터가 여러 노드에 분산되어 저장.
- 대규모 데이터를 처리하기 위한 시스템.
- 예시: Amazon DynamoDB, Google Bigtable.
d. 클라우드 기반 DBMS
- 클라우드 환경에서 데이터베이스를 관리.
- 유연성과 확장성이 높음.
- 예시: AWS RDS, Google Cloud SQL, Azure SQL Database.
DBMS의 구성 요소
| 구성 요소 | 설명 |
| 데이터베이스 엔진 | 데이터 저장, 검색, 수정, 삭제 등의 핵심 작업 수행. |
| 스키마 | 데이터베이스 구조 정의. |
| 질의 처리기 | SQL 질의를 처리하고 결과 반환. |
| 트랜잭션 관리자 | 데이터 무결성과 일관성을 유지하며 트랜잭션 관리. |
| 보안 관리자 | 데이터 접근 제어 및 권한 관리. |
| 백업 및 복구 관리자 | 데이터 손실 방지 및 복구 작업 수행. |
DBMS와 파일 시스템의 차이점
| DBMS | 파일 시스템 | |
| 데이터 중복 제거 | 데이터 중복을 최소화 (정규화). | 데이터 중복 가능성이 높음. |
| 데이터 무결성 | 무결성 제약 조건으로 데이터의 일관성 유지. | 무결성 관리가 어렵고 사용자에 의존. |
| 보안성 | 접근 제어와 인증을 통한 강력한 보안 제공. | 파일 수준의 제한적 보안. |
| 트랜잭션 관리 | ACID 속성을 통해 트랜잭션 처리. | 트랜잭션 관리 기능이 없음. |
| 검색 속도 | 인덱싱 등으로 고속 데이터 검색 가능. | 검색 속도가 느림. |
주요 DBMS 예시
| DBMS | 설명 |
| MySQL | 오픈 소스 관계형 DBMS, 높은 성능과 안정성 제공. |
| PostgreSQL | 고급 기능과 표준 준수를 중시하는 오픈 소스 RDBMS. |
| Oracle | 대기업에서 널리 사용되는 상용 관계형 DBMS. |
| MongoDB | 문서 기반의 NoSQL DBMS. |
| Redis | 키-값 기반의 인메모리 데이터베이스, 빠른 속도를 제공. |
트랜잭션(Transaction)
📌 데이터베이스 관리에서 논리적으로 하나의 작업 단위를 의미합니다.
- 트랜잭션은 여러 작업(쿼리)이 하나의 단위로 묶여 모두 성공하거나, 모두 실패하는 특성을 가집니다.


트랜잭션의 예
a. 은행 계좌 이체 예제
- A 계좌에서 100원을 출금 → B 계좌에 100원을 입금.
- 두 작업은 하나의 트랜잭션으로 묶여야 함.
1. 트랜잭션 성공
- A 계좌에서 100원 차감.
- B 계좌에 100원 추가.
- Commit: 두 작업 모두 성공 → 데이터베이스에 반영.
2. 트랜잭션 실패
- A 계좌에서 100원 차감.
- B 계좌에 입금 실패.
- Rollback: 두 작업 모두 취소 → A 계좌의 100원 복원.
트랜잭션의 특징: ACID
트랜잭션은 데이터의 안정성과 무결성을 보장하기 위해 ACID 특성을 만족해야 합니다.
| Atomicity (원자성) | 트랜잭션의 모든 작업이 모두 성공하거나 모두 실패해야 함. |
| Consistency (일관성) | 트랜잭션 전후 데이터베이스의 상태가 일관성을 유지해야 함. |
| Isolation (고립성) | 동시에 실행되는 트랜잭션이 서로 간섭하지 않도록 독립적으로 실행됨을 보장. |
| Durability (지속성) | 트랜잭션이 성공적으로 완료되면, 그 결과는 영구적으로 반영되어야 함. |
트랜잭션의 생명주기
- Begin:
- 트랜잭션 시작.
- Execute:
- 트랜잭션 내 작업(쿼리) 실행.
- Commit:
- 트랜잭션 성공 → 작업 내용을 데이터베이스에 반영.
- Rollback:
- 트랜잭션 실패 → 작업 내용을 데이터베이스에서 취소.
트랜잭션 격리 수준 (Isolation Level)
트랜잭션 간의 간섭을 최소화하기 위해 격리 수준을 설정합니다.
Spring에서는 @Transactional의 isolation 속성을 사용해 설정합니다.
| 격리 수준 | 설명 |
| READ_UNCOMMITTED | 다른 트랜잭션의 미완료 데이터를 읽을 수 있음. (Dirty Read 허용) |
| READ_COMMITTED | 다른 트랜잭션이 Commit한 데이터만 읽을 수 있음. (기본값) |
| REPEATABLE_READ | 트랜잭션 내에서 같은 데이터를 여러 번 읽을 때 항상 동일한 값 반환. |
| SERIALIZABLE | 가장 높은 격리 수준. 트랜잭션이 순차적으로 실행되며 교차 작업 불가. |
Spring에서 트랜잭션 관리
Spring은 트랜잭션 관리를 위한 간단하고 강력한 기능을 제공합니다.
주로 @Transactional 어노테이션을 사용합니다.
a. 기본 사용법
@Service
public class BankService {
private final AccountRepository accountRepository;
public BankService(AccountRepository accountRepository) {
this.accountRepository = accountRepository;
}
@Transactional
public void transferMoney(Long fromAccountId, Long toAccountId, int amount) {
Account fromAccount = accountRepository.findById(fromAccountId).orElseThrow();
Account toAccount = accountRepository.findById(toAccountId).orElseThrow();
fromAccount.withdraw(amount); // 출금
toAccount.deposit(amount); // 입금
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
}
}@Transactional:
- 메서드 내의 모든 작업이 하나의 트랜잭션으로 처리.
- 하나라도 실패하면 Rollback.
Rollback 처리
Spring에서 특정 예외 발생 시 트랜잭션을 Rollback합니다.
예외 처리 예제
@Transactional(rollbackFor = CustomException.class)
public void processTransaction() throws CustomException {
// 작업 실행
if (errorCondition) {
throw new CustomException("Error occurred");
}
// 다른 작업 실행
}- rollbackFor: 특정 예외 발생 시 Rollback 설정.
- 기본적으로 RuntimeException이나 Error가 발생하면 Rollback.
관계형 데이터베이스 ( RDB )
📌 데이터를 테이블(Table) 형태로 저장하고, 관계(Relationship)를 통해 데이터를 연결하여 관리하는 데이터베이스입니다. 관계형 모델을 기반으로 설계되었으며, 데이터를 행(Row)과 열(Column)의 구조로 저장합니다.
- RDB는 주로 **SQL(Structured Query Language)**을 사용하여 데이터를 정의, 관리, 검색합니다.
RDB 설계 시 주요 개념
a. 정규화(Normalization)
- 데이터 중복을 최소화하고 데이터 구조를 최적화.
b. 비정규화(Denormalization)
- 성능 향상을 위해 일부 데이터 중복 허용.
c. 키(Key)
- Primary Key: 테이블의 각 행을 고유하게 식별.
- Foreign Key: 다른 테이블의 Primary Key를 참조.
d. 인덱스(Index)
- 데이터 검색 속도를 향상시키는 구조.
e. 뷰(View)
- 실제 데이터 없이 쿼리 결과를 저장하는 가상 테이블.
RDBMS와의 관계
**RDB(Relational Database)**는 관계형 데이터 모델을 기반으로 설계된 데이터베이스이며, 이를 관리하는 소프트웨어를 **RDBMS(Relational Database Management System)**라고 합니다.
| RDB | 관계형 데이터 모델에 따라 설계된 데이터베이스. |
| RDBMS | RDB를 생성, 관리, 유지보수하는 소프트웨어 시스템. |
| SQL | RDB와 RDBMS에서 데이터를 처리하기 위해 사용하는 언어. |
RDB의 데이터 모델
a. 1:1 관계
- 한 테이블의 행이 다른 테이블의 행과 1:1로 매핑.
- 예: 사람(Person) ↔ 여권(Passport)
b. 1:N 관계
- 한 테이블의 행이 다른 테이블의 여러 행과 매핑.
- 예: 사용자(User) ↔ 주문(Order)
c. N:M 관계
- 두 테이블의 여러 행이 서로 다수의 행과 매핑.
- 예: 학생(Student) ↔ 수업(Class)
+ 해결 방법: 중간 테이블(Join Table) 사용.
- 학생(Student) ↔ 수강 기록(Student_Class) ↔ 수업(Class)
관계형 데이터베이스 특징
테이블 (Table)


- RDBMS에서 데이터는 테이블이라는 구조에 저장되며 행(row)과 열(column)로 구성된다.
- 열(column)은 데이터의 속성(유일한 이름)을 나타내고 타입(데이터 유형)을 가진다.
- 행(row)은 관계된 데이터의 묶음을 의미하고 tuple 또는 record라고 한다.
- 데이터 무결성
- 테이블은 특정 규칙과 제약 조건(기본 키, 외래 키, 유니크 등)을 통해 데이터를 저장함으로써 데이터의 무결성(정확성, 일관성, 유효성)을 유지한다.
관계 (Relationships)

- 테이블 간의 관계는 외래 키(Foreign Key)를 통해 설정된다.
- RDBMS는 다양한 유형의 관계를 지원한다.
- 1:1 관계: 한 테이블의 한 행이 다른 테이블의 한 행과만 연결된다.
- 1:다 관계: 한 테이블의 한 행이 다른 테이블의 여러 행과 연결된다.(위 예시와 같음)
- 다:다 관계: 두 테이블의 여러 행이 서로 연결될 수 있다.
SQL (Structured Query Language)
- RDBMS에서 데이터를 정의하고, 관리하기 위한 표준 언어이다.
- 데이터를 생성(Create), 읽기(Read), 갱신(Update), 삭제(Delete)하는 작업을 수행한다.
키 (Keys)

- 기본 키(Primary Key)
- 테이블 내에서 각 행을 고유하게 식별하는 열 또는 열의 조합이다.
- 기본 키는 중복되지 않으며, NULL 값을 가질 수 없다.
- 외래 키(Foreign Key)
- 한 테이블의 열이 다른 테이블의 기본 키를 참조하여 두 테이블 간의 관계를 설정하는 데 사용된다.
- 테이블 간의 데이터 무결성을 유지할 수 있다.
- 유일 키(Unique Key)
- 기본 키와 유사하지만, 하나의 테이블에서 여러 개가 존재할 수 있다.
- 중복된 값을 허용하지 않지만, NULL 값은 허용할 수 있다.
트랜잭션(Transaction)
- RDBMS는 트랜잭션이라는 단위를 통해 데이터베이스 작업을 처리하며, 이를 통해 데이터의 일관성과 무결성을 유지한다.
- 트랜잭션은 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)이라는 ACID 속성을 따른다.
- Atomicity: 트랜잭션의 모든 작업이 성공적으로 완료되거나, 실패 시 모든 작업이 롤백
- Consistency: 트랜잭션이 데이터베이스를 일관된 상태로 유지
- Isolation: 동시에 실행되는 트랜잭션 간의 영향을 최소화
- Durability: 트랜잭션이 완료된 후 데이터의 변경 사항은 영구적으로 저장
정규화 (Normalization)

- 데이터의 중복을 줄이고, 일관성과 무결성을 유지하기 위해 데이터를 구조화하는 프로세스이다.
- 여러가지 정규화 단계가 있으며, 각 단계는 데이터 중복을 줄이고 이상 현상을 방지하는 데 목적이 있다.
데이터 무결성 (Data Integrity)
- 엔터티 무결성
- 각 테이블의 기본 키(PK)가 중복되지 않고 NULL 값이 아닌 상태를 유지한다.
- 참조 무결성
- 외래 키(FK)를 통해 참조되는 데이터가 유효성을 유지하도록 보장한다.
- 도메인 무결성
- 각 열이 정의된 데이터 타입과 제약 조건에 따라 유효한 값을 유지하도록 한다.
인덱스 (Index)
- 특정 열의 검색 성능을 향상시키기 위해 사용된다.
- 인덱스는 테이블의 데이터를 정렬하고, 효율적으로 접근할 수 있도록 지원한다.
- 인덱스가 많아지면 삽입 및 수정 작업의 성능에 영향을 미칠 수 있다.
RDBMS
📌 관계형 데이터베이스 RDB(Relational DataBase)를 관리할 수 있는 소프트웨어로 데이터를 테이블 형식으로 관리한다. RDBMS는 데이터 간의 관계를 정의하고, 이러한 관계를 바탕으로 복잡한 Query를 실행할 수 있는 기능을 제공한다.
- RDBMS는 관계형 모델을 기반으로 데이터의 일관성, 무결성, 동시성을 보장합니다.
RDBMS의 특징
- 테이블 기반:
- 데이터를 행(Row)과 열(Column)로 구성된 테이블에 저장.
- 테이블은 데이터베이스 내에서 독립적으로 관리.
- SQL 사용:
- 데이터를 관리하기 위해 SQL(Structured Query Language) 사용.
- 키(Key)와 관계(Relationship):
- 기본 키(Primary Key)와 외래 키(Foreign Key)를 통해 데이터 무결성 및 테이블 간 관계를 관리.
- 데이터 무결성:
- 데이터가 정확하고 일관되도록 보장.
- 트랜잭션 지원:
- 트랜잭션을 통해 작업의 원자성, 일관성, 고립성, 지속성을 보장 (ACID 특성).
RDBMS의 구성 요소
a. 테이블 (Table)
- 데이터 저장 구조.
- 행(Row)과 열(Column)로 구성.
- 각 열은 속성(Attribute), 각 행은 레코드(Record).
b. 열(Column)
- 테이블의 필드(Field).
- 데이터의 유형과 속성을 정의.
c. 행(Row)
- 각 행은 데이터의 한 개체(Entity)를 나타냄.
d. 기본 키 (Primary Key)
- 테이블의 각 행을 고유하게 식별하는 열.
e. 외래 키 (Foreign Key)
- 다른 테이블의 기본 키를 참조하여 테이블 간 관계를 정의.
f. 인덱스 (Index)
- 데이터 검색 속도를 높이기 위해 사용하는 구조.
주요 RDBMS 예시
| RDBMS | 특징 |
| MySQL | 오픈 소스 RDBMS, 높은 성능과 안정성 제공. |
| PostgreSQL | 오픈 소스 RDBMS, 고급 기능과 확장성 제공. |
| Oracle Database | 상용 RDBMS, 대규모 데이터 처리와 강력한 보안 제공. |
| Microsoft SQL Server | Microsoft에서 제공하는 상용 RDBMS, 윈도우 환경에 최적화. |
| SQLite | 경량형 RDBMS, 모바일 및 임베디드 환경에 적합. |
RDBMS와 NoSQL 비교
| RDBMS | NoSQL | |
| 데이터 구조 | 테이블 (행과 열) | 문서, 키-값, 컬럼, 그래프 등 다양한 형태. |
| 스키마 | 고정 스키마 필요 | 스키마 유연. |
| 데이터 관계 | 기본 키와 외래 키로 관계 정의 | 관계를 덜 중요시하거나 애플리케이션에서 관리. |
| 확장성 | 수직 확장에 적합 | 수평 확장에 적합. |
| 사용 사례 | 금융, ERP, CRM 등 일관성과 무결성이 중요한 애플리케이션 | 소셜 네트워크, IoT, 대규모 데이터 처리. |
SQL(Structured Query Language)
📌 관계형 데이터베이스 관리 시스템(RDBMS)에서 데이터를 정의, 조작, 제어, 조회하기 위해 사용되는 표준 프로그래밍 언어이다.
SQL 특징
- 관계형 데이터베이스와의 상호작용을 표준화하고 효율적으로 수행할 수 있게 해준다.
- 데이터베이스에서 원하는 정보를 추출하고 분석할 수 있게 해준다.
- 대부분의 RDBMS(MySQL, PostgreSQL, Oracle 등)가 SQL을 지원한다.
- 주의! 표준 SQL은 존재하지만, 제품마다 조금씩의 차이(함수명)가 존재한다.
- SQL 명령문은 대소문자를 구분하지 않고, 대문자로 사용하면 가독성이 향상되어 오타를 방지한다.
SQL 종류

DDL(Data Definition Language)
- 데이터베이스 구조를 정의하는 데 사용된다.
- CREATE
- 새로운 데이터베이스 및 테이블을 생성한다.
- ALTER
- 기존 데이터베이스 및 테이블 구조를 수정한다.
- DROP
- 데이터베이스 및 테이블을 삭제한다.

DML(Data Manipulation Language)
- 데이터베이스의 데이터를 조작하는 데 사용된다.
- INSERT
- 데이터를 테이블에 삽입한다.
- UPDATE
- 테이블의 기존 데이터를 수정한다.
- DELETE
- 테이블의 데이터를 삭제한다.

DQL(Data Query Language)
- 데이터베이스에서 데이터를 검색하는 데 사용된다.
- SELECT
- 데이터를 조회한다. 특정 조건을 추가할 수 있다.
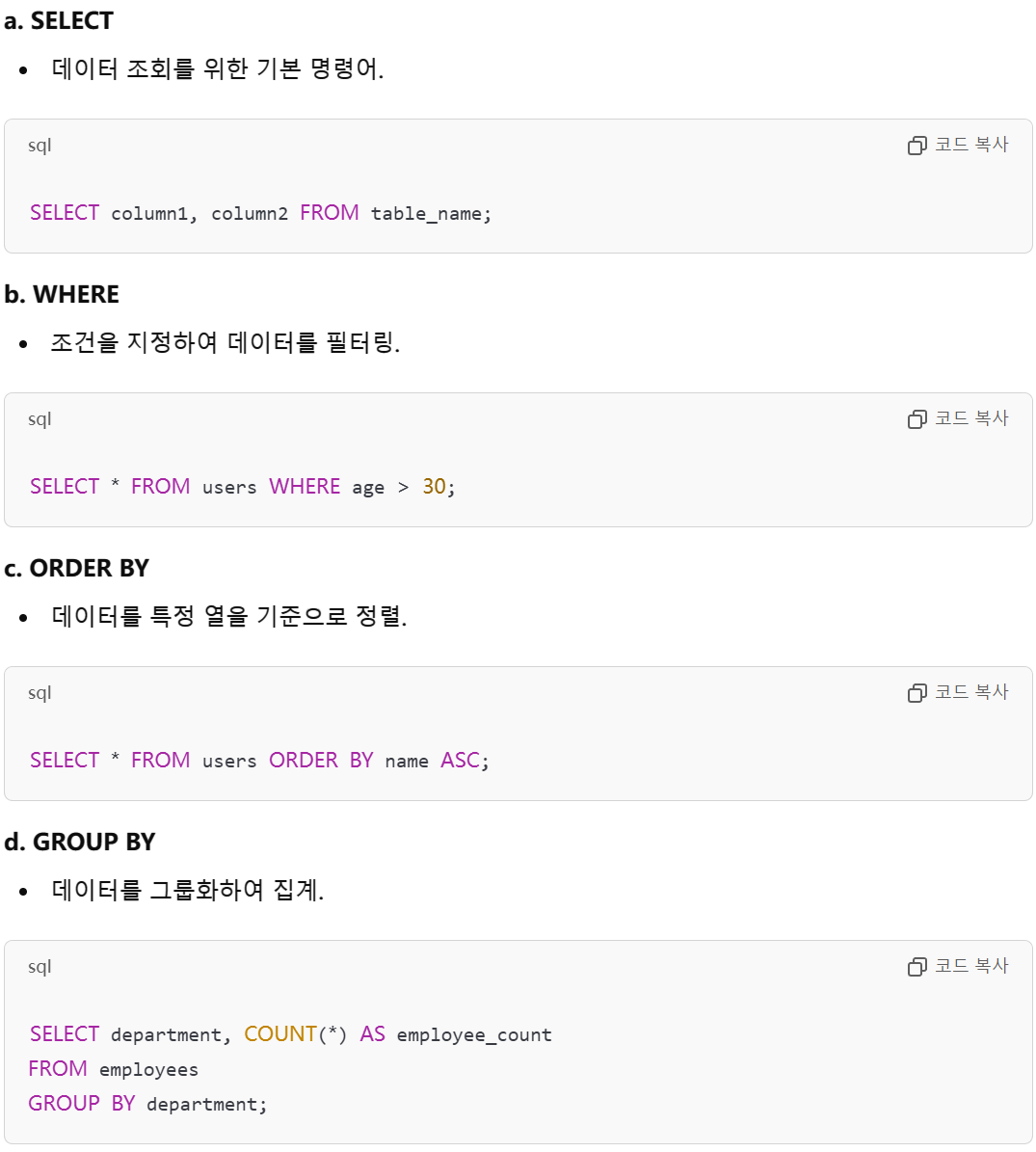

DCL(Data Control Language)
- 데이터베이스의 권한을 관리하는 데 사용된다.
- GRANT
- 사용자에게 권한을 부여한다.
- REVOKE
- 사용자의 권한을 회수한다.

TCL(Transaction Control Language)
- 여러 DML 작업을 하나의 논리적 단위로 묶어 트랜잭션으로 처리하는 데 사용된다.
- COMMIT
- 트랜잭션이 성공한 것을 데이터베이스에 알리고 모든 변경 사항을 영구적으로 저장한다.
- ROLLBACK
- 트랜잭션 중 발생한 모든 변경 사항을 취소하고, 데이터베이스를 트랜잭션 시작 시점의 상태로 되돌린다.

SQL의 주요 개념
a. 키(Key)
- Primary Key (기본 키):
- 테이블에서 각 행(row)을 고유하게 식별하는 하나 이상의 열(column)에 설정되는 제약조건
- 중복된 데이터가 테이블에 삽입되는 것을 방지한다.
- 테이블에서 각 행(row)을 고유하게 식별하는 하나 이상의 열(column)에 설정되는 제약조건
- NOT NULL과 UNIQUE 제약 조건의 특징을 모두 가진다.
- INDEX로 설정되어 테이블의 데이터를 쉽고 빠르게 찾도록 도와주는 역할을 한다.
- 추가적인 쓰기 작업과 저장 공간을 활용하여 검색 속도를 향상시키기 위한 자료구조
- INDEX로 설정되어 테이블의 데이터를 쉽고 빠르게 찾도록 도와주는 역할을 한다.
CREATE TABLE students (
id BIGINT PRIMARY KEY, -- 학생 고유 번호 (자동 증가)
name VARCHAR(50) NOT NULL, -- 이름
email VARCHAR(100) NOT NULL UNIQUE, -- 이메일
PRIMARY KEY (id) -- PRIMARY KEY 설정
);-
- Foreign Key (외래 키):
- 한 테이블의 열이 다른 테이블의 PRIMARY KEY(또는 UNIQUE 제약 조건이 적용된 열)를 참조하도록 설정한다.
- 참조된 테이블의 데이터가 변경되거나 삭제될 때 참조 무결성을 강제할 수 있다.
- 외래 키 값은 반드시 참조하는 테이블의 기본 키로 존재해야 한다.
- 부모 테이블의 데이터가 변경되거나 삭제될 때 자식 테이블에 있는 데이터도 자동으로 업데이트되거나 삭제되도록 보장한다.(CASCADE)
- 참조된 테이블의 데이터가 변경되거나 삭제될 때 참조 무결성을 강제할 수 있다.
- 다른 테이블의 Primary Key를 참조.
- 테이블 간 관계를 정의.
- 한 테이블의 열이 다른 테이블의 PRIMARY KEY(또는 UNIQUE 제약 조건이 적용된 열)를 참조하도록 설정한다.
CREATE TABLE 테이블이름
(
필드이름 필드타입,
...
FOREIGN KEY(필드이름)
REFERENCES 테이블이름(필드이름)
);


- CASCADE
- 참조 무결성을 유지하기 위한 동작을 정의하는 규칙
- 외래 키(Foreign Key) 제약 조건과 관련된 변경 사항이 발생할 때 참조하는 레코드에 대한 동작을 자동으로 처리하는 기능
- FOREIGN KEY 로 연관된 데이터를 삭제,변경할 수 있다.
CREATE TABLE 테이블이름
(
필드이름 필드타입,
...
FOREIGN KEY(필드이름)
REFERENCES 테이블이름(필드이름) ON DELETE CASCADE
//ON UPDATE CASCADE
);
1. `ON DELETE CASCADE`
- 부모 테이블의 행이 삭제되면, 참조하는 자식 테이블의 관련 행들도 자동으로 삭제한다.
2. `ON UPDATE CASCADE`
- 부모 테이블의 기본 키가 업데이트되면, 참조하는 자식 테이블의 외래 키 값도 자동으로 수정된다.- DEFAULT
- 해당 필드의 기본 값을 설정한다.
- 필드 값이 전달되지 않으면, 자동으로 기본 값을 저장한다.
CREATE TABLE 테이블이름
(
필드이름 필드타입 DEFAULT 값
);- Unique Key:
- 중복되지 않는 고유한 값을 유지.
b. 제약 조건(Constraints)
- 데이터 무결성을 유지하기 위한 규칙.
- AUTO_INCREMENT : 고유번호 자동생성(컬럼의 값이 중복되지 않게 1씩 자동으로 증가)
- NOT NULL: NULL 값 불가.
- UNIQUE: 중복 값 불가.
- CHECK: 특정 조건 만족.
- DEFAULT: 기본값 설정.
- FOREIGN KEY: 테이블 간 관계 설정.
-- users 테이블 생성
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY, -- 고유번호 자동생성 (Primary Key 포함)
name VARCHAR(100) NOT NULL, -- 이름은 NULL 값 불가
email VARCHAR(100) UNIQUE NOT NULL, -- 이메일은 중복 불가 및 NULL 값 불가
age INT CHECK (age >= 18), -- 나이는 18세 이상이어야 함
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 기본값으로 현재 시간 설정
);
-- orders 테이블 생성
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY, -- 고유번호 자동생성 (Primary Key 포함)
user_id INT NOT NULL, -- 사용자 ID (외래 키)
amount DECIMAL(10, 2) CHECK (amount > 0),-- 금액은 0보다 커야 함
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 주문 날짜 기본값
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE -- users 테이블과 관계 설정, 사용자 삭제 시 주문도 삭제
);- 데이터 무결성
- 데이터의 정확성, 일관성, 완전성을 유지하는 것
- 정확성: 데이터가 올바르고 오류 없이 저장되는 것을 의미한다.
- 일관성: 데이터가 서로 모순되지 않고 조화를 이루는 상태를 유지하는 것을 의미한다.
- 완전성: 필요한 모든 데이터가 빠짐없이 저장되고 관리되는 것을 의미한다.
- 즉, 데이터가 입력, 저장, 전송, 처리되는 동안 변경되거나 손상되지 않도록 보장하는 개념
- 데이터의 정확성, 일관성, 완전성을 유지하는 것
c. JOIN
- 두개 이상의 테이블을 연결하여 데이터를 검색하는 방법
- 테이블을 분리하여 데이터 중복을 최소화하고 데이터의 일관성을 유지하기 위해 사용된다.
- JOIN 종류
- 여러 테이블의 데이터를 결합하여 조회.

- INNER JOIN
- 두 테이블에서 공통된 값을 가지고 있는 행만 반환한다.
- ON 절의 조건이 일치하는 결과
- MySQL에서는 JOIN, INNER JOIN, CROSS JOIN이 모두 같은 의미이다.
- 교집합
- 두 테이블에서 공통된 값을 가지고 있는 행만 반환한다.
- LEFT JOIN
- 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환한다.
- ON 절의 조건 중 첫번째 테이블인 왼쪽(기준)의 데이터를 모두 가져온다.
- 오른쪽 테이블에 일치하는 데이터가 없으면 NULL로 반환한다.
- JOIN을 여러번 사용하는 경우 LEFT JOIN으로 시작했다면 이후 JOIN도 LEFT JOIN으로 해야한다.
- 부분 집합(왼쪽 테이블)
- 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환한다.
- RIGHT JOIN
- 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행을 반환한다.
- ON 절의 조건 중 두번째 테이블인 오른쪽(기준)의 데이터를 모두 가져온다.
- 왼쪽 테이블에 일치하는 데이터가 없으면 NULL로 반환한다.
- 부분 집합(오른쪽 테이블)
- 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행을 반환한다.
- OUTER JOIN
- 두 테이블에서 공통된 값을 가지지 않는 행도 포함해서 반환한다.
- 합집합
- LEFT OUTTER JOIN, RIGHT OUTTER JOIN, FULL OUTTER JOIN(잘 사용하지 않음) 이 있다.
- 대부분의 DB는 FULL OUTTER JOIN을 지원하지 않고 UNION을 사용하도록 한다.
- UNION을 사용하면 자동으로 중복을 제거(DISTICT)해준다.

📌
📌
📌
📌
📌
📌
📌
📌
📌
📌
📌
📌
📌
🐳
🐳
🐳
소제목
🧩 부모 타입 변수 = 자식 타입 객체; 는 자동으로 부모 타입으로 변환이 일어납니다.
소제목
🎵 클래스가 설계도라면 추상 클래스는 미완성된 설계도입니다.